支持传统的IT体系架构要耗费大量的时间,这与当前快节奏的业务环境背道而驰。新兴的各种技术,例如融合与超融合基础架构,公有云和私有云,以及基于Hadoop和Spark的横向扩展产品与服务正在缓解局面。但这还不够,我们希望可以将更多时间投入到创新应用的开发,而非维护管理IT基础架构之上。
分解(Disaggregation),将一个聚合体分割成多个组成部分,这并不是什么破天荒的想法,但其重要性正在日益凸显出来。在IT领域中,分解意味着将计算机分割成处理、内存、I/O、存储、缓存、网络结构等核心元素,从而实现最具成本效益的敏捷的基础架构和高效的存储配置。
但为什么我们要在诸如超融合等聚合IT资源的理念盛行十年之后重提这一话题呢?原因在于单独扩展某单一资源通常会比将其作为一个整体进行扩展来得更具成本效益。
分解的理念在于用大量计算机来创建出独立的资源池,然后根据需要分配适当的资源组合——内存、处理器、缓存、网络架构以及存储分配——从而为各个应用程序提供相应服务。如果操作得当,分解基础架构可以随时执行,提升高达80%的资源利用率,并且让管理成本随着存储分配的自动化而下降。
我们用五款产品来诠释分解技术是如何使用,并从中获益的。其中三款和存储相关:Nutanix、Pivot3和Datrium;剩下两款DriveScale和HP的Synergy将分解应用于更前沿的领域。
超融合与分解
超融合的关键特点之一在于以计算或存储规格预先定义的节点作为购买的最小单位,即便你只需要计算或是存储。在Nutanix早期的产品中你别无选择。不过现在Nutanix、Pivot3及其他公司可以销售大容量存储或者高性能计算的型号,一定程度上减缓,但未彻底消除这个问题。
Nutanix提供一系列的产品型号,从最低零存储——完全没有磁盘开始。此外,为了满足一系列应用的要求,你可以构建具有多种节点的混合式集群,这亦是超融合技术的关键特性,可以让你购买最适合的节点,并在整体上统一管理集群。
理想状况下,分解所指的是计算与存储的彻底分离,你完全可以购买100%的计算或存储空间。但是在Nutanix环境中,只有100%的计算而非存储。Nutanix对侧重存储的应用使用最小计算单元来满足。虽然不算是纯粹的分解,但至少在一定程度上达到了目的。
Pivot3则采用不同的方式,虽与Nutanix类似,但它有单独的计算节点和具备最小计算能力的存储节点。存储节点可以应用于典型的超融合环境中,其中侧重于虚拟机的运行,并假设使用虚拟化管理程序。不过亦可以脱离虚拟化管理程序使用节点——换而言之,其本质上支持裸机运行。客户可以像从前那样在物理基础架构上运行尚未虚拟化的应用程序,同时仍然通过单独的控制台管理超融合集群中创建出的存储池。
Pivot 3收购了NexGen Storage,一家具备卓越服务品质的外部磁盘阵列供应商,从而可以将NexGen存储阵列“分解”集成到超融合资源池中。Pivot 3还允许使用iSCSI存储资源运行集群的物理或虚拟应用程序。超融合集群内外部的所有应用程序均可以使用NexGen基于策略的服务质量功能。
虽然都不是纯粹的分解,不过Nutanix和Pivot 3正在努力为客户带来价值。
分解与Datrium
Datrium仅有存储产品,不过公司将传统许多与存储阵列相关联的功能分割开来,扩展了对分解技术概念的外延。简而言之,Datrium在横向扩展的服务器架构中实现快照、压缩、重复数据删除、复制、加密等功能,不过在存储阵列中留下了部分功能,例如镜像的非易失性RAM和简化的双控制器。这样的存储比JBOD更为丰富,但比传统阵列更加简单。Datrium将此称为DVX数据节点。
