通常机器学习在电商领域有三大应用,推荐、搜索、广告,这次我们聊聊三个领域里都会涉及到的商品排序问题。从业务角度,一般是在一个召回的商品集合里,通过对商品排序,追求GMV或者点击量***化。进一步讲,就是基于一个目标,如何让流量的利用效率***。很自然的,如果我们可以准确预估每个商品的GMV转化率或者点击率,就可以***化利用流量,从而收益***。
蘑菇街是一个年轻女性垂直电商平台,主要从事服饰鞋包类目,2015年时全年GMV超过了百亿,后与美丽说合并后公司更名为美丽联合集团。2014年时入职蘑菇街,那时候蘑菇街刚刚开始尝试机器学习,这3年中经历了很多变化,打造爆款、追求效率、提升品质等等。虽然在过程中经常和业务方互相challenge,但我们的理念——技术服务于业务始终没有变化过。模型本身的迭代需配合业务目标才能发挥出***的价值,因此选择模型迭代的路线,必须全盘考虑业务的情况。
在开始前,先和大家讨论一些方法论。在点击率预估领域,常用的是有监督的模型,其中样本、特征、模型是三个绕不开的问题。首先,如何构建样本,涉及模型的目标函数是什么,即要优化什么。原则上,我们希望样本构建越接近真实场景越好。比如点击率模型常用用户行为日志作为样本,曝光过没有点击的日志是负样本,有点击的是正样本,去构建样本集,变成一个二分类。在另一个相似的领域——Learning to rank,样本构建方法可以分为三类:pointwise、pairwise、listwise。简单来讲,前面提到的构建样本方式属于pointwise范畴,即每一条样本构建时不考虑与其他样本直接的关系。但真实的场景中,往往需要考虑其他样本的影响,比如去百度搜一个关键字,会出来一系列的结果,用户的决策会受整个排序结果影响。故pairwise做了一点改进,它的样本都是由pair对组成,比如电商搜索下,商品a和商品b可以构建一个样本,如果a比b好,样本pair{a,b}是正样本,否则是负样本。
当然,这会带来新问题,比如a>b,b>c,c>a,这个时候怎么办?有兴趣的同学可以参考From RankNet to LambdaRank to LambdaMART: An Overview。而listwise就更接近真实,但复杂性也随之增加,工业界用的比较少,这里不做过多描述。理论上,样本构建方式listwise>pairwise>pointwise,但实际应用中,不一定是这个顺序。比如,你在pointwise的样本集下,模型的fit情况不是很好,比如auc不高,这个时候上pairwise,意义不大,更应该从特征和模型入手。一开始就选择pairwise或者listwise,并不是一种好的实践方式。
其次是模型和特征,不同模型对应不同的特征构建方式,比如广告的点击率预估模型,通常就有两种组合方式:采用大规模离散特征+logistic regression模型或中小规模特征+复杂模型。比如gbdt这样的树模型,就没有必要再对很多特征做离散化和交叉组合,特征规模可以小下来。很难说这两种方式哪种好,但这里有个效率问题。在工业界,机器学习工程师大部分的时间都是花在特征挖掘上,因此很多时候叫数据挖掘工程师更加合适,但这本身是一件困难且低效难以复用的工作。希望能更***干净地解决这些问题,是我们从不停地从学术界借鉴更强大的模型,虽然大部分不达预期,却不曾放弃的原因。
言归正传,下文大致是按时间先后顺序组织而成。
导购到电商
