概览
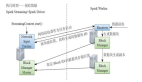
Spark Streaming是Spark API的一个可横向扩容,高吞吐量,容错的实时数据流处理引擎,Spark能够从Kafka、Flume、Kinesis或者TCP等等输入获取数据,然后能够使用复杂的计算表达式如map,reduce,join和window对数据进行计算。计算完后的数据能够被推送到文件系统,数据库,和实时的仪表盘。另外,你也可以使用Spark ML和图计算处理实时数据流。
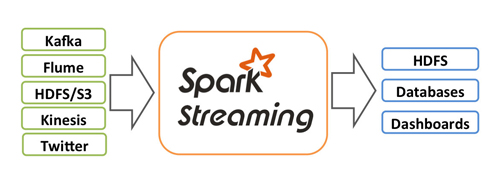
Spark Streaming接受到了实时数据后,把它们分批进行切割,然后再交给Spark进行数据的批量处理。
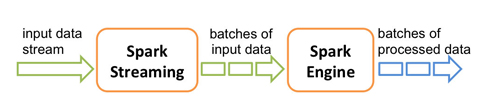
Spark Streaming对离散化的数据流提供了高级别的抽象DStream,所有进入的数据流都会被处理为DStreams,在内部,DStream是一个顺序排列的RDD。
快速起步
***个实例是如何从TCP输入中计算单词出现的次数
首先,我们创建一个JavaStreamingContext对象,它是所有Streaming函数的主入口,再创建一个带有2个线程的StreamingContext对象,每1秒进行一次批处理。
- import org.apache.spark.*;
- import org.apache.spark.api.java.function.*;
- import org.apache.spark.streaming.*;
- import org.apache.spark.streaming.api.java.*;
- import scala.Tuple2;
- SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
- JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
创建一个侦听本地9999的TCP数据源
- JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
我们把接受到的数据按照空格进行切割
- JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
对单词进行统计
- JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
- JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
- wordCounts.print();
把字符串拍扁->映射->进行去重统计,***调用print函数把数据打印到控制台中
- jssc.start(); // Start the computation
- jssc.awaitTermination(); // Wait for the computation to terminate
***,启动整个计算过程
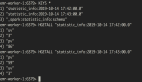
为了完成这次实验,还需要使用nc作为Server进行配合
- nc -lk 9999
Spark提供了示例,可以使用 ./bin/run-example streaming.JavaNetworkWordCount localhost 9999 来体验WordCount