Apache Hadoop 软件库是一个框架,它允许使用简单的编程模型在计算机集群上对大型数据集进行分布式处理。Apache™ Hadoop® 是可靠、可扩展、分布式计算的开源软件。
该项目包括以下模块:
- Hadoop Common:支持其他 Hadoop 模块的常用工具。
- Hadoop 分布式文件系统 (HDFS™):分布式文件系统,可提供对应用程序数据的高吞吐量访问支持。
- Hadoop YARN:作业调度和集群资源管理框架。
- Hadoop MapReduce:一个基于 YARN 的大型数据集并行处理系统。
本文将帮助你逐步在 CentOS 上安装 hadoop 并配置单节点 hadoop 集群。
安装 Java
在安装 hadoop 之前,请确保你的系统上安装了 Java。使用此命令检查已安装 Java 的版本。
- java -version
- java version "1.7.0_75"
- Java(TM) SE Runtime Environment (build 1.7.0_75-b13)
- Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
要安装或更新 Java,请参考下面逐步的说明。
***步是从 Oracle 官方网站下载***版本的 java。
- cd /opt/
- wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz"
- tar xzf jdk-7u79-linux-x64.tar.gz
需要设置使用更新版本的 Java 作为替代。使用以下命令来执行此操作。
- cd /opt/jdk1.7.0_79/
- alternatives --install /usr/bin/java java /opt/jdk1.7.0_79/bin/java 2
- alternatives --config java
- There are 3 programs which provide 'java'.
- Selection Command
- -----------------------------------------------
- * 1 /opt/jdk1.7.0_60/bin/java
- + 2 /opt/jdk1.7.0_72/bin/java
- 3 /opt/jdk1.7.0_79/bin/java
- Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
现在你可能还需要使用 alternatives 命令设置 javac 和 jar 命令路径。
- alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2
- alternatives --install /usr/bin/javac javac /opt/jdk1.7.0_79/bin/javac 2
- alternatives --set jar /opt/jdk1.7.0_79/bin/jar
- alternatives --set javac /opt/jdk1.7.0_79/bin/javac
下一步是配置环境变量。使用以下命令正确设置这些变量。
设置 JAVA_HOME 变量:
- export JAVA_HOME=/opt/jdk1.7.0_79
设置 JRE_HOME 变量:
- export JRE_HOME=/opt/jdk1.7.0_79/jre
设置 PATH 变量:
- export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
安装 Apache Hadoop
设置好 java 环境后。开始安装 Apache Hadoop。
***步是创建用于 hadoop 安装的系统用户帐户。
- useradd hadoop
- passwd hadoop
现在你需要配置用户 hadoop 的 ssh 密钥。使用以下命令启用无需密码的 ssh 登录。
- su - hadoop
- ssh-keygen -t rsa
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- chmod 0600 ~/.ssh/authorized_keys
- exit
现在从官方网站 hadoop.apache.org 下载 hadoop ***的可用版本。
- cd ~
- wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
- tar xzf hadoop-2.6.0.tar.gz
- mv hadoop-2.6.0 hadoop
下一步是设置 hadoop 使用的环境变量。
编辑 ~/.bashrc,并在文件末尾添加以下这些值。
- export HADOOP_HOME=/home/hadoop/hadoop
- export HADOOP_INSTALL=$HADOOP_HOME
- export HADOOP_MAPRED_HOME=$HADOOP_HOME
- export HADOOP_COMMON_HOME=$HADOOP_HOME
- export HADOOP_HDFS_HOME=$HADOOP_HOME
- export YARN_HOME=$HADOOP_HOME
- export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
在当前运行环境中应用更改。
- source ~/.bashrc
编辑 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 并设置 JAVA_HOME 环境变量。
- export JAVA_HOME=/opt/jdk1.7.0_79/
现在,先从配置基本的 hadoop 单节点集群开始。
首先编辑 hadoop 配置文件并进行以下更改。
- cd /home/hadoop/hadoop/etc/hadoop
让我们编辑 core-site.xml。
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
接着编辑 hdfs-site.xml:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
- </property>
- </configuration>
并编辑 mapred-site.xml:
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
***编辑 yarn-site.xml:
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
现在使用以下命令格式化 namenode:
- hdfs namenode -format
要启动所有 hadoop 服务,请使用以下命令:
- cd /home/hadoop/hadoop/sbin/start-dfs.shstart-yarn.sh
要检查所有服务是否正常启动,请使用 jps 命令:
- jps
你应该看到这样的输出。
- 26049 SecondaryNameNode
- 25929 DataNode
- 26399 Jps
- 26129 JobTracker
- 26249 TaskTracker
- 25807 NameNode
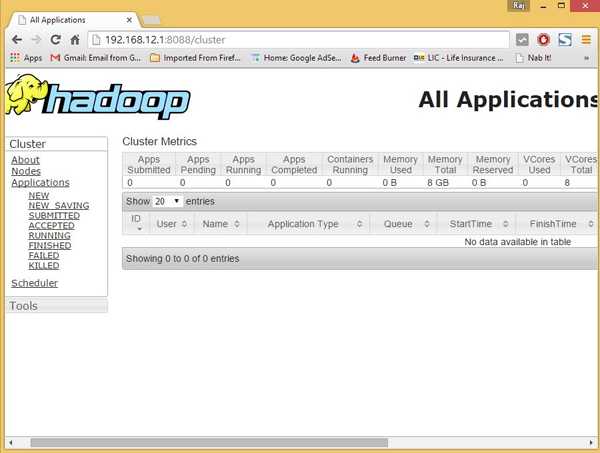
现在,你可以在浏览器中访问 Hadoop 服务:http://your-ip-address:8088/ 。
hadoop
谢谢阅读!!!