蘑菇街原来是做淘宝导购起家,在2013年转型成电商平台,刚开始的商品排序是运营和技术同学拍了一个公式,虽然很简单,但也能解决大部分问题。作为一个初创的电商平台,商家数量和质量都难以得到保障。当时公式有个买手优选的政策,即蘑菇街上主要售卖的商品都是经过公司的买手团队人工审核,一定程度上保证了平台的口碑,同时竖立平台商品的标杆。但这个方式投入很重,为了让这种模式得到***收益,必须让商家主动学习这批买手优选商品的运营模型。另一方面,从技术角度讲,系统迭代太快,导致数据链路不太可靠,且没有分布式机器学习集群。我们做了简化版的排序模型,将转化、点击、GMV表现好的一批商品作为正样本,再选择有一定曝光且表现不好的商品作为负样本,做了一个爆款模型。该模型比公式排序的GMV要提升超过10%。
从结果上,这个模型还是很成功的,仔细分析下收益的来源:对比公式,主要是它更多相关的影响因子(即它的特征),而且在它的优化目标下学到了一个***的权重分配方案。而人工设计的公式很难包含太多因素,且是拍脑袋决定权重分配。由于这个模型的目标很简单,学习商品成为爆款的可能性,因此做完常见CVR、CTR等统计特征,模型就达到了瓶颈。
做大做强,效率优先
到了2015年,平台的DAU、GMV、商家商品数都在快速膨胀,原来的模型又暴露出新的业务问题。一是该模型对目标做了很大简化,只考虑了top商品,对表现中等的商品区分度很小;二是模型本身没有继续优化的空间,auc超过了95%。这个时候,我们的数据链路和Spark集群已经准备好了。借鉴业界的经验,开始尝试转化率模型。
我们的目标是追求GMV***化。因此最直接的是对GMV转化率建模,曝光后有成交的为正样本,否则为负样本,再对正样本按price重采样,可以一定程度上模拟GMV转化率。另一种方案,用户的购买是有个决策路径的,gmv = ctr * cvr * price,取log后可以变成log(gmv) = log(ctr) + log(cvr) + log(price),一般还会对这几个目标加个权重因子。这样,问题可以拆解成点击率预估、转化率预估,***再相加。从我们的实践经验看,第二种方案的效果优于***种,主要原因在于第二种方案将问题拆解成更小的问题后,降低了模型学习的难度,用户购不购买商品的影响因素太多,***种方案对模型的要求要大于后面的。但第二种方案存在几个目标之间需要融合,带来了新的问题。可以尝试对多个模型的结果,以GMV转化率再做一次学习得到融合的方案,也可以根据业务需求,人工分配参数。
模型上我们尝试过lr和lr+xgboost。lr的转化率模型对比爆款模型转化率有8%以上的提升,lr+xgboost对比lr gmv转化率有5%以上的提升。但我们建议如果没有尝试过lr,还是先用lr去积累经验。在lr模型中,我们把主要的精力放在了特征工程上。在电商领域,特征从类型上可以分为三大种类:商品、店铺、用户。又可以按其特点分为:
- 统计类:比如点击率、转化率、商品曝光、点击、成交等,再对这些特征进行时间维度上的切割刻画,可进一步增强特征的描述力度。
- 离散类:id类特征。比如商品id、店铺id、用户id、query类id、类目id等,很多公司会直接做onehot编码,得到一个高维度的离散化稀疏特征。但这样会对模型训练、线上预测造成一定的工程压力。另一种选择是对其做编码,用一种embedding的方式去做。
- 其他类:比如文本类特征,商品详情页标题、属性词等。
