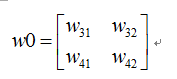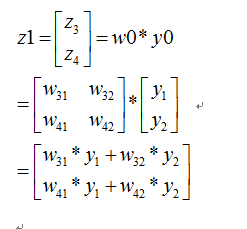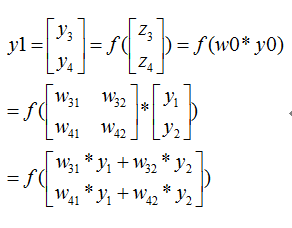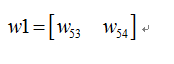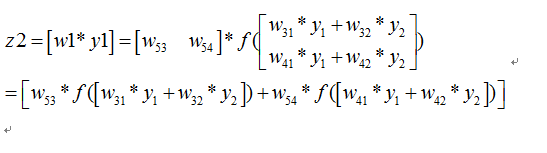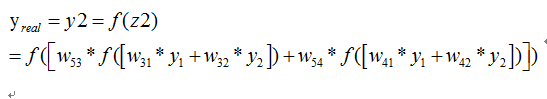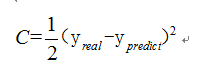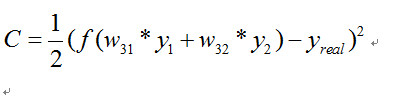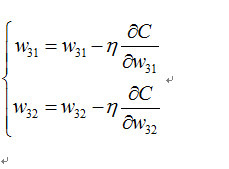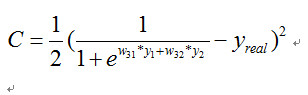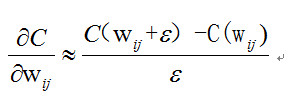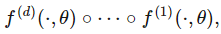在我们了解过神经网络的人中,都了解神经网络一个有很常见的训练方法,BP 训练算法。通过 BP 算法,我们可以不断的训练网络,最终使得网络可以无限的逼近一种我们想要拟合的函数,最终训练好的网络它既能在训练集上表现好,也能在测试集上表现不错!
在我们了解过神经网络的人中,都了解神经网络一个有很常见的训练方法,BP 训练算法。通过 BP 算法,我们可以不断的训练网络,最终使得网络可以无限的逼近一种我们想要拟合的函数,最终训练好的网络它既能在训练集上表现好,也能在测试集上表现不错!
那么 BP 算法具体是什么呢?为什么通过 BP 算法,我们就可以一步一步的走向最优值(即使有可能是局部最优,不是全局最优,我们也可以通过其它的方法也达到全局最优),有没有一些什么数学原理在里面支撑呢?这几天梳理了一下这方面的知识点,写下来,一是为了记录,二也可以分享给大家,防止理解错误,一起学习交流。
BP 算法具体是什么,可以参考我这篇文章知乎专栏 (详细的将 BP 过程走了一遍,加深理解),那么下面解决这个问题,为什么通过 BP 算法,就可以一步一步的走向更好的结果。首先我们从神经网络的运行原理来看,假如现在有下面这个简单的网络,如图:
<img src="https://static.leiphone.com/uploads/new/article/pic/201708/331506b19a12761324434113a569f3cc.png" data-rawwidth="675" data-rawheight="396" class="origin_image zh-lightbox-thumb" width="675" data-original="https://pic1.zhimg.com/v2-8ad20b3f51bad9e21f1b88e7bbb55744_r.png" _src="https://static.leiphone.com/uploads/new/article/pic/201708/331506b19a12761324434113a569f3cc.png"/> 我们定义符号说明如下:
我们定义符号说明如下:
<img src="https://static.leiphone.com/uploads/new/article/pic/201708/af102cbe221d16d8857bac7708dc7c38.png" data-rawwidth="743" data-rawheight="413" class="origin_image zh-lightbox-thumb" width="743" data-original="https://pic4.zhimg.com/v2-dd88143942766bae6dcf704950a6718f_r.png" _src="https://static.leiphone.com/uploads/new/article/pic/201708/af102cbe221d16d8857bac7708dc7c38.png"/> 则我们正向传播一次可以得到下面公式:
则我们正向传播一次可以得到下面公式:
<img src="https://s4.51cto.com/wyfs02/M01/9D/DD/wKiom1mH4hrglqovAAAsJJcRIX8297.png" data-rawwidth="292" data-rawheight="228" class="content_image" width="292" _src="https://s4.51cto.com/wyfs02/M01/9D/DD/wKiom1mH4hrglqovAAAsJJcRIX8297.png"/>
<img src="https://s1.51cto.com/wyfs02/M01/9D/DD/wKioL1mH4hqDLe5CAAAGC944VOc665.png" data-rawwidth="174" data-rawheight="64" class="content_image" width="174" _src="https://s1.51cto.com/wyfs02/M01/9D/DD/wKioL1mH4hqDLe5CAAAGC944VOc665.png"/>
<img src="https://s1.51cto.com/wyfs02/M00/9D/DD/wKioL1mH4hqzsmoQAAAwIXlOWdA514.png" data-rawwidth="547" data-rawheight="153" class="origin_image zh-lightbox-thumb" width="547" data-original="https://pic4.zhimg.com/v2-07a79a3e15b67058d57c1128f3640c4b_r.png" _src="https://s1.51cto.com/wyfs02/M00/9D/DD/wKioL1mH4hqzsmoQAAAwIXlOWdA514.png"/>
<img src="https://s5.51cto.com/wyfs02/M02/9D/DD/wKiom1mH4huCJ2JJAAAgWHx_Q-E162.png" data-rawwidth="547" data-rawheight="99" class="origin_image zh-lightbox-thumb" width="547" data-original="https://pic3.zhimg.com/v2-39f27335952a5ace6f496c58434c80ba_r.png" _src="https://s5.51cto.com/wyfs02/M02/9D/DD/wKiom1mH4huCJ2JJAAAgWHx_Q-E162.png"/>
