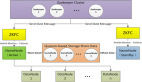
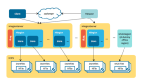
终于要开始玩大数据了,之前对haoop生态几乎没有太多的了解,现在赶鸭子上架,需要完全使用它来做数据中心,这是我的haoop***篇文章,以后估计会写很多大数据相关的文章。
Hadoop的搭建有三种方式,单机版适合开发调试;伪分布式版,适合模拟集群学习;完全分布式,生产使用的模式。这篇文件介绍如何搭建完全分布式的hadoop集群,一个主节点,三个数据节点为例来讲解。
基础环境
环境准备
1、软件版本
四台服务器配置,系统:centos6.5、内存:1G、硬盘:20G
四台服务器分配的IP地址:192.168.0.71/72/73/74
规划:71用作主节点用作hadoop-master,其它三台为数据节点72、73、74用作hadoop-salve1~3
jdk和生成保持一致使用1.7版本
hadoop使用2.7.3版本,下载地址:http://apache.claz.org/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
2、host配置和主机名(四台)
修改四台服务器的hosts文件
- vim /etc/hosts
- 192.168.0.71 hadoop-master
- 192.168.0.72 hadoop-slave1
- 192.168.0.73 hadoop-slave2
- 192.168.0.74 hadoop-slave3
分别斯塔服务器的主机名:HOSTNAME,master为例说明
- vi /etc/sysconfig/network
- HOSTNAME=hadoop-master
执行reboot后生效,完成之后依次修改其它salve服务器为: hadoop-slave1~3。
3、服务器安装jdk(四台)
建议使用yum安装jdk,也可以自行下载安装
- yum -y install java-1.7.0-openjdk*
配置环境变量,修改配置文件vim /etc/profile
- export JAVA_HOME=/usr/lib/jvm/jre-1.7.0-openjdk.x86_64
- export PATH=$JAVA_HOME/bin:$PATH
- export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使用souce命令让立刻生效
- source /etc/profile
免密登陆
一、首先关闭四台服务器的防火墙和SELINUX
查看防火墙状态
- service iptables status
关闭防火墙
- service iptables stop
- chkconfig iptables off
关闭SELINUX后,需要重启服务器
- -- 关闭SELINUX
- # vim /etc/selinux/config
- -- 注释掉
- #SELINUX=enforcing
- #SELINUXTYPE=targeted
- -- 添加
- SELINUX=disabled
二、免密码登录本机
下面以配置hadoop-master本机无密码登录为例进行讲解,用户需参照下面步骤完成h-salve1~3三台子节点机器的本机无密码登录;
1)生产秘钥
- ssh-keygen -t rsa
2)将公钥追加到”authorized_keys”文件
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3)赋予权限
- chmod 600 .ssh/authorized_keys
4)验证本机能无密码访问
- ssh hadoop-master
***,依次配置h-salve1~3无密码访问
二、hadoop-master本机无密码登录hadoop-slave1、hadoop-slave2、hadoop-slave3,以hadoop-master无密码登录hadoop-slave1为例进行讲解:
1)登录hadoop-slave1 ,复制hadoop-master服务器的公钥”id_rsa.pub”到hadoop-slave1服务器的”root”目录下。
- scp root@hadoop-master:/root/.ssh/id_rsa.pub /root/
2)将hadoop-master的公钥(id_rsa.pub)追加到hadoop-slave1的authorized_keys中
- cat id_rsa.pub >> .ssh/authorized_keys
- rm -rf id_rsa.pub
3)在 hadoop-master上面测试
- ssh hadoop-slave1
三、配置hadoop-slave1~hadoop-slave3本机无密码登录hadoop-master
下面以hadoop-slave1无密码登录hadoop-master为例进行讲解,用户需参照下面步骤完成hadoop-slave2~hadoop-slave3无密码登录hadoop-master。
1)登录hadoop-master,复制hadoop-slave1服务器的公钥”id_rsa.pub”到hadoop-master服务器的”/root/”目录下。
- scp root@hadoop-slave1:/root/.ssh/id_rsa.pub /root/
2)将hadoop-slave1的公钥(id_rsa.pub)追加到hadoop-master的authorized_keys中。
- cat id_rsa.pub >> .ssh/authorized_keys
- rm -rf id_rsa.pub //删除id_rsa.pub
3)在 hadoop-slave1上面测试
- ssh hadoop-master
依次配置 hadoop-slave2、hadoop-slave3
到此主从的无密登录已经完成了。
Hadoop环境搭建
配置hadoop-master的hadoop环境
1、hadoop-master上 解压缩安装包及创建基本目录
- #下载
- wget http://apache.claz.org/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
- #解压
- tar -xzvf hadoop-2.7.3.tar.gz -C /usr/local
- #重命名
- mv hadoop-2.7.3 hadoop
2、 配置hadoop-master的hadoop环境变量
1)配置环境变量,修改配置文件vi /etc/profile
- export HADOOP_HOME=/usr/local/hadoop
- export PATH=$PATH:$HADOOP_HOME/bin
使得hadoop命令在当前终端立即生效
- source /etc/profile
下面配置,文件都在:/usr/local/hadoop/etc/hadoop路径下
2、配置core-site.xml
修改Hadoop核心配置文件/usr/local/hadoop/etc/hadoop/core-site.xml,通过fs.default.name指定NameNode的IP地址和端口号,通过hadoop.tmp.dir指定hadoop数据存储的临时文件夹。
