













1. 工具简介
dataWrangler是一款由斯坦福大学开发的在线数据清洗、数据重组软件。主要用于去除无效数据,将数据整理成用户需要格式等。通过使用dataWrangler能节约用户花在数据整理上的时间,从而使其有更多的精力用于数据分析。
2. 主要特点
dataWrangler的操作极为简便,通过简单点击就能完成一系列的数据整理。与传统的数据处理软件相比,其独特的智能分析和建议功能,极大方便了用户的数据处理操作。dataWrangler还会列出数据修改的历史记录,用户可以极为方便地查看过去的修改,并可以撤销某一条修改操作。
同时,dataWrangler是一款在线工具,这为用户省去了安装软件的繁琐过程,也使用户摆脱了操作系统对软件使用的限制。
3. 工具界面(工作区、菜单、术语等)
在浏览器的地址栏中输入dataWrangler的地址并进入后,会进入dataWrangler获取输入数据的界面,如下图所示。
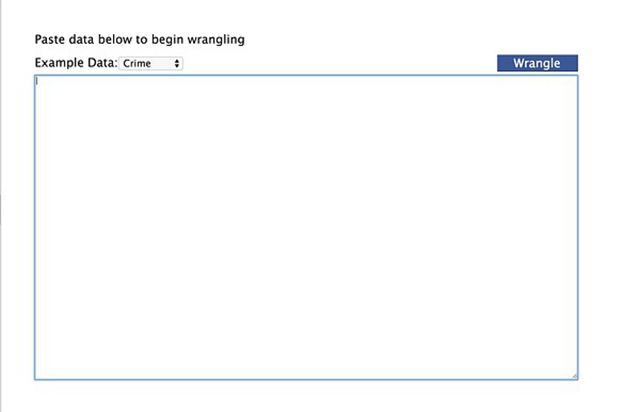
进入dataWrangler后的数据输入界面。
将CSV格式的数据拷贝并粘贴到数据输入区域后点击dataWrangle按钮,进入数据处理界面,开始数据的整理和修复。数据处理界面如下图所示。
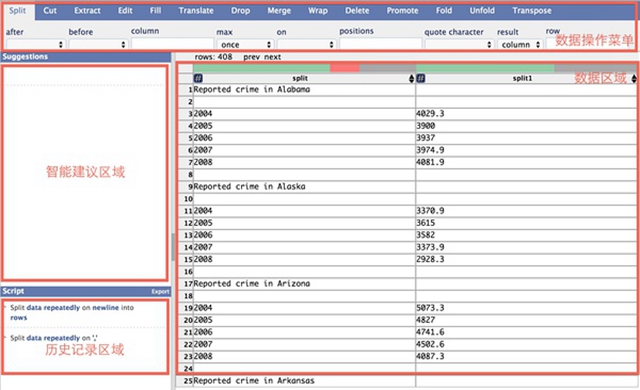
数据处理主界面。
