在本技术分析报告的***部分《研学社·系统组 | 实时深度学习的推理加速和持续训练》,我们介绍了最近一些用于 DNN 推理加速的硬件和算法技术。在这第二部分,我们将基于最近一篇论文《在连续学习场景中对深度神经网络进行微调(Fine-Tuning Deep Neural Networksin Continuous Learning Scenarios)》探讨 DNN 连续学习,该论文的作者为 Christoph Kading、Erik Rodner、Alexander Freytag 和 Joachim Denzler。
要将深度学习系统投入生产,有一个方面很重要,就是要能应对输入和输出数据的分布随时间的变化。和任何统计机器学习模型一样,深度神经网络的可行性和有效性严重取决于一个假设——输入和输出数据的分布不会随时间发生显著变化,否则会使得模型原本学习到的模式和复杂关系表现不佳或甚至完全不可用。但是,在真实世界中,这样的假设很少能够成立,尤其是在信息安全等领域,其中基础数据生成机制的快速演变已然是一种常态(在安全领域的案例中,这是因为防御方和对手这两方都要不断努力改变自己的策略以超越对方,从而利用对手未加防备的漏洞。因此,随着我们在这些领域中应用深度学习来更好解决许多曾经无法解决的问题,深度神经网络的连续学习问题也就得到了机器学习即服务(MLaaS)提供商和应用架构师的越来越大的关注——我们该怎么很好地执行连续学习,而不会损害生产质量或提高资源消耗。
在本报告的第二部分,我们将会形式化连续学习场景并介绍一种增量式的微调方法(incremental fine-tuning approach)。然后我们会给出有多个实证研究支持的三大重要发现。本文的目的不是全面调查和描绘连续学习的现状全景,而是为了启发更多不同专业背景的人加入到我们的讨论中,并与我们交流知识。
第二部分:连续学习
连续学习场景和增量式微调
微调(fine-tuning)原本一直是指预训练一个带有生成式目标(generative objective)的 DNN 的过程,后面跟着带有一个鉴别式目标(discriminative objective)的额外训练阶段。早期关于预训练和微调深度信念网络和深度堆叠自动编码器的研究成果全都遵循这种方法。研究者期望这种生成式训练阶段能让网络学习到数据域的良好分层表征,而鉴别式阶段则能利用这种表征,并希望它能在该表征空间中学习到一个更好的鉴别器功能。
最近,研究者已经在使用微调来在 ImageNet 这样的大型通用数据集上预训练复杂精细、当前***的 DNN 了,然后又在更小的相关数据集上对模型进行微调。这有助于缓解医疗诊断或地理探测等领域内有标签训练数据不足的问题,因为在这些领域中,获取有标签数据需要密集的劳动或成本高昂。研究者的基本假设是:在大型训练数据集上得到的相当好的结果已经使该网络接近参数空间中的局部***了,所以即使新数据的数据量很小,也能快速将该网络引导至***点。
从连续学习的观点来看,上面两种方法都是网络只接受两次训练(初始预训练和一次更新)的极端案例。连续学习的更一般形式是迭代式地训练和更新,这就带来了一个问题:应该怎样稳健又高效地执行一系列持续的更新?对于生产系统来说,稳健性是很重要的,因为一个实时系统通常不能容忍模型表现突然下降,而该系统的实时本质又必需对资源和时间的高效率利用。为此,在下面的讨论中,我们的重点关注场景是每个更新步骤仅使用少量新数据的情况(相比于原来的完全的训练数据集),但要求更新后的模型是即时可用的。
1. 连续学习场景
