Paxos(分布式一致性算法)作为分布式系统的基石,一直都是计算机系统工程领域的热门话题。Paxos 号称是最难理解的算法,其实当真这么困难么?
X-Paxos 是阿里巴巴数据库团队面向高性能、全球部署以及阿里业务特征等需求,实现的一个高性能分布式强一致的 Paxos 独立基础库。X-Paxos 具体有哪些优势,能给现有的系统带来什么样的收益呢?
X-Paxos 的愿景:将 Paxos 带入千万家
虽然 Paxos 的理论提出已经 17 年了,从***个 Paxos 的工业实现到现在也已经 11 年了,但是直到近几年,无论是***会议,还是业内会议,与 Paxos 相关的文章和项目还是层出不穷。
转向业内,真正工业级的、独立的 Paxos 基础库还是相当的少见:
- Google 并没有开源任何 Paxos 基础库(连包含 Paxos 的项目都没有开源过)。
- Facebook 也没有公布过包含 Paxos 的产品。
- Apache 有 Zookeeper,但是其协议并不能支持一个高吞吐的状态机复制,且并没有提供独立的第三方库,可供快速接入。
- 在 Github 上,能找到的 Paxos 的独立库,star ***的是腾讯去年开源的 phxpaxos。
因此到目前为止,业内还鲜有成熟可靠的,可供快速使用的独立第三方的 Paxos 库,开源的 Paxos 生态也尚未成熟。
我们的初衷并不是要做一个 Paxos 的公共库,X-Paxos 诞生于阿里巴巴的分布式数据库 AliSQL X-Cluster,但 X-Paxos 并不属于 AliSQL X-Cluster。Paxos 是分布式系统的基石,X-Paxos 可用于解决各种各样的分布式系统中的一致性问题。
因此在整个分布式数据库的设计之初,我们就独立设计了分布式一致性协议模块,并把它独立为 X-Paxos。X-Paxos 为 AliSQL X-Cluster 解决了分布式一致性问题,同样可以快速赋予其他系统分布式一致性能力。
分布式一致性需求,并不是 AliSQL X-Cluster 所特有的,很多系统都存在着高可用和强一致的需求,我们把 Paxos 的能力独立成一个基础库,希望能够把这个能力带给其他更多的系统。
例如,团队内的同学把 X-Paxos 融入到单机 KV 数据库 RocksDB 中,快速实现了一个分布式 KV 引擎。集团已有业务团队把 X-Paxos 融入到业务存储系统中,构建全新的分布式强一致存储服务。同时也正是 AliSQL X-Cluster,成就了 X-Paxos。Google 的论文《Paxos made live》中有一段话说的很好,大意是说:Paxos 从理论到现实世界的实现之间有巨大的鸿沟,在真正实现一个 Paxos 的时候,往往需要对 Paxos 的经典理论做一些扩展。
尤其是在实现一个高性能的 Paxos 的时候,扩展点就更多了,可以参考后文的功能增强和性能优化,这往往会导致真正的 Paxos 实现都是基于一个未被完全证明的协议。这也就是传说中,理论证明一个 Paxos 的实现,比实现这个 Paxos 还要难的原因了。因此一个成熟的 Paxos 实现很难独立产生,往往需要和一个系统结合在一起,通过一个或者多个系统来验证其可靠性和完备性。这也是为什么大部分成熟的 Paxos 案例都是和分布式数据库相结合的,例如最早的 Paxos 实现(Chubby),当前的主要 Paxos 实现(Google 的 MegaStore、Spanner,AWS 的 DynamoDB、S3 等)。而 X-Paxos 正是依托于 AliSQL X-Cluster 验证了其可靠性和完备性。