数据处理界面左侧的面板包括一个根据当前选中数据给出的数据修改建议列表和一个数据操作历史记录列表。点击修改建议列表中的粗体部分,就可以执行该条修改建议。界面的右侧是包含具体数据的数据表。
4. 操作流程(核心功能呈现)
下面介绍dataWrangler的主要功能。
->去除无效数据
点击无效数据的行号,这一行就会变成红色高亮状态,同时左侧的建议栏会给出一系列的修改建议。点击合适的修改建议后, 该修改操作将被执行。
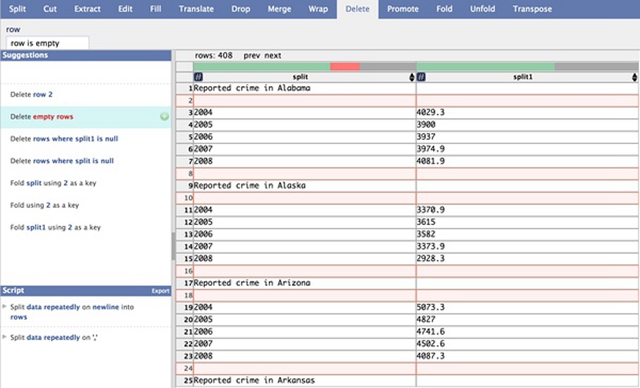
删除空行操作。
如图所示,点击”Delete empty rows”的修改建议后,所有空白行将被删除。
->提取部分数据
在需要提取部分数据作为单独一列时,首先选中欲提取的数据,此时dataWrangler会自动分析用户的意图,并提取出相应数据。如果用户进行二次选取,则会对选取意图进行修正,以提取用户真正需要的数据。
下图是用户欲提取州名时,首先选取了”Alabama”,但此时dataWrangler认为用户想要提取相应长度的字符, 所以没有达到要求的”Alaska”并未被选取, 同时”California”等较长的字符也只被截取了一部分。
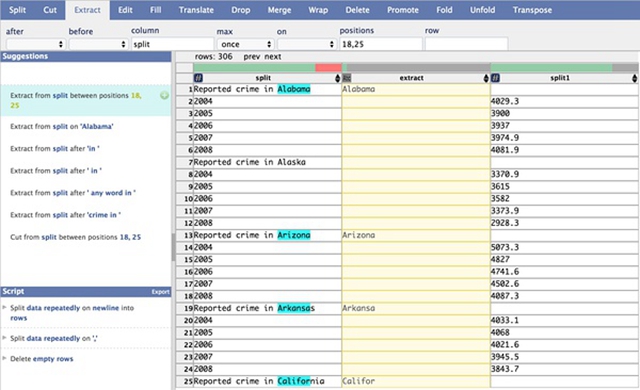
选择欲提取的数据。
此时,继续选取”Alaska”,dataWrangler通过二次选取获知用户想要提取的是这一位置的整个单词,进而成功提取出了州名。如下图所示。
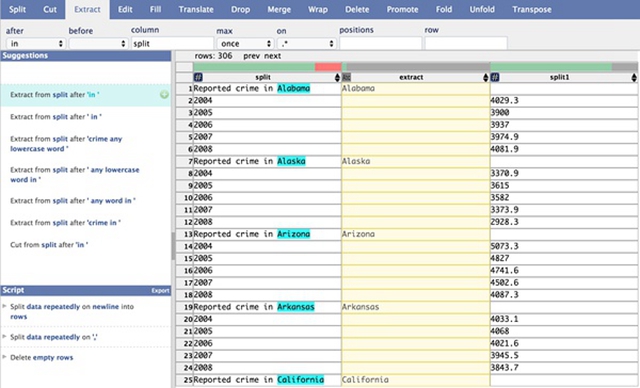
通过二次选取修正提取结果。