Datrium使用软件定义的原则在服务器中实现这部分功能,充分利用横向扩展;例如,你可以通过添加一台服务器来提高重复数据删除或加密性能。与此同时,Datrium运用更为智能但简化的存储,其声称用户可以在超融合方面得到比其他100%的软件定义产品供应商(如Hedvig和SwiftStack)更好的性能。与传统的双控制器存储阵列不同,Datrium的数据节点不会形成任何孤岛,并且相互独立地提供横向扩展所需的性能和容量。服务器还可以运行物理、虚拟和容器应用程序。
Datrium将此称为“开放式融合”,而非纯粹的分解,我们可以再来看看该理念还有什么其它的实践形式。
HPE Synergy分解
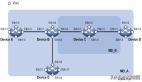
HPE的Synergy是业内首款将其HPE产品称为可组合的基础架构平台,这是最纯粹的分解形式。从计算、存储和网络各个资源池开始,并根据需要在每款应用程序的软件控制下进行组合。其使用单一的上层API来管控所有这三层,完成基础架构构建、分解、管理、更新和扩展工作,Synergy同样适用于虚拟化、混合云和DevOps操作模型。
不同于传统的超融合技术,Synergy凭借其在虚拟化方面的优势,涵盖了各类物理和虚拟化应用——从传统类型、移动类型到云端应用。而超融合技术在一个横向扩展模型中将计算与存储分配结合在一起,在大多数情况下,其只是没能将网络涵盖在内。而从最初的形式上看,分解则从下往上构成了完整的基础架构,包含网络在内。
Synergy由三个基本要素构成:
池化的资源池。计算、存储与网络资源池根据每个应用程序所需和特定的服务级别划分供应。你可以根据应用程序的需要,将物理、虚拟和容器工作负载以及内部的存储容量,如直连的文件、对象或数据块存储,进行配置。鉴于3PAR存储在HPE产品家族中的重要地位,其可以被配置为外部直连存储、并作为资源池的组成部分。光纤可以支持多种协议,带宽可以在不中断的前提下扩展、调整。从而实现了随时添加计算、存储和网络资源,不用影响业务运作。这些资源自动成为资源池的一部分,提供应用程序使用。同时扩展并不会增加管理负担。
智能化的软件定义。HPE将Synergy构建为内置智能化软件定义的硬件。配置、扩展、取消等均经由模板完成,基础架构能够以近乎实时的速度进行组合和重组。Synergy既是基础架构,亦具有软件功能,使得曾经需要数小时或数日的常用功能现在可以在近乎即刻间发生。计算、存储与网络与适合的固件、BIOS、驱动程序以及操作系统镜像一同提供,无需运营人员干预。这也是Synergy使用模板的目的,让基础架构便于使用,不再强调内部硬件或软件的专业知识。这不仅适用于IT,同样也适用于DevOps和测试人员。开发、测试和生产环境之间的差异会消失,都使用相同一致的界面。
统一的应用程序接口。不同于传统的基础架构中每个设备都拥有自身独特的底层应用程序接口,你必须以此配置设备,Synergy在计算、存储与网络之间使用上层的应用程序接口。经过融合诸多基础架构设备供应商(Dell EMC、IBM与Cisco、NetApp与Cisco等)的努力,简化了计算、存储和网络的配置、管理。这通过掩蔽层来实现,在此之下,各元素仍有所不同。
Synergy统一的应用程序接口有两大特征: (1) 比典型命令行界面更加高级; (2) 设计目的在于跨越计算、存储与网络。另外其提供了单一的界面来发现、检索、盘点、配置、交付、更新和诊断基础架构。而且还是将Synergy整合到其它管理平台(包括Microsoft System Center、Red Hat和VMware vCenter),以及其它DevOps平台(如Chef、Docker、OpenStack、Puppet和Python)的单一化工具。
HPE Synergy产品
HPE Synergy的第一代模型是10U机架高度的12000 Frame。你可以在一个闭环内配置多个Frame,并用单个控制台同时管理上多个闭环。Frame中有五个重要元素——协同器、镜像流化器、协同存储、协同计算以及协同光纤模块——从而创建出一个完全分解的平台。
