












1. 为什么要为深度学习模型减肥
随着深度学习的发展,神经网络模型也越来越复杂,常用的模型中 VGG 系列网络的计算量可以达到 30-40 GOP(1GOP=109 运算)。这些神经网络通常运行在 GPU 上,但是如果我们要在移动/嵌入式端也实现深度学习,那么这样巨大的模型是绝对跑不动的。移动/嵌入式端的计算能力往往只有桌面级 GPU 的 1/100 到 1/1000,换句话说在 GPU 上一秒 40 帧的深度学习 CV 算法在移动/嵌入式端一秒只有 0.04-0.4 帧,这样的性能会极大影响用户体验。

常用深度学习网络运算量
在移动/嵌入式端跑深度学习模型,除了运行速度之外,能效比(energy efficiency)也是关键指标。能效比指的是一次运算所需消耗的能量,它决定了移动/嵌入式端运行深度学习算法时电池能用多久。能效比与深度学习模型息息相关,我们下面将会看到深度学习模型的大小会决定运行算法时的片外内存访问频率,从而决定了能效比。
2. 怎样的模型才能算「身材苗条」?
正如我们减肥不仅要看体重还要看体脂率一样,为深度学习模型「减肥」时不仅要看模型计算量还要看模型大小。
模型计算量是衡量深度学习是否适合在移动或嵌入式端计算的最重要指标,通常用 GOP 单位来表示。例如,流行的 ResNet-18 的计算量大约是 4 GOP,而 VGG-16 则为大约 31 GOP。移动和嵌入式端的硬件计算能力有限,因此模型所需的计算量越大,则模型在移动端运行所需要的时间就越长。为了能让使用深度学习的应用顺畅运行,模型运算量当然是越小越好。除此之外,深度学习每次运算都是需要花费能量的,模型运算量越大则完成一次 inference 需要的能量也就越大,换句话说就是越费电。在电池量有限的移动和嵌入式端,模型一次 inference 所花费的能量必须精打细算,因此深度学习模型计算量不能太大。
如果说计算量对模型来说是最简单直接的「体重」的话,那么模型大小就是略微有些复杂和微妙的「体脂率」。深度学习模型大小主要决定的是该模型做一次 inference 所需要的能量。那么模型大小与 inference 所消耗的能量有什么关系呢?首先,我们知道,深度学习模型必须储存在内存里面,而内存其实还分为片上内存和片外内存两种。片上内存就是 SRAM cache,是处理器集成在芯片上用来快速存取重要数据的内存模块。片上内存会占据宝贵的芯片面积,因此处理器中集成的片上内存大小通常在 1-10 MB 这个数量级。片外内存则是主板上的 DDR 内存,这种内存可以做到容量很大(>1 GB),但是其访问速度较慢。

片上内存,离处理器核心电路很近,因此访问消费的能量很小

片外内存,离处理器很远,一次访问需要消耗很大能量
更关键的是,访问片外内存所需要的能量是巨大的。根据 Song Han 在论文中的估计,一次片外内存访问消耗的能量是一次乘-加法运算的 200 倍,同时也是一次访问片上内存所需能量的 128 倍。换句话说,一次片外内存访问相当于做 200 次乘法运算!
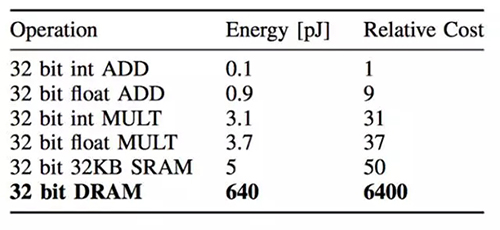
当然,具体程序中运算和内存访问消耗的能量取决于多少次运算需要一次内存存取。严格的分析方法是 roof-line model,不过我们也可以从 Google 公布的数据中去估算深度学习模型中运算次数和内存访问次数的比例。Google 在 TPU 的论文中公布了这个数据,从中可见 LSTM 模型内存访问频率***,平均 64 或 96 次计算就需要访问一次内存去取权重(weight)数据;而 CNN 模型的内存访问频率相对***,平均 2888 或 1750 次运算才访问一次内存取权重。这也很好理解,因为 CNN 充分利用了局部特征(local feature),其权重数据存在大量复用。再根据之前的计算和内存访问能量数据,如果所有的权重数据都存储在片外内存,那么两个 CNN 模型计算时运算和内存访问消耗的能量比是 2:1 和 2.5:1,而在 LSTM0 和 LSTM1 模型计算时运算和内存访问消耗的能量比是 1:10 和 1:7!也就是说在 LSTM 模型做 inference 的时候,内存访问消耗的能量占了绝大部份!
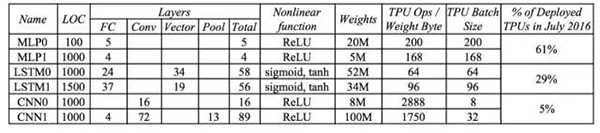
因此,我们为了减小能量消耗,必须减少片外内存访问,或者说我们需要尽可能把模型的权重数据和每层的中间运算结果存储在片上内存而非片外内存。这也是为什么 Google TPU 使用了高达 28MB 片上内存的原因。然而,移动端和嵌入式系统使用的芯片不能成本太高,因此片上内存容量很有限。这样的话我们就必须从深度学习模型大小方面想办法,尽量减小模型尺寸,让模型尽可能地能存储在片上内存,或者至少一层网络的权重数据可以存在片上内存。
3. 为模型减肥的几种方法
2016 年可谓是深度学习模型减肥元年,那一年大家在被深度学习的潜力深深折服的同时开始认真考虑如何在移动硬件上跑深度学习,于是 MIT 的 Viviene Sze 发表了***款深度学习加速芯片 Eyeriss,Bengio 发表了 Binarized Network,Rastegari 提出了 XOR-Net,Song Han 也发表了 Deep Compression,可谓是百花齐放。为模型减肥的方法可以分为两大类:***类是大幅调整模型结构(包括网络拓扑连接,运算等等),直接训练出一个结构比较苗条的模型;第二类是在已有模型的基础上小幅修改,通常不涉及重新训练(模型压缩)。
Bengio 的 Binarized Neural Network 可谓是***类模型的先驱者,将神经元 activation 限制为-1 或 1,从而极大地降低了运算量。Google 也于一个多月前发表的 MobileNet,使用了 depth-wise convolution 来降低运算量以及模型大小。Depthwise convolution 能大幅降低运算量,但是同时不同特征之间的权重参数变成线性相关。理论上减小了自由度,但是由于深度学习网络本身就存在冗余,因此实际测试中性能并没有降低很多。MobileNet 的计算量仅为 1GOP 上下,而模型大小只有 4MB 多一些,但能在 ImageNet 上实现 90% 左右的 top-5 准确率。在这条路上努力的人也很多,前不久 Face++也发表了 ShuffleNet,作为 MobileNet 的进一步进化形式也取得了更小尺寸的模型。未来我们预期会有更多此类网络诞生。