->自动填充数据
提取出州名后,需要将其填充到每一行数据中。此时,只需点击一下州名数据列最上方的标题,左侧的智能建议栏中就会出现自动填充数据的建议。点击该建议,即可完成自动填充数据,如下图所示。
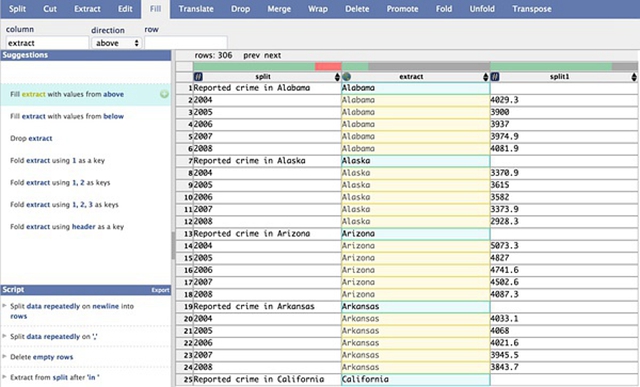
自动填充数据。
->删除无用数据
进行数据自动填充后,遗留下来的一些数据栏已经没有任何意义,需将其删除。点击欲删除数据中国的某一行,dataWrangler会自动给出删除建议。同时,将被删除的行将会高亮表示,如下图所示。
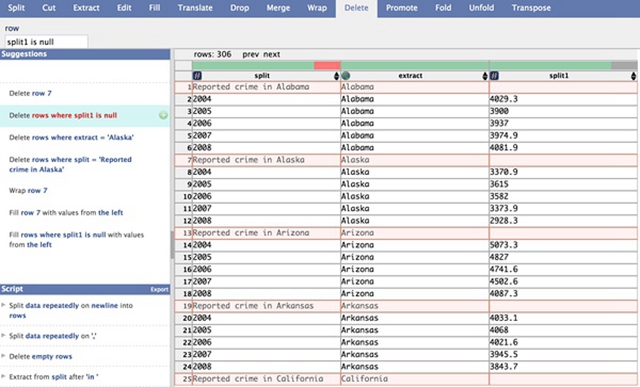
删除无用行。
点击左侧删除建议执行删除操作,结果如下图所示。
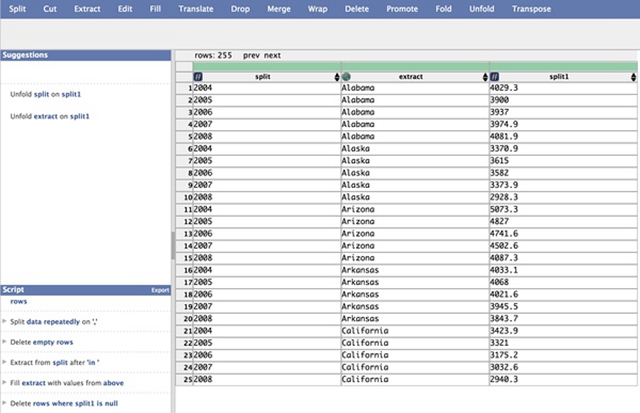
删除无用行后的结果。
->数据重构
在某些情况下,可能需要将数据重新组合成需要的格式。点击表格上方的绿色方块后,dataWrangler会给出多种数据重构建议。如下图所示。
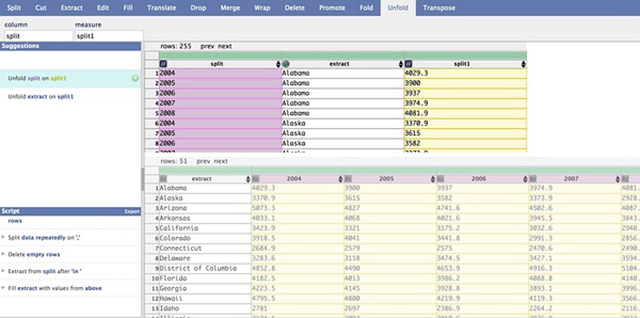
对数据进行重构。
双击列名,可以对列名进行编辑, 图中的列名已经修改为”year”,”state”等有意义的文字。
点击左侧重构建议后,得到的数据结果如下图所示。
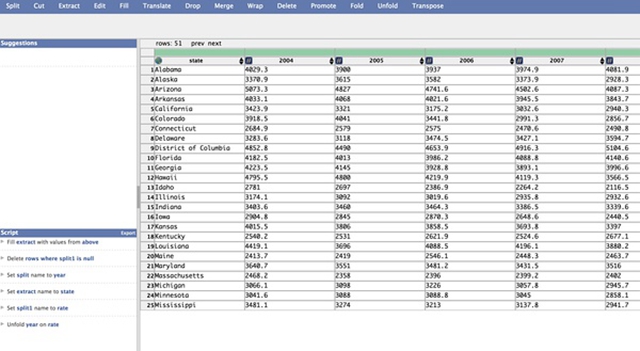
数据重构后的结果。
此时,每一行是一个州在不同年份的数据。