协同器。协同器负责发现、检索、盘点、配置、交付、更新和诊断基础架构中的计算、存储与网络资源。其是一台基于HPE OneView和统一应用程序接口的物理设备。协同器使用IT或业务用户开发出的服务器配置文件模板、能够跨计算资源自动化配置、更新和回收计算资源的过程。可以通过单个模板创建出许多计算模板配置文件。
镜像流化器。这是一款嵌入在Frame内的物理设备,镜像流化器内为各类应用程序储存了可启动的宝贵镜像,可以在几分钟内加载到计算模块上。这可以取代传统在物理设备上构建服务器、安装操作系统、虚拟化管理程序、I/O驱动器应用程序堆栈等操作,将原本需要数小时乃至数日,易出故障的流程转变为完全自动化、不会出错的过程,并且只需数分钟的时间。
协同存储、计算与网络。这些单独的模块让存储、计算与网络和系统内其它各个元素紧密集成。你只需要在这些资源不足时加以补充。所有三种元素从体系架构上都是横向扩展的,你可以构建以此逐一构建、管理起规模庞大的基础架构。即便是网络,在过去最为静态的元素,在今天也是可编程的,能够通过代码完成交付或撤回。
DriveScale的分解方式
DriveScale已经将计算与存储分解应用于下一代服务大数据分析的应用程序,例如Cassandra、Hadoop、Kafka、MongoDB和Spark。这些应用偏好横向扩展架构,通常由通用型服务器和小型节点构建而成,包含计算与直连式内置存储。这些节点数以百计,从而才能解决大数据的相关问题,每个节点都使用节点本地的相关数据来处理部分难题,然后整合结果,得出答案。通过将数据保存在本地,使其最贴近计算资源,使得延迟和流量变得最小。
这种方式在过去五年中已经掌控了整个大数据世界。但是伴随着集群的日益膨胀,有时甚至出现成千上万个节点,问题随之出现,例如欠缺灵活性、繁琐而昂贵的升级费用,以及应用程序孤岛的问题。应用孤岛产生的原因在于,对每一项应用程序,其计算与存储分配的比例需要保持相同,而由于需要保持处理器温度,机箱内可容纳的驱动器数量是有限的。
DriveScale将计算与存储分解开,从而可以在线不间断地创建或变更应用程序上计算与存储的分配比例。其要求从一家或数家供应商那里分别购买JBOD计算和存储(服务器供应商由于改善了空气流,可以比标准的商品化服务器提供更高的计算密度)。从而让你在不同的时间节点分别更新服务器或存储——通常计算会在每两三年更新一次,而驱动器则会维持五年的时间。由于可以使用单独的计算和存储池,你可以随意分配不同的应用程序资源,较以前大大提高了资源利用率。
DriveScale使用SAS转以太网适配器,将磁盘驱动器连接到标准机架内的以太网交换机上,而该交换机会和集群内所有的计算单元相连。供应商的专利技术存在于协同软件之中,通过编程方式交付、管理和回收资源。其图形化界面基于RESTful API,可以向上集成客户首选的管理工具,包含Chef、Puppet等。
值得你关注的分解技术
从字面上的解释看,分解意味着将某些东西分割成各个组件,然后将这些组件形成资源池,可以用程序化的方式加以组合,从而将最适合的资源组合交付给应用程序。某些存储与超融合供应商已经应用分解原则使其产品更具成本效益。不过DriveScale与HPE Synergy以最新的,不同寻常的方式来加以应用。
HPE Synergy是最全面、应用最广泛的分解范例,证实了分解理念如何用于解决各种问题。HPE将协同体系架构视为超融合技术发展的下一阶段。而其他供应商,如DriveScale,根据分解原则来解决具体的问题。
虽然公有云供应商(例如Amazon Web Services和Google Cloud Platform)所使用的体系架构的细节上不为人所知,但分解很有可能是其基本原则。可能是分解的早期阶段,创建了单独的资源池,将资源在适合的时间加以正确的组合,然后将其提供给应用程序。这无疑是正确的做法,所以说,现在是时候将“分解”添加到我们的日常的词汇表中去了。