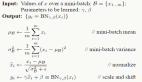神经网络在过去几年中取得了惊人的进步,现在已成为图像识别和自动翻译领域***进的技术。TensorFlow是 Google 为数字计算和神经网络发布的新框架。在这篇博文中,我们将演示如何使用 TensorFlow 和 Spark 一起来训练和应用深度学习模型。
你可能会想:当大多数高性能深度学习实现只是单节点时,Apache Spark 在这里使用什么?为了回答这个问题,我们将通过两个用例来解释如何使用 Spark 和 TensorFlow 的集群机器来改进深度学习流程:
超参数调整:使用 Spark 找到神经网络训练的***超参数,使得训练时间减少 10 倍并且错误率降低 34 %。
大规模部署模型:使用 Spark,在大量数据上应用训练后神经网络模型。
超参数调优
深度学习机器学习(ML)技术的一个例子是人工神经网络。它们采取复杂的输入,例如图像或音频记录,然后对这些信号应用复杂的数学变换。该变换的输出是数值向量,其更容易被其他 ML 算法运算。人工神经网络通过模仿人脑视觉皮质中的神经元(以简化形式)执行这种转化。
正如人类学习解释他们所看到的那样,人工神经网络需要被训练来识别「有趣」的特定模式。例如,这些可以是简单的图案,例如,边缘,圆形,但是它们可能要复杂。在这里,我们将使用由 NIST 组合的经典数据集,并训练神经网络来识别这些数字:

TensorFlow 库自动化训练各种形状和大小的神经网络算法的创建。然而,构建神经网络的实际过程比仅在数据集上运行一些函数更复杂。通常会有许多非常重要的影响模型训练效果的超参数(外行人术语中的配置参数)设置。选择正确的参数会导致高性能,而不良参数会导致训练时间长,性能不佳。在实践中,机器学习从业者用不同的超参数多次重复运行相同的模型,以便找到***超参数集。这是一种称为超参数优化的经典技术。
建立神经网络时,有很多要慎重选择的超参数。例如:
- 每层神经元数量:太少的神经元会降低网络的表达力,但太多会大大增加运行时间并返回带有噪声的估计。
- 学习率:如果太高,神经网络只会关注最近几个样本,忽视以前积累的所有经验。如果太低,达到好状态需要太长时间。
有趣的是,即使 TensorFlow 本身没有分布,超参数调整过程也是「尴尬并行」,可以使用 Spark 进行分布。在这种情况下,我们可以使用 Spark 来 broadcast 诸如数据和模型描述之类的常见元素,然后在整个机器群集之间以容错方式调度各个重复计算。
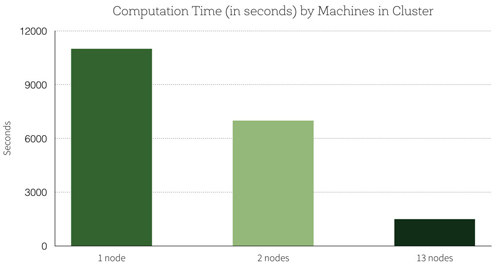
使用Spark如何提高准确性?超级参数的默认设置精度为 99.2%。通过超参数调优,在测试集上***的结果是具有 99.47% 的精度,这减少 34% 的测试误差。分配添加到集群的节点数呈线性关系的计算:使用 13 节点集群,我们能够并行训练 13 个模型,这相当于在一台机器上一次训练一个模型的 7 倍速度。以下是关于机器集群数量的计算时间(以秒为单位)的图表:
更重要的是,我们深入了解训练过程的各种训练超参数的敏感性。例如,对于不同数量的神经元,我们绘制关于学习率的最终测试性能:
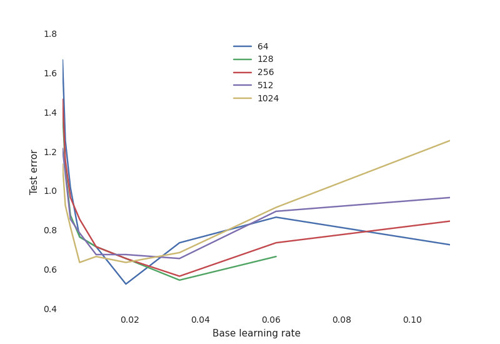
这显示了神经网络的典型权衡曲线:
- 学习率至关重要:如果太低,神经网络不会学到任何东西(高测试错误率);如果太高,在某些配置中,训练过程可能随机振荡甚至发散。
- 神经元的数量对于获得良好的性能并不重要,并且具有许多神经元的网络对于学习率更加敏感。这是奥卡姆的剃刀原理:对于大多数目标来说,更简单的模型往往都是「够好」的。如果你在缺少 1% 的测试错误率后有足够的时间和资源,你可以投入大量资源进行训练,并找到产生影响的适当的超参数。
通过使用稀疏的参数样本,我们可以对最有希望的参数集进行归零。
我该怎么用?
由于 TensorFlow 可以使用每个机器的所有核心,因此我们一次只能在每个机器运行一个任务,并将它们批处理以限制竞争。TensorFlow 库可以作为常规 Python 库安装在 Spark 集群上,遵循 TensorFlow 网站上的说明。以下笔记本显示如何安装 TensorFlow,让用户重新运行此博客的实验:
使用TensorFlow分布式处理图像
使用TensorFlow测试图像的分布处理
规模部署模型
TensorFlow 模型可以直接嵌入到管道中,以对数据集执行复杂的识别任务。例如,我们展示了如何从已经训练的股票神经网络模型中标注一组图像。
该模型首先使用 Spark 的内置 broadcasting 机制分配给集群的机器:

然后将该模型加载到每个节点上并应用于图像。这是每个节点上运行代码的草图:
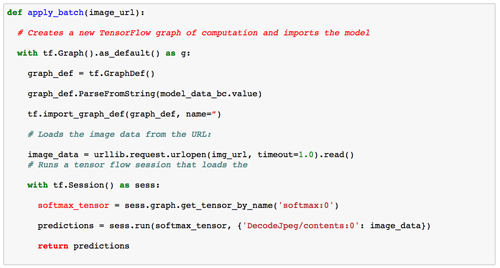
通过将图像批量化在一起,可以使此代码更有效率。
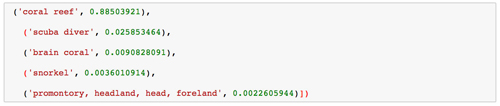
这是一个图像的例子:
这里是根据神经网络对这个图像的解释,这是非常准确的:
期待
针对手写数字识别和图像标识,我们已经展示了如何结合 Spark 和 TensorFlow 训练和部署神经网络。即使我们使用的神经网络框架本身只适用于单节点,我们可以使用 Spark 来分配超参数调整过程和模型部署。这不仅减少了训练时间,而且提高了准确度,使我们更好地了解了各种超参数的敏感性。
虽然此支持仅适用于 Python,但我们期待在 TensorFlow 和 Spark 框架的其余部分之间进行更深入的集成。