我们的愿景是希望能够提供一个经过实践检验的,高度成熟可靠的独立 Paxos 基础库。使得一个后端服务能够通过简单的接入,就能拥有 Paxos 算法赋予的强一致、高可用、自动容灾等能力。真正将晦涩难懂的 Paxos,变得平易近人,带入千万家。
阿里巴巴 X-Paxos 应用实践
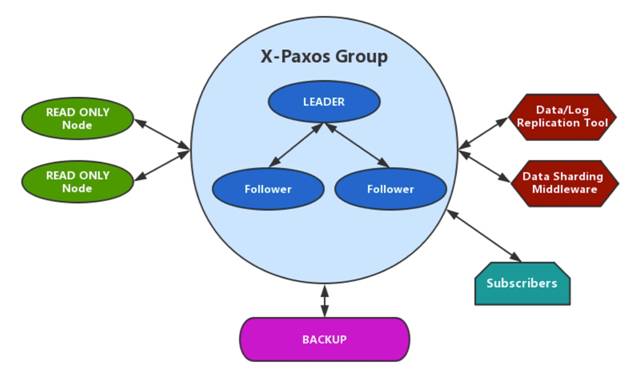
X-Paxos 的整体架构
X-Paxos 的整体架构如下图所示,主要可分为网络层、服务层、算法模块、日志模块四个部分:
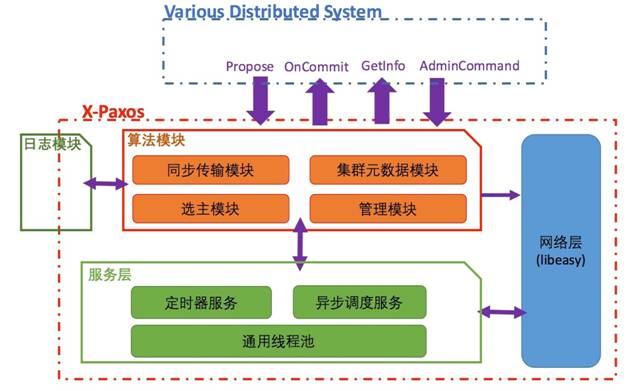
网络层
网络层基于阿里内部非常成熟的网络库 libeasy 实现。libeasy 的异步框架和线程池非常契合整体的异步化设计,同时我们对 libeasy 的重连等逻辑进行了修改,以适应分布式协议的需求。
服务层
服务层是驱动整个 Paxos 运行的基础,为 Paxos 提供了事件驱动,定时回调等核心的运行功能,每一个 Paxos 实现都有一个与之紧密相关的驱动层,驱动层的架构与性能和稳定性密切相关。
X-Paxos 的服务层是一个基于 C++11 特性实现的多线程异步框架。常见的状态机/回调模型存在开发效率较低,可读性差等问题,一直被开发者所诟病。
而协程又因其单线程的瓶颈,而使其应用场景受到限制。C++11 以后的新版本提供了***转发(argument forwarding)、可变模板参数(variadic templates)等特性,为我们能够实现一种全新的异步调用模型提供了可能。
例如,下面是 X-Paxos 内实际的一行创建单次定时任务的代码:
- new ThreadTimer(srv_->getThreadTimerService(), srv_, electionTimeout_, ThreadTimer::Oneshot,
- &Paxos::checkLeaderTransfer, this, targetId, currentTerm_.load(), log_->getLastLogIndex());
以上一行程序,包含了定时器的创建,任意回调函数的设置,回调函数参数的转发,并保证在回调触发后(Oneshot)内存的自动回收。同时服务层支持嵌套回调,即在回调函数中再一次生成一个定时/即时任务,实现一个有限次的定时循环逻辑。
算法模块
X-Paxos 当前的算法基于 unique proposer 的 multi-paxos [3] 实现,大量理论和实践已经证明了基于 unique proposer 的 multi-paxos,性能好于 multi-paxos/basic paxos,当前成熟的基于 Paxos 的系统,大部分都采用了这种方式。
算法模块的基础功能部分本文不再重复,感兴趣的同学可以参考相关论文 [1,2,4]。
在基础算法的基础上,结合阿里业务的场景以及高性能和生态的需求,X-Paxos 做了很多的创新性的功能和性能的优化,使其相对于基础的 multi-paxos,功能变的更加丰富,在多种部署场景下性能都有明显的提升。
日志模块
日志模块本是算法模块的一部分,但是出于对***性能要求的考虑,我们把日志模块独立出来,并实现了一个默认的高性能的日志模块。
有***性能以及成本需求的用户,可以结合已有的日志系统,对接日志模块接口,以获取更高的性能和更低的成本。这也是 X-Paxos 作为高性能独立库特有的优势。
X-Paxos 的功能增强