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/hadoop/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop-master:9000</value>
- </property>
- </configuration>
特别注意:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
3、配置hdfs-site.xml:
修改HDFS核心配置文件/usr/local/hadoop/etc/hadoop/hdfs-site.xml,通过dfs.replication指定HDFS的备份因子为3,通过dfs.name.dir指定namenode节点的文件存储目录,通过dfs.data.dir指定datanode节点的文件存储目录。
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/local/hadoop/hdfs/name</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/local/hadoop/hdfs/data</value>
- </property>
- </configuration>
4、配置mapred-site.xml
拷贝mapred-site.xml.template为mapred-site.xml,在进行修改
- cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
- vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapred.job.tracker</name>
- <value>http://hadoop-master:9001</value>
- </property>
- </configuration>
5、配置yarn-site.xml
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>hadoop-master</value>
- </property>
- </configuration>
6、配置masters文件
修改/usr/local/hadoop/etc/hadoop/masters文件,该文件指定namenode节点所在的服务器机器。删除localhost,添加namenode节点的主机名hadoop-master;不建议使用IP地址,因为IP地址可能会变化,但是主机名一般不会变化。
- vi /usr/local/hadoop/etc/hadoop/masters
- ## 内容
- hadoop-master
7、配置slaves文件(Master主机特有)
修改/usr/local/hadoop/etc/hadoop/slaves文件,该文件指定哪些服务器节点是datanode节点。删除locahost,添加所有datanode节点的主机名,如下所示。
- vi /usr/local/hadoop/etc/hadoop/slaves
- ## 内容
- hadoop-slave1
- hadoop-slave2
- hadoop-slave3
配置hadoop-slave的hadoop环境
下面以配置hadoop-slave1的hadoop为例进行演示,用户需参照以下步骤完成其他hadoop-slave2~3服务器的配置。
1)复制hadoop到hadoop-slave1节点
- scp -r /usr/local/hadoop hadoop-slave1:/usr/local/
登录hadoop-slave1服务器,删除slaves内容
- rm -rf /usr/local/hadoop/etc/hadoop/slaves
2)配置环境变量
- vi /etc/profile
- ## 内容
- export HADOOP_HOME=/usr/local/hadoop
- export PATH=$PATH:$HADOOP_HOME/bin
使得hadoop命令在当前终端立即生效;
- source /etc/profile
依次配置其它slave服务
启动集群
1、格式化HDFS文件系统
进入master的~/hadoop目录,执行以下操作
- bin/hadoop namenode -format
格式化namenode,***次启动服务前执行的操作,以后不需要执行。
2、然后启动hadoop:
- sbin/start-all.sh
3、使用jps命令查看运行情况
- #master 执行 jps查看运行情况
- 25928 SecondaryNameNode
- 25742 NameNode
- 26387 Jps
- 26078 ResourceManager
- #slave 执行 jps查看运行情况
- 24002 NodeManager
- 23899 DataNode
- 24179 Jps
4、命令查看Hadoop集群的状态
通过简单的jps命令虽然可以查看HDFS文件管理系统、MapReduce服务是否启动成功,但是无法查看到Hadoop整个集群的运行状态。我们可以通过hadoop dfsadmin -report进行查看。用该命令可以快速定位出哪些节点挂掉了,HDFS的容量以及使用了多少,以及每个节点的硬盘使用情况。
- hadoop dfsadmin -report
输出结果:
- Configured Capacity: 50108030976 (46.67 GB)
- Present Capacity: 41877471232 (39.00 GB)
- DFS Remaining: 41877385216 (39.00 GB)
- DFS Used: 86016 (84 KB)
- DFS Used%: 0.00%
- Under replicated blocks: 0
- Blocks with corrupt replicas: 0
- Missing blocks: 0
- Missing blocks (with replication factor 1): 0
- ......
5、hadoop 重启
- sbin/stop-all.sh
- sbin/start-all.sh
错误
在搭建完成启动的时候,发生过两个错误:
1、 xxx: Error: JAVA_HOME is not set and could not be found
这个错误意思没有找到jdk的环境变量,需要在hadoop-env.sh配置。
- vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
- ## 配置项
- export JAVA_HOME=/usr/lib/jvm/jre-1.7.0-openjdk.x86_64
2、The authenticity of host ‘0.0.0.0 (0.0.0.0)’ can’t be established.
解决方案关闭SELINUX
- -- 关闭SELINUX
- # vim /etc/selinux/config
- -- 注释掉
- #SELINUX=enforcing
- #SELINUXTYPE=targeted
- — 添加
- SELINUX=disabled

【本文为51CTO专栏作者“纯洁的微笑”的原创稿件,转载请通过微信公众号联系作者获取授权】