Google MobileNet 的几种模型,模型运算量大幅降低的同时 top-5 准确率降低并不多。图中 1MAC=2OP
第二种方法则是保持原有模型的大体架构,但是通过种种方法进行压缩而不用重新训练,即模型压缩。一种思路就是在数据编码上想办法。大家都知道数据在计算机系统中以二进制形式表示,传统的全精度 32-bit 浮点数可以覆盖非常大的数字范围,但是也很占内存,同时运算时硬件资源开销也大。实际上在深度学习运算中可能用不上这么高的精度,所以最简单直接的方法就是降低精度,把原来 32-bit 浮点数计算换成 16-bit 浮点数甚至 8-bit 定点数。一方面,把数据的位长减小可以大大减少模型所需的存储空间(1KB 可以存储 256 个 32-bit 浮点数,但可以存储 1024 个 8-bit 定点数),另一方面低精度的运算单元硬件实现更简单,也能跑得更快。当然,随着数据精度下降模型准确率也会随之下降,所以随之也产生了许多优化策略,比如说优化编码(原本的定点数是线性编码数字之间的间距相等,但是可以使用非线性编码在数字集中的地方使数字间的间距变小增加精度,而在数字较稀疏的地方使数字间距较大。非线性编码的方法在数字通讯重要已经有数十年的应用,8-bit 非线性编码在合适的场合可以达到接近 16-bit 线性编码的精度)等等。业界的大部分人都已经开始使用降低精度的方案,Nvidia 带头推广 16-bit 浮点数以及 8-bit 定点数计算,还推出了 Tensor RT 帮助优化精度。
除了编码优化之外,另一个方法是网络修剪(network pruning)。大家知道在深度学习网络中的神经元往往是有冗余的,不少神经元即使拿掉对精度影响也不大。网络修建就是这样的技术,在原有模型的基础上通过观察神经元的活跃程度,把不活跃的神经元删除,从而达到降低模型大小减小运算量的效果。
当然,网络修剪和编码优化可以结合起来。Song Han 发表在 2016 年 ICLR 上的 Deep Compression 就同时采用了修剪以及编码优化的方法,从而实现 35 倍的模型大小压缩。

Deep Compression 使用的模型压缩同时使用了网络修剪和编码优化
另外,训练新模型和模型压缩并不矛盾,完全可以做一个 MobileNet 的压缩版本,从而进一步改善移动端运行 MobileNet 的速度和能效比。
总结
在移动/嵌入式端运行的深度学习网络模型必须考虑运行速度以及能效比,因此模型的运算量和模型尺寸大小都是越小越好。我们可以训练新的网络拓扑以减小运算量,也可以使用网络压缩的办法改善运行性能,或者同时使用这两种办法。针对移动/嵌入式端的深度学习网络是目前的热门课题,随着边缘计算的逐渐兴起预计会有更多精彩的研究出现,让我们拭目以待。
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】

