我们结合广泛的业务场景,构建开放的生态:
1. 在线添加/删除节点,在线转让 leader
X-Paxos 在标准 multi-paxos 的基础上,支持在线添加/删除多种角色的节点,支持在线快速将 leadership 节点转移到其他节点(有主选举)。
2. 策略化多数派和权重化选主
目前,阿里集团及蚂蚁金服的多地有中心的架构,很多应用因其部署的特点,往往要求它在未发生城市级容灾的情况下,仅在中心写入数据库,或调用其他分布式服务。
同时又要求在发生城市级容灾的时候(同一个城市的多个机房全部不可用),可以在完全不丢失任何数据的情况下,将写入点切换到非中心。
而经典的 multi-paxos 并不能满足这些需求。经典理论中,多数派强同步以后即可完成提交,而多数派是非特定的,并不能保证某个/某些节点一定能得到完整的数据,并激活服务。
在实际实现中,往往地理位置较近的节点会拥有强一致的数据,而地理位置较远的节点,一直处于非强一致节点,在容灾的时候永远无法激活为主节点,这样就形同虚设。
同时,当中心单节点出现故障需要容灾的时候,往往需要将主节点就近切换到同中心的另外一个节点。由于应用在多地的部署往往是非对称的原因,出现单个 Region 全挂的时候,需要将主节点切到特定的 Region 内。
这些需求都需要 Paxos 在选主的时候,可以由用户指定规则,而经典理论中同样没有类似的功能,添加权重也需要保证 Paxos 的正确性。
X-Paxos 在协议中实现了策略化多数派和权重化选主:
基于策略化多数派,用户可以通过动态配置,指定某个/某些节点必须保有强一致的数据,在出现容灾需求的时候,可以立即激活为主节点。
基于权重化选主,用户可以指定各个节点的选主权重,只有在高权重的节点全部不可用的时候,才会激活低权重的节点。
3.节点角色定制化(Proposer/Accepter/Learner 的独立配置)
在经典的 multi-paxos 实现中,一般每个节点都包含了 Proposer/Accepter/Learner 三种功能,每一个节点都是全功能节点。但是某些情况下,我们并不需要所有节点都拥有全部的功能。例如:
在经典的三个副本部署中,我们可以裁剪其中一个节点的状态机,只保留日志(无数据的纯日志节点,但是在同步中作为多数派计算),此时我们需要裁剪掉协议中的 Proposer 功能(被选举权),保留 Accepter 和 Learner 功能。
我们希望可以有若干个节点可以作为下游,订阅/消费协议产生的日志流,而不作为集群的成员(不作为多数派计算,因为这些节点不保存日志流),此时我们裁剪掉协议的 Proposer/Accepter 功能,只保留 Learner 功能。
当然还有其他的组合方式,通过对节点角色的定制化组合,我们可以开发出很多的定制功能节点,即节约了成本,又丰富了功能。
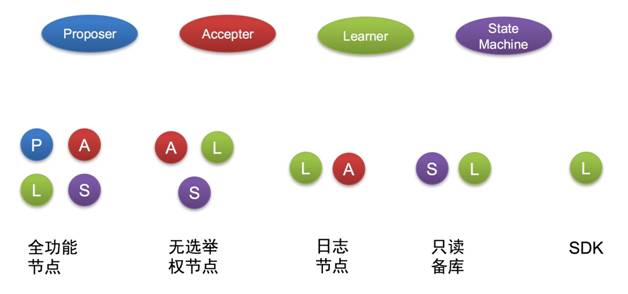
4. Witness SDK
基于上节节点角色定制化中的单独 Learner 角色的功能,引发了无穷的想象力。
Learner 角色,可以抽象成一个数据流订阅者(Witness Node),整个集群中可以加入无数个订阅者,当有新的日志被提交的时候,这些订阅者会收到他关心的日志流,基于订阅者功能。
我们可以让一个集群很容易的实现下游订阅消费,日志即时备份,配置变更推送等等的功能。
因此我们把 Learner 角色单独封装成了一个 SDK。基于这个 SDK,用户可以快速地为自己的集群添加,订阅注册,流式订阅定功能;结合特定的用途打造一个完整的生态。
