对于深度学习,我也是一个初学者,这篇文章只是我的个人想法,能力有限,所以对不对,不好说,但的确是我现在的真实想法,我也会按这个思路去尝试。请大家带着质疑精神去读吧。
一
我大概是一个好奇心很重的人,所以每次有新的技术出来,我都会在***时间跟进。但我又是一个记性不太好的人,大部分研究过的新技术,因为没有天天用,很快又都忘掉了。
深度学习刚开始流行的时候,我就做过简单的学习。当时我的结论是短期内,深度学习只能在***能徘徊,很难进展到强智能。
这个结论在今天看来,也不算过时。但真正被深度学习给 Shock 到,是去年和某教育 APP 的 CEO 同学聊天。他告诉我,在教育这个垂直领域,他们的语音识别率已经比讯飞要高了,依赖于大量的数据;更 NB 的是,加上 NLP,他们的 AI 已经可以帮老师改主观题了。主观题啊,就是数学的问答题,语文的作文。
这让我开始重新思考***能。
二
完全依靠强智能的应用场景,会产生很多问题。比如自动驾驶,要想在中国这种各种奇葩状况层出不穷的交通环境下运行,一时半会儿是不行。即使是一个看起来简单的问答机器人,也没一家真正做好,你多问 siri 几句,她很快就晕了。
经常关注我微博同学会知道,我最喜欢说的一句话就是:「能自动化的,要自动化;不能自动化的,要半自动化」。
在人工智能上,这个法则似乎依然是有效的。既然现在强智能还不够强,那么为什么我们不用***能+人工确认的方式,来实现「半智能化」呢:用机器帮你做预选,你来做最终选择,虽然依然包含了人工干预,但却可以把生产效率提升几十倍。
三
有同学和我说,找不到应用深度学习的场景,这是因为太执着于强智能,想让机器独立处理所有事情;如果使用「半自动化」的思路,你会发现遍地都是场景。
最典型的场景就是「按需求进行组合搭配」。拿今天正式上线的小程序举例子吧,小程序在框架层上,将功能分隔到了page 的粒度,这使得小程序的组件会很好的被重用;而在设计上,小程序提供了统一的官方指导风格,所以不会出现太多个性化的东西。
我需要一个用户资料管理, xpm install user-profile;我需要动态 Feed 流,xpm install feed-timeline 。
然后这货就喊着要去做,还在 GitHub 上开了个坑,据说 SDK 已经写完,安装器年前能开始内测。https://git.oschina.net/xpmjs/xpm
然后我告诉他,你得赶紧做,从长远看,通用应用***是不太值钱的,因为很快就有开源项目把它做得很好。真正值钱的是,下沉到行业里边的应用。比如说吧,同样是用户资料页,房地产行业的、猎头行业的以及技术社区的会完全不一样。但区别也就是添加几个行业特定的字段而已。 大量的「二次开发」工作,才是最为琐碎又最为挣钱的。