连续学习的最一般形式是整个训练数据集都会随时间演变。但是,为了让学习可行,我们设置了一个限制,即输入域保持不变。这并不意味着输入域中的数据分布是恒定不变的——相反,我们允许多种多样的数据分布会发生变化的案例,但这些变化总是定义在同一域中。另一方面,我们假设输入域可以变化。这是为了配合当系统持续运行了相当长时间后出现新标签的案例。比起输入域变化的情况,这个假设更有可能实际出现,因为在自动驾驶汽车等大多数生产系统中,如果输入视频或激光雷达图像急剧改变(由于极端天气、光照、地形或路况),那我们就不能期望系统还能远程工作;但我们希望该系统能在连续学习过程中适应新型的不可碰撞的目标,并且能够应对这种新标签的类别。因此,我们将我们的连续学习场景中的数据定义为按时间 t 索引的数据集![]() 的序列。我们的目标是为每个时间步骤 t 学习一个网络
的序列。我们的目标是为每个时间步骤 t 学习一个网络![]() 。根据
。根据![]() 的变化方式,我们有两种可能场景:
的变化方式,我们有两种可能场景:
1) 我们不会随时间获得新类别,但是我们的数据集不断增长。
![]()
2) 我们会随时间获得新类别的样本。
![]()
在每个时间步骤 t,我们需要使用新出现的可用信息更新我们的网络;这些新信息即为更新集(update set):![]() 。因为我们假设更新集很小,为了避免欠拟合,在时间步骤 t 我们使用上一步收敛的
。因为我们假设更新集很小,为了避免欠拟合,在时间步骤 t 我们使用上一步收敛的![]() 热启动(warm-start)优化。这种技术的可行性取决于一个假设,即
热启动(warm-start)优化。这种技术的可行性取决于一个假设,即![]() 在数据集扩展时会平滑地改变——因此我们要假设更新步骤小且输入域恒定。在实际情况中,就算这些假设(部分地)属实,我们仍还依赖于一个预期:通过在之前一个局部***点的初始化,带有不同参数空间情况的新优化问题可以快速且稳定地收敛到一个新的局部***点。但是,大多数现代 DNN 都太复杂了,所以难以保证这一点——它们的目标函数是高度非线性和非凸的,有时候参数空间中还都是些糟糕的局部条件数(local condition numbers)。即便如此,热启动仍然是目前***的方法之一,肯定比从头开始更好,而且在实验上也表现出了***的潜力。对于场景 2,在每个时间步骤,我们都可能需要为***的输入层添加额外的神经元以及与前一层的连接权重。
在数据集扩展时会平滑地改变——因此我们要假设更新步骤小且输入域恒定。在实际情况中,就算这些假设(部分地)属实,我们仍还依赖于一个预期:通过在之前一个局部***点的初始化,带有不同参数空间情况的新优化问题可以快速且稳定地收敛到一个新的局部***点。但是,大多数现代 DNN 都太复杂了,所以难以保证这一点——它们的目标函数是高度非线性和非凸的,有时候参数空间中还都是些糟糕的局部条件数(local condition numbers)。即便如此,热启动仍然是目前***的方法之一,肯定比从头开始更好,而且在实验上也表现出了***的潜力。对于场景 2,在每个时间步骤,我们都可能需要为***的输入层添加额外的神经元以及与前一层的连接权重。
但还存在三个问题。一,每个更新步骤需要多少个 SGD 步骤?二,在每个更新过程中,我们使用多少前一步骤的数据,又使用多少当前步骤的数据?三,这个更新流程是否稳健,能应对标注噪声吗?对于生产系统来说,这些问题都很重要,因为正如我们前面谈到的,稳健性和效率是很重要的。
实证研究
在实验中,我们使用了在 ImageNet ILSVRC-2010 上预训练的 BVLC AlexNet 作为示例网络。我们将学习率固定为 0.001,L2 权重衰减固定为 0.0005,动量固定为 0.9;并且更新集的大小也固定为![]() ,其中的样本来自同一类别。对于评估,我们使用了 MS-COCO-full-v0.9 和 Stanford40Actions。相比 ImageNet,这两个数据集都很小,因为我们想使用比初始预训练小的更新来评估连续学习的表现。对于 MS-COCO,我们使用了 15 个类别,其中每个包含 500 到 1000 个样本;每个样本都仅保留 ground truth 边界框,且宽和高都至少是 256 像素。为了进行评估,我们随机选择了 10 个类来对 CNN 进行初始化微调。从剩余的数据中,我们再随机选择 5 个类别用作全新数据(在每个更新步骤输入的新数据),并且从每个类别随机选择了 100 个样本。每个更新步骤使用的度量都是分类准确度。为了得到无偏差的比较,我们进行了该实验 9 次。