例如,日志流 SDK 在 AliSQL X-Cluster 中打造的生态。如下图,采用了 X-Paxos 也可以利用 Witness SDK 快速实现分布式系统和下游的其他系统的对接,形成一个完整的生态。
我们拿 MySQL 的日志(binlog)备份来举例:
- 普通方案。每隔固定时间 Tb,将 MySQL 生成的 binlog 文件备份到***备份系统(OSS、S3 等)。RPO (Recovery Point Objective)为 Tb。
- SDK 方案。X-Paxos 支持由 SDK 订阅增量日志,备份系统只需要简单的实现从 SDK 流到 OSS 流的对接,即可实现流式备份。RPO (Recovery Point Objective)为 0。
除备份以外,Witness SDK 在下游流式订阅(DRC)、自封闭高可用系统(X-Driver)、异步只读备库等方面都有实战案例,更多的应用案例在不断的添加中。
X-Paxos 的性能优化
我们一直坚信网络延迟不应该影响吞吐。
Batching & Pipelining
Paxos 除了设计之初的强一致和高可用以外,其高性能也是至关重要的,尤其是应用于 AliSQL X-Cluster 这种高性能分布式数据库的时候,对协议的吞吐,延迟都提出了很高的要求。
同时作为可全球部署的分布式一致性协议,在高延迟下的性能挑战变得尤为重要。
X-Paxos 针对高延迟网络做了大量的协议优化尝试和测试,并结合学术界现有的理论成果 [5,6,7] 通过合理的 Batching 和 Pipelining,设计并实现了一整套自适应的针对高延迟高吞吐和低延迟高吞吐网络的通信模式。
极大的提升了 X-Paxos 的性能(对比见下节)。类似的优化在同类竞品中还非常的罕见。
Batching 是指将多个日志合并成单个消息进行发送;Batching 可以有效的降低消息粒度带来的额外损耗,提升吞吐。但是过大 Batching 容易造成单请求的延迟过大,导致并发请求数过高,继而影响了吞吐和请求延迟。
Pipelining 是指在上一个消息返回结果以前,并发的发送下一个消息到对应节点的机制,通过提高并发发送消息数量(Pipelining 数量),可以有效的降低并发单请求延迟。
同时在 transmission delay 小于 propagationdelay 的时候(高延迟高吞吐网络),有效提升性能。
经推导可知 Batching(消息大小:M)和 Pipeling(消息并发:P)在如下关系下,达到***吞吐 M/R * P = D。
其中 R 为网络带宽,D 为网络传播延迟(propagation delay,约为 RTT/2)
X-Paxos 结合以上理论,通过内置探测,针对不同节点的部署延迟,自适应的调整针对每个节点的 Batching 和 Pipeling 参数,达到整体的***吞吐。
Pipeling 的引入,需要解决日志的乱序问题,特别是在异地场景下,window 加大,加大了乱序的概率。X-Paxos 通过一个高效的乱序处理模块,可以对底层日志实现屏蔽乱序,实现高效的乱序日志存储。
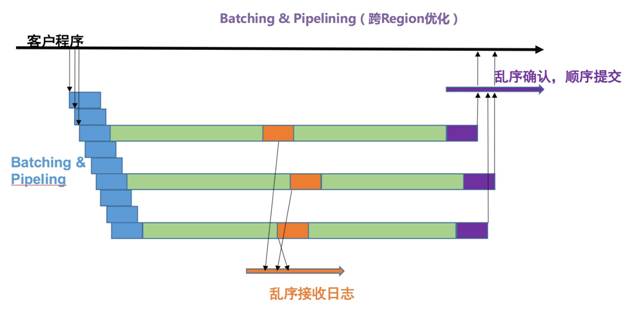
多线程,全异步的 Paxos 库
由于 Paxos 的内部状态复杂,实现高效的单实例多线程的 Paxos 变成一个非常大的挑战。无论我们上面提到的 Github 中 star 最多的 phxpaxos,还是 Oracle MySQL Group Replication 中使用的 xcom,都是单线程的实现。
