前言
在(文本挖掘的分词原理)中,我们讲到了文本挖掘的预处理的关键一步:“分词”,而在做了分词后,如果我们是做文本分类聚类,则后面关键的特征预处理步骤有向量化或向量化的特例Hash Trick,本文我们就对向量化和特例Hash Trick预处理方法做一个总结。
词袋模型
在讲向量化与Hash Trick之前,我们先说说词袋模型(Bag of Words,简称BoW)。词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。向量化完毕后一般也会使用TF-IDF进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习算法进行分类聚类了。
词袋模型的三部曲:
- 分词(tokenizing);
- 统计修订词特征值(counting);
- 标准化(normalizing);
与词袋模型非常类似的一个模型是词集模型(Set of Words,简称SoW),和词袋模型***的不同是它仅仅考虑词是否在文本中出现,而不考虑词频。也就是一个词在文本在文本中出现1次和多次特征处理是一样的。在大多数时候,我们使用词袋模型,后面的讨论也是以词袋模型为主。
当然,词袋模型有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。但是大多数时候,如果我们的目的是分类聚类,则词袋模型表现的很好。
BoW之向量化
在词袋模型的统计词频这一步,我们会得到该文本中所有词的词频,有了词频,我们就可以用词向量表示这个文本。这里我们举一个例子,例子直接用scikit-learn的CountVectorizer类来完成,这个类可以帮我们完成文本的词频统计与向量化,代码如下:
- from sklearn.feature_extraction.text import CountVectorizer
- corpus=["I come to China to travel",
- "This is a car polupar in China",
- "I love tea and Apple ",
- "The work is to write some papers in science"]
- print vectorizer.fit_transform(corpus)
我们看看对于上面4个文本的处理输出如下:
- (0, 16)1
- (0, 3)1
- (0, 15)2
- (0, 4)1
- (1, 5)1
- (1, 9)1
- (1, 2)1
- (1, 6)1
- (1, 14)1
- (1, 3)1
- (2, 1)1
- (2, 0)1
- (2, 12)1
- (2, 7)1
- (3, 10)1
- (3, 8)1
- (3, 11)1
- (3, 18)1
- (3, 17)1
- (3, 13)1
- (3, 5)1
- (3, 6)1
- (3, 15)1
可以看出4个文本的词频已经统计出,在输出中,左边的括号中的***个数字是文本的序号,第2个数字是词的序号,注意词的序号是基于所有的文档的。第三个数字就是我们的词频。
我们可以进一步看看每个文本的词向量特征和各个特征代表的词,代码如下:
- print vectorizer.fit_transform(corpus).toarray()
- print vectorizer.get_feature_names()
输出如下:
- [[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0]
- [0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0]
- [1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0]
- [0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
- [u'and', u'apple', u'car', u'china', u'come', u'in', u'is', u'love', u'papers', u'polupar', u'science', u'some', u'tea', u'the', u'this', u'to', u'travel', u'work', u'write']