,其中的样本来自同一类别。对于评估,我们使用了 MS-COCO-full-v0.9 和 Stanford40Actions。相比 ImageNet,这两个数据集都很小,因为我们想使用比初始预训练小的更新来评估连续学习的表现。对于 MS-COCO,我们使用了 15 个类别,其中每个包含 500 到 1000 个样本;每个样本都仅保留 ground truth 边界框,且宽和高都至少是 256 像素。为了进行评估,我们随机选择了 10 个类来对 CNN 进行初始化微调。从剩余的数据中,我们再随机选择 5 个类别用作全新数据(在每个更新步骤输入的新数据),并且从每个类别随机选择了 100 个样本。每个更新步骤使用的度量都是分类准确度。为了得到无偏差的比较,我们进行了该实验 9 次。
1. 每个更新步骤的 SGD 迭代次数
SGDminibatch 的大小固定为 64,但我们改变了每个更新步骤中 SGD 迭代执行的次数。我们将 SGD 迭代次数表示成了一个相对于总训练数据大小(即 epoch 数)的比例,以补偿不断增长的训练数据大小。
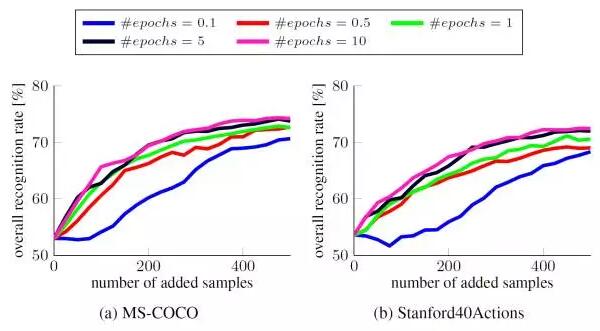
让人惊讶的是,即使每次更新的 SGD 迭代少了很多,分类准确度依然稳健,除了那些仅使用了十分之一数据的案例,很可能是因为在这样小的 epoch 中一些类别代表不足。事实上,我们可以直接将 SGD 迭代的次数固定为一个小常量(比如更新集大小![]() ),表现也不会显著下降。
),表现也不会显著下降。
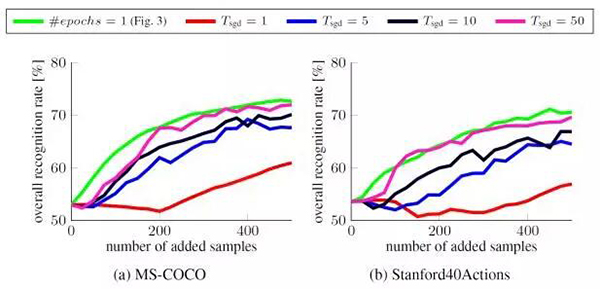
2. 每个更新步骤中旧数据与新数据的比例
对于增量式的学习算法,旧数据与新数据的影响的比例是最重要的超参数之一。在 SGD 迭代中,我们根据概率![]() 对每个样本 i 进行了采样,其中 0≤λ≤1。在极端情况下,λ=0 意味着之前的数据完全被忽视了,而 λ=1 则表示新数据的影响推迟到了下一个更新步骤,因为这是它们在
对每个样本 i 进行了采样,其中 0≤λ≤1。在极端情况下,λ=0 意味着之前的数据完全被忽视了,而 λ=1 则表示新数据的影响推迟到了下一个更新步骤,因为这是它们在![]() 中结束的时候。
中结束的时候。
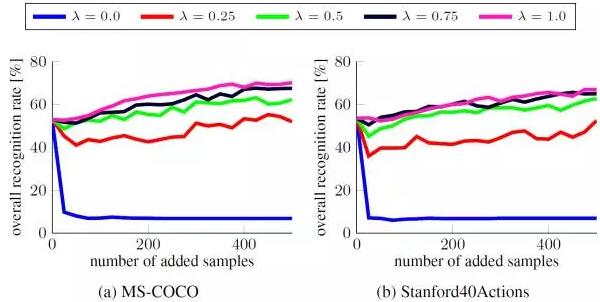
我们看到,为了防止在更小的更新集上过拟合,就必需旧数据。我们观察到一个有趣的结果:因为新的更新集数据被认为是下一步骤 t 中![]() 的一部分,因此 λ=0.75 和 λ=1 的表现差不多。
的一部分,因此 λ=0.75 和 λ=1 的表现差不多。
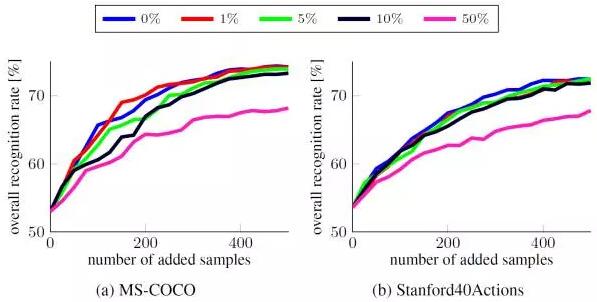
3. 在有标注噪声时保持稳健
在生产场景中,新数据的标签很少是无噪声的——由于实时性需求,人类判断者往往需要做出快但并不准确的决定,而三到五位判断者之间的不一致率可能会高达 75%。因此,在有标注噪声时保持稳健对于连续学习方案而言至关重要。
我们使用 64 的 minibatch 大小在每个更新步骤执行了 10 epoch,并随机污染固定比例的新可用数据——用剩余类别的样本替换这些数据,但同时保持它们的标签不变。如预期一样,标注噪声会降低准确度,但我们的连续学习方案对此相对稳健,在存在 10% 的噪声时准确度仅下降了 2%。
作者 Yanchen 毕业于普林斯顿大学机器学习方向,现就职于微软Redmond总部,从事大规模分布式机器学习和企业级AI研发工作。
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】