phxpaxos 采用了单分区单线程,多实例聚合的方式提升总吞吐,但是对单分区的性能提升非常有限;而 xcom 是一个基于协程的单线程实现。单线程的 Paxos 实现,在处理序列化/反序列化,分发、发包等逻辑的时候都为串行执行,性能瓶颈明显。
X-Paxos 是完全基于多线程实现的,可以在单个分区 Paxos 中完全的使用多线程的能力,所有的任务都有通用的 woker 来运行,消除了 CPU 的瓶颈。
依赖于服务层的多线程异步框架和异步网络层,X-Paxos 除了必要的协议串行点外,大部分操作都可以并发执行,并且部分协议串行点采用了无锁设计,可以有效利用多线程能力,实现了 Paxos 的单分区多线程能力,单分区性能远超竞品,甚至超过了竞品的多分区性能。
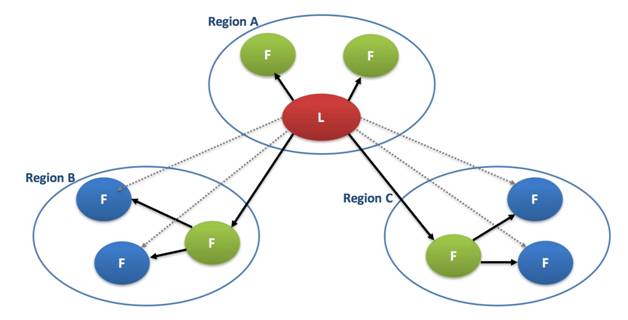
Locality Aware Content Distribution
基于 unique proposer 的分布式系统存在的一个瓶颈点就是主节点是唯一的内容输出源,当集群存在大量节点的时候,主节点的大量网络收发工作会导致主节点的负载过大,引发 CPU 和带宽的瓶颈。
在全国/全球部署的时候,所有节点和主节点之间的直接通信会造成跨 Region 之间的长传/国际链路的带宽占用过大。
X-Paxos 是旨在解决全球分布式强一致问题的 Paxos 独立库,在设计之初就考虑到了这个问题。
X-Paxos 在稳态运行时会感知各个节点之间的网络延迟(物理距离),并形成级联拓扑,有效降低主节点的负载,降低长传链路的带宽使用;而在有节点异常的时候,又会自动重组拓扑,保证各个存活节点间的同行的正常进行。
同时 X-Paxos 支持由业务来设定重组拓扑的规则,业务可以根据自己 APP 的部署架构和延迟特性来针对性的设置拓扑重组规则。
可插拔日志
X-Paxos 和现有的大部分 paxos 库很大的不同点就是 X-Paxos 支持可插拔的日志模块。日志模块是 Paxos 中一个重要的模块,它的持久化关系到数据的一致性,它的读写性能很大程度上会影响协议整体的读写性能。
当前大部分独立 Paxos 库都是内置日志模块,并且不支持插拔的。这会带来两个弊端:
默认的日志模块提供通用的功能,很难结合具体的系统做针对性的优化。
现有的系统往往已经存在了 WAL(Write Ahead Log),而 Paxos 协议中需要再存一份。这使得 a)单次 commit 本地需要 sync 2 次(影响性能);b)双份日志浪费了大量的存储。
例如,phxpaxos 内置的日志模块采用的 LevelDB,作为日志系统其操作大量冗余,无针对优化,性能堪忧。
同时采用 phxpaxos 的 phxsql 单节点需要既保存 binlog,又保存 Paxos log(在独立的 phxbinlogsvr 中),严重影响了性能,浪费了存储空间。
而采用 X-Paxos 的 AliSQL X-Cluster 直接改造了现有的 binlog 模块,对接到 X-Paxos 的日志模块,单节点仅一份日志,既降低了存储,又提高了性能。
X-Paxos 的分布式正确性验证
对于一个分布式强一致协议来说,正确性是生命线。上文已经提及,一个分布式强一致协议,很难完整的理论证明其正确性,再加上工程实现的问题,困难就更多了。
我们从理论和工程两方面用了大量的理论和技术手段来保证 X-Paxos 的正确性和完备性。
Jepsen