常见的特征处理手段有log、平滑、离散化、交叉。根据我们的实践经验,平滑非常重要,对一些统计类的特征,比如点击率,天然是存在position bias。一个商品在曝光未充分之前,很难说是因为它本身就点击率低还是因为没有排到前面得到足够的曝光导致。因此,通过对CTR平滑的方式来增强该指标的置信度,具体选择贝叶斯平滑、拉普拉斯平滑或其他平滑手段都是可以的。这个平滑参数,大了模型退化成爆款模型,小了统计指标置信度不高,需根据当前数据分布去折中考虑。
我们借鉴了Facebook在gbdt+lr的经验,用xgboost预训练模型,将输出的叶子节点当做特征输入到lr模型中训练。实践中,需特别注意是选择合理的归一化方案避免训练和预测阶段数据分布的变化带来模型的效果的不稳定。该方案容易出现过拟合的现象,建议树的个数多一点,深度少一些。当然xgboost有很多针对过拟合的调参方案,这里不再复述。
在转化率模型取得一定成果后,开始个性化的尝试。个性化方案分为两种:
- 标签类个性化:购买力、风格、地域等。
- 行为粒度相似个性化(千人千面):推荐的思想,根据用户的行为日志,构建商品序列,对这些序列中的商品找相识的商品去rerank。常见的方法有:
- 实时偏好
- 离线偏好
- 店铺偏好
- etc
标签类个性化具有可解释高,业务合作点多等优点,而缺点是覆盖率低,整体上指标提升不明显。而行为粒度相识个性化优点是覆盖率高,刻画细致,上线后多次迭代,累计GMV提升10%。但其缺点是业务可解释性差,业务方难以使用该技术去运营。
我们的个性化方案不是直接把特征放入模型,而是将排序分为初排和精排,在精排层做个性化。这样精排可以只对topN个商品做个性化,qps有明显提升。因此在架构上,如图1,在传统的搜索引擎上层加了一个精排,设计UPS系统做为用户实时、离线特征存储模型。
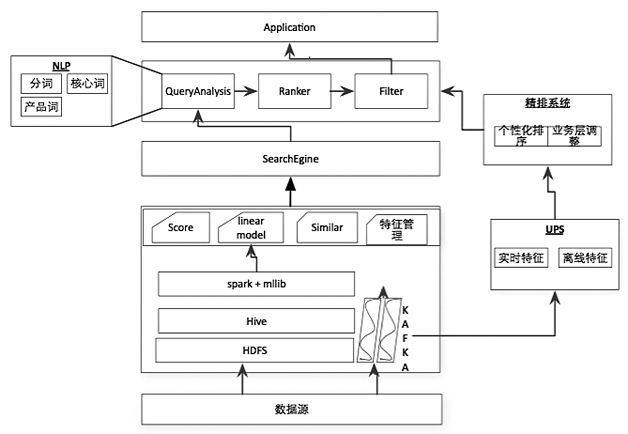
图1 个性化排序系统架构
品质升级
随着大环境消费升级的到来,公司将品质升级做为一个战略方向。模型策略的目标是帮助业务方达成目标的同时,降低损失,减少流量的浪费。通过分人群引导的方案,建立流量端和品质商品端的联系,达到在全局转化率微跌的情况下,品质商品的流量提升40%。其整体的设计方案如图2。
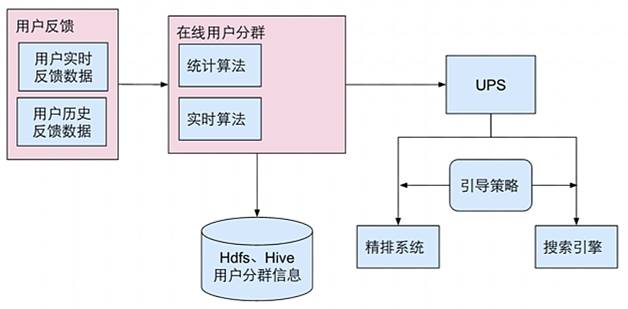
图2 实时在线人群引导算法架构
将用户的反馈分为实时和离线两种,在Spark Stream上搭建在线分群模块,***将用户群的数据存储在UPS中,在精排增加引导策略,实现对用户在线实时分群引导,其数据流如图3。
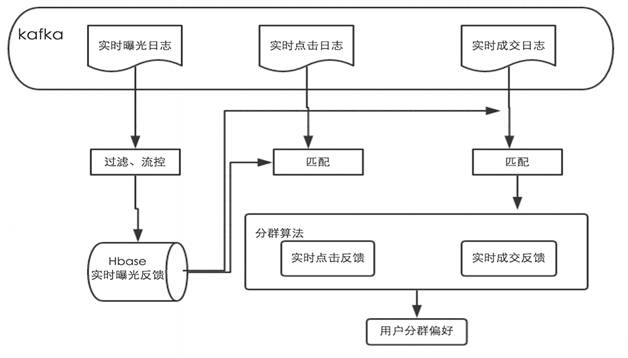
图3 实时在线人群引导数据流
从效果看,引导和非引导次日回访率随时间逐步接近,流失率也在随时间递减,说明随时间的推移,人群的分群会逐渐稳定。从全局占比看,大部分用户都是可以引导的。
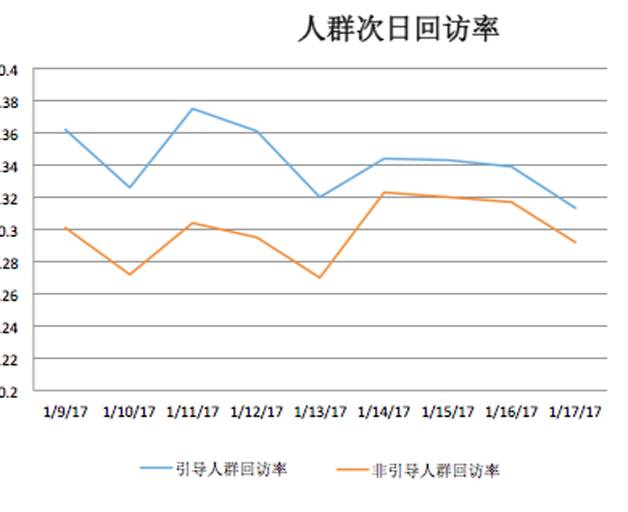
图4 人群次日回访率

图5 次日引导用户流失率
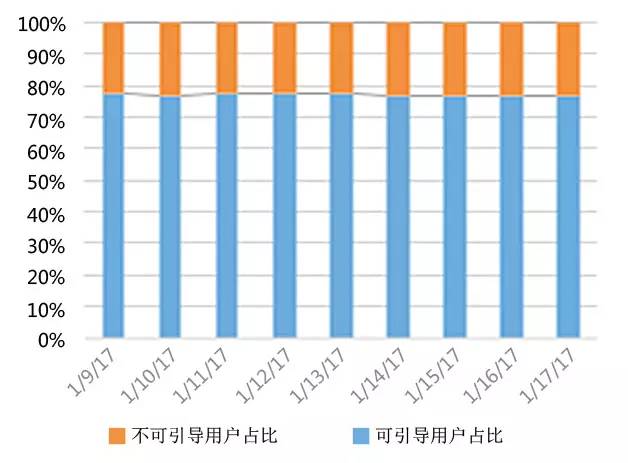
图6 人群占比统计图
未来
我们最近做了一些深度学习实验,结合百度在CTR领域的DNN实践,可以确认在电商领域应用深度学习的技术大有可为。另外,电商的业务场景天然具有导购的属性,而这正好是可以与强化学习结合,阿里在这方面已经有不少尝试。这两块后续也会是蘑菇街未来的方向。