这就是典型的可以用上深度学习的场景。通过抓取对应行业的 H5 页面,我们很快就可以把各个行业需要哪些可能的字段给整理出来,然后把这些交给机器进行学习,当再有新的需求进来的时候,机器就可以自动配好预设字段。机器会出错么?当然。但哪怕是80%的准确率,也已经可以节省掉好几个程序员了。
为什么我要学深度学习? 因为这背后是 TM 白花花的银子。
四
这是近在眼前的机会,我再说个远点的。大家知道,日本人的科技树一般都不按套路长。早稻田大学一心想把深度学习用在二次元上,他们先是搞了个项目给黑白画稿上色;后来又发了篇论文给草稿描线。我觉得很快,他们就要开始学习漫画大家的画风,通过线稿生成原稿了
「传统」的日漫或许很难由机器生产,但现在社交网络上大量生产的「条漫」却对画质要求不高。尤其是四格类的,经常关注我的同学应该看过我用 Comipo!软件「绘制」的四格漫画。( http://zhijia.io/anthology/101869 ) 当机器参与进来后,根据脚本生成这种品质的漫画简直易如反掌。到时候,人人都能过上1%的生活。
为什么我要学习深度学习?因为我要让未来早点来。
五
上周我发了条微博,说2017年要自学深度学习,有过千的同学表示愿意一起来学。
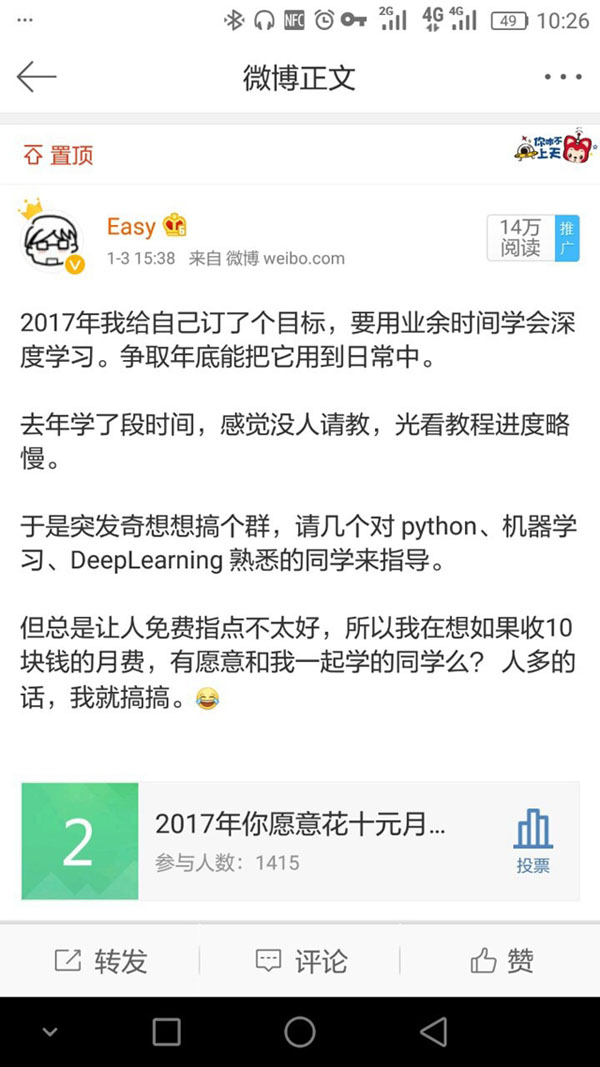
也有同学表示,机器学习不是那么好学的。其实细心的同学会发现,我一直说的是「深度学习」而不是「机器学习」。
因为我的目的很简单,那就是用。在学习***年,我给自己定的目标不是要理解「机器学习」的原理,而是要把「深度学习」用到自己产品的方方面面。
用以致学,是我一贯的学习方式。刚开始不理解没关系,先用起来。需要理解的时候,再慢慢理解。说到底,也没多少人理解自己手机每一部分的工作原理不是。
先学「深度学习」还有一个好处,那就是不用太多「机器学习」的基础。能把tensorflow、kears 这种开源框架搭起来,然后喂数据,然后看结果。等到优化的时候再去补知识点。
因为深度学习更像是一个黑盒子,现在很多专门搞深度学习的同学也说不清楚为什么要建三个层、要放四个节点;什么情况下用什么激活函数。只说通过实践+观察数据慢慢调整。这简直就是新手上路的***切入点嘛。
如果不想在本地搭建环境,AWS 上已经有可以用的镜像,基于 API 的深度学习服务也日益增多。这东西就像水电气一样,用比学重要。
也有同学严谨的指出,很多场合下,机器学习的其他方法远比深度学习有效。他们是对的,如果说学好整个机器学习,可以做到90分;那么光用深度学习,可能只有70分。
但现在绝大部分的程序,连 TM 一点智能都还没用上呢。从零分到70分,只需要把深度学习用起来。
为什么我要学习深度学习,因为这 TM的性价比太高。