Jepsen 是开源社区比较公认的分布式数据库的测试框架。Jepsen 验证过程包括 VoltDB、CockroachDB、Galera、MongoDB、etcd 在内的几乎所有的主流分布式数据库/系统,检验出了不少的问题。
X-Paxos 完成了和 Jepsen 的对接,并验证了各个分布式数据库已有的 case。
TLA+
TLA+ 是 Paxos 创始人、图灵奖获得者 Leslie Lamport 发明的一种形式化规约语言。 TLA+ 专用于设计、建模和验证分布式并发系统。Amazon DynamoDB/S3/EBS 和 MicrosoftCosmos DB 都通过 TLA+ 的模型验证发现了不少问题。
X-Paxos 目前已经通过了 TLA+ 的模型验证。
随机异常系统
我们搭建了一套自动随机异常验证系统,可以自动化验证各种异常场景下的协议正确性和稳定性。验证 X-Paxos 在模拟网络丢包、闪断、隔离,磁盘故障等情况下的功能正确和数据一致。
异常回归系统
X-Paxos 拥有一套异常 case 回归系统,对于曾经出现过或者预期的并发异常 case,都会加到异常 case 库中,进行日常回归验证。同时异常 case 库也在不断的丰富中。
X-Paxos 的竞品分析和对比
XCOM (MySQL Group Replication)
MySQL GroupReplication 是 MySQL 官方借鉴 Galera 的思想,在 MySQL 上构建分布式强一致集群的一个插件。
MySQL Group Replication 早期采用的分布式协议是 CoroSync,它是由 Red Hat 开发的基于 Totem(The Totem Single-Ring Ordering and MembershipProtocol)[8] 协议开发的分布式一致性协议库。
由于 Totem 算法本身存在的一些局限性能原因,从 MySQL 5.7.9 版本以后,官方采用了自己研发的基于类 Paxos(Mencius)[10] 的一致性协议库 XCOM。
XCOM 是 MySQL Group Replication 的核心组件,称为 Group Communication Core[9]。我们分析了 XCOM 的源码,XCOM 内部是一个由纯 C 语言编译的核心模块以及由 C++ 实现的 proxy 的系统。
纯 C 模块由单线程驱动,依赖协程实现任务调度。因此 Client(MySQL GroupReplication Plugin)必须用 TCP 连接向 XCOM 发送请求。
因此 XCOM 存在如下的不足之处:
- 单线程驱动,无多线程能力。架构决定,很难突破。
- 通信流需要额外的一次 TCP 协议栈。在内存拷贝都要精细计算的应用中,线程间多一次网络通信很难接受。
- XCOM 虽然实现了 Batching 和 Pipelining,但是其值均为固定值,很难适应真实的场景。官方的文档中也提到了这一点[9]。这也使得 MySQL Group Replication 在跨 Region 场景中性能很不理想(见 AliSQL X-Cluster 对比测试)。
phxpaxos (phxsql)
phxpaxos 是腾讯推出的基于 Paxos 协议的独立库,它和 MySQL 结合后推出了 phxsql 项目,也是基于 MySQL 实现的分布式强一致 MySQL 集群。
phxpaxos 可独立用于其他项目,是目前 Github 上 star 最多(1000+)的 Paxos 独立库。关于 phxsql 的细节本文不再叙述,可以参考(AliSQL X-Cluster 的竞品分析部分),我们这里主要分析 phxpaxos。