可以看到我们一共有19个词,所以4个文本都是19维的特征向量。而每一维的向量依次对应了下面的19个词。另外由于词”I”在英文中是停用词,不参加词频的统计。
由于大部分的文本都只会使用词汇表中的很少一部分的词,因此我们的词向量中会有大量的0。也就是说词向量是稀疏的。在实际应用中一般使用稀疏矩阵来存储。将文本做了词频统计后,我们一般会通过TF-IDF进行词特征值修订。
向量化的方法很好用,也很直接,但是在有些场景下很难使用,比如分词后的词汇表非常大,达到100万+,此时如果我们直接使用向量化的方法,将对应的样本对应特征矩阵载入内存,有可能将内存撑爆,在这种情况下我们怎么办呢?***反应是我们要进行特征的降维,说的没错!而Hash Trick就是非常常用的文本特征降维方法。
Hash Trick
在大规模的文本处理中,由于特征的维度对应分词词汇表的大小,所以维度可能非常恐怖,此时需要进行降维,不能直接用我们上一节的向量化方法。而最常用的文本降维方法是Hash Trick。说到Hash,一点也不神秘,学过数据结构的同学都知道。这里的Hash意义也类似。
在Hash Trick里,我们会定义一个特征Hash后对应的哈希表的大小,这个哈希表的维度会远远小于我们的词汇表的特征维度,因此可以看成是降维。具体的方法是,对应任意一个特征名,我们会用Hash函数找到对应哈希表的位置,然后将该特征名对应的词频统计值累加到该哈希表位置。如果用数学语言表示,假如哈希函数h使第i个特征哈希到位置j,即h(i)=j,则第i个原始特征的词频数值ϕ(i)将累加到哈希后的第j个特征的词频数值ϕ¯上,即:
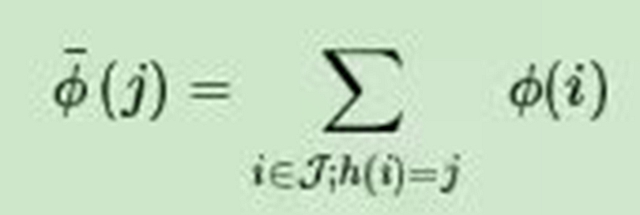
但是上面的方法有一个问题,有可能两个原始特征的哈希后位置在一起导致词频累加特征值突然变大,为了解决这个问题,出现了hash Trick的变种signed hash trick,此时除了哈希函数h,我们多了一个哈希函数:
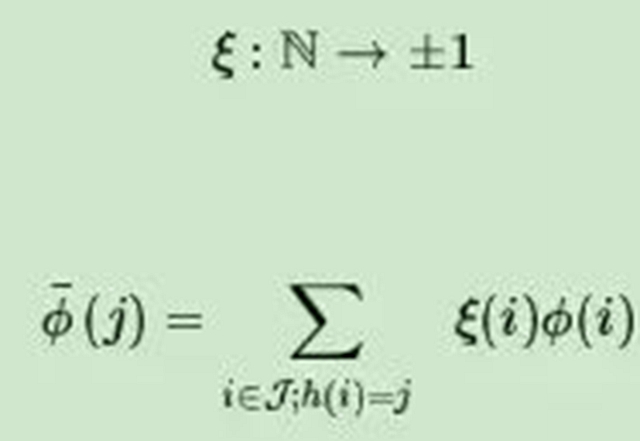
这样做的好处是,哈希后的特征仍然是一个无偏的估计,不会导致某些哈希位置的值过大。
在scikit-learn的HashingVectorizer类中,实现了基于signed hash trick的算法,这里我们就用HashingVectorizer来实践一下Hash Trick,为了简单,我们使用上面的19维词汇表,并哈希降维到6维。当然在实际应用中,19维的数据根本不需要Hash Trick,这里只是做一个演示,代码如下:
- from sklearn.feature_extraction.text import HashingVectorizer
- vectorizer2=HashingVectorizer(n_features = 6,norm = None)print vectorizer2.fit_transform(corpus)
输出如下:
- (0, 1)2.0
- (0, 2)-1.0
- (0, 4)1.0
- (0, 5)-1.0
- (1, 0)1.0
- (1, 1)1.0
- (1, 2)-1.0
- (1, 5)-1.0
- (2, 0)2.0
- (2, 5)-2.0
- (3, 0)0.0
- (3, 1)4.0
- (3, 2)-1.0
- (3, 3)1.0
- (3, 5)-1.0
和PCA类似,Hash Trick降维后的特征我们已经不知道它代表的特征名字和意义。此时我们不能像上一节向量化时候可以知道每一列的意义,所以Hash Trick的解释性不强。
小结
在特征预处理的时候,我们什么时候用一般意义的向量化,什么时候用Hash Trick呢?标准也很简单。
一般来说,只要词汇表的特征不至于太大,大到内存不够用,肯定是使用一般意义的向量化比较好。因为向量化的方法解释性很强,我们知道每一维特征对应哪一个词,进而我们还可以使用TF-IDF对各个词特征的权重修改,进一步完善特征的表示。
而Hash Trick用大规模机器学习上,此时我们的词汇量极大,使用向量化方法内存不够用,而使用Hash Trick降维速度很快,降维后的特征仍然可以帮我们完成后续的分类和聚类工作。当然由于分布式计算框架的存在,其实一般我们不会出现内存不够的情况。因此,实际工作中我使用的都是特征向量化。