phxpaxos 也是基于 multi-Paxos 实现的独立库,架构上采用单 Paxos 单线程设计,但是支持多 Paxos 分区以扩展多线程能力,这种扩展需要多数据进行提前分区。
因此 phxpaxos 的不足之处,如下:
单 Paxos 对象只支持单线程,可支持多 Paxos 对象,共享网络层。
不支持 pipelining,在跨 Region 环境(高延迟)下,几乎不可用。
多份日志冗余,基于 LevelDB 的日志系统性能瓶颈。
性能对比
我们还是拿腾讯的 phxpaxos 作为竞品和我们进行对比(XCOM 无独立组件,可间接参考 MySQL Group Replication 和 AliSQL X-Cluster 的对比测试结果)。
我们分别在 a) Region 内 3 节点部署 b) 3 个 Region 各一个节点部署调节下,以不同的请求大小进行压测。
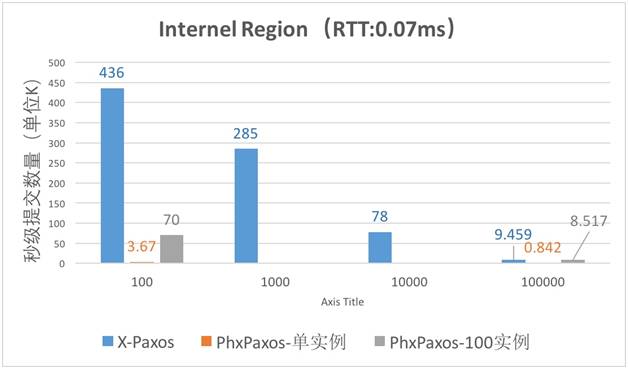
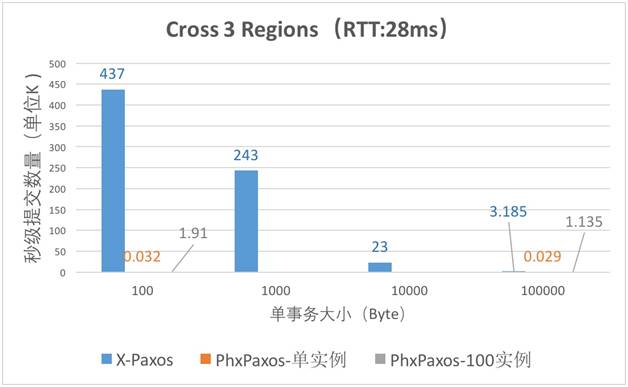
从上面两个对比图中可以看到:
- X-Paxos 的同 Region 性能是 phxpaxos 的 100 倍以上。
- 跨 Region 场景下 phxpaxos 几乎不可用,而 X-Paxos 在 444Byte(sysbench insert 场景单请求大小),性能只有 3.5% 的下降,几乎不影响吞吐。
X-Paxos的现状与未来
现状:目前 X-Paxos 一期已经发布上线。基于 X-Paxos 的集团数据库团队产品 AliSQL X-Cluster 已在集团内广泛使用。X-Paxos 和业务系统结合打造的分布式服务也相继落地上线。
未来:Paxos 是分布式系统的基石,即使是近几年,学术界关于 Paxos 的文章,新的演进方向一直在不断的涌现,我们的 X-Paxos 也会不停的发展,以更好的适应集团内外的需求。
未来主要的发展方向如下:
高效率,多分区支持。基于新的异步框架,实现一个深度底层共享的多分区 Paxos。
多节点强一致读。经典的 multi-paxos 只有在 leader 上才能提供强一致读,spanner和业界都有一些在多节点上提供强一致读的方案,但还是有比较明显的缺陷。
参考文件:
|
[1]The part-time parliament [2]The Chubby lock service for loosely-coupled distributed systems [3]Paxos Made Simple [4]Paxos Made Live - An Engineering Perspective [5]Everything You Ever Wanted to Know About Message Latency [6]Adaptive Batching for Replicated Servers [7]Tuning Paxos for high-throughput with batching and pipelining [8]The Totem single-ring ordering and membership protocol [9]Group Replication: A Journey to the Group Communication Core [10]Mencius: Building Efficient Replicated State Machines for WANs |