如果损失函数 C 定义为
<img src="https://s5.51cto.com/wyfs02/M01/9D/DD/wKiom1mH4hvSP_KlAAAIEq2DEDs173.png" data-rawwidth="206" data-rawheight="69" class="content_image" width="206" _src="https://s5.51cto.com/wyfs02/M01/9D/DD/wKiom1mH4hvSP_KlAAAIEq2DEDs173.png"/>
那么我们希望训练出来的网络预测出来的值和真实的值越接近越好。我们先暂时不管 SGD 这种方法,最暴力的我们希望对于一个训练数据,C 能达到最小,而在 C 表达式中,我们可以把 C 表达式看做是所有 w 参数的函数,也就是求这个多元函数的最值问题。那么成功的将一个神经网络的问题引入到数学中最优化的路上了。
---------------------------分割线---------------------------
好,我们现在顺利的将一个神经网络要解决的事情转变为一个多元函数的最优化上面来了。现在的问题是怎么修改 w,来使得 C 越来越往最小值靠近呢。常见的方法我们可以采取梯度下降法(为什么梯度下降法中梯度的反方向是最快的方向,可以参考我下篇文章,不是这篇文章主旨)。可能到这还有点抽象,下面举一个特别简单的例子。
假如我们的网络非常简单,如下图(符号说明跟上面一样):
<img src="https://static.leiphone.com/uploads/new/article/pic/201708/84c0a988d8e05428a3ec5c169824b00d.png" data-rawwidth="366" data-rawheight="329" class="content_image" width="366" _src="https://static.leiphone.com/uploads/new/article/pic/201708/84c0a988d8e05428a3ec5c169824b00d.png"/> 那么我们可以得到: 那么我们可以得到:<img src="https://static.leiphone.com/uploads/new/article/pic/201708/81efeb3c9ba227b425b0c54a78efec11.png" data-rawwidth="396" data-rawheight="105" class="content_image" width="396" _src="https://static.leiphone.com/uploads/new/article/pic/201708/81efeb3c9ba227b425b0c54a78efec11.png"/>
其中<img src="https://static.leiphone.com/uploads/new/article/pic/201708/97d02f2a25bcf78362f4e20b04316cdd.png" data-rawwidth="601" data-rawheight="62" class="origin_image zh-lightbox-thumb" width="601" data-original="https://pic2.zhimg.com/v2-28fc4ccc4dd16bfdf09b0b9ea17168fd_r.png" _src="https://static.leiphone.com/uploads/new/article/pic/201708/97d02f2a25bcf78362f4e20b04316cdd.png"/>
只有 w 参数是未知的,那么 C 就可以看做是关于 w 的二元函数(二元函数的好处就是我们可以在三维坐标上将它可视化出来,便于理解~)。 图片来自于网络:
<img src="https://static.leiphone.com/uploads/new/article/pic/201708/d2f6ec1dfb62c65f9009b6498c0c9c02.jpg" data-rawwidth="660" data-rawheight="518" class="origin_image zh-lightbox-thumb" width="660" data-original="https://pic1.zhimg.com/v2-7ba7a98ed47b5ac4243cfc9b072c5cd4_r.jpg" _src="https://static.leiphone.com/uploads/new/article/pic/201708/d2f6ec1dfb62c65f9009b6498c0c9c02.jpg"/>
下面走一遍算法过程:
我们先开始随机初始化 w 参数,相当于我们可以在图上对应 A 点。
下面我们的目标是到达最低点 F 点,于是我们进行往梯度反方向进行移动,公式如下:
<img src="https://static.leiphone.com/uploads/new/article/pic/201708/8c615feed3f4d0c723a3d8b8f0a71e21.png" data-rawwidth="229" data-rawheight="169" class="content_image" width="229" _src="https://static.leiphone.com/uploads/new/article/pic/201708/8c615feed3f4d0c723a3d8b8f0a71e21.png"/> 每走一步的步伐大小由前面的学习率决定,假如下一步到了 B 点,这样迭代下去,如果全局只有一个最优点的话,我们在迭代数次后,可以到达 F 点,从而解决我们的问题。 每走一步的步伐大小由前面的学习率决定,假如下一步到了 B 点,这样迭代下去,如果全局只有一个最优点的话,我们在迭代数次后,可以到达 F 点,从而解决我们的问题。
那么好了,上面我们给出二元函数这种简单例子,从分析到最后求出结果,我们能够直观可视化最后的步骤,那么如果网络复杂后,变成多元函数的最优值求法原理是一模一样的!到此,我结束了该文要讲的知识点了。 欢迎各位朋友指错交流~
---------------------------分割线---------------------------
在我学习的时候,我已经理解了上面的知识了,但是我在思考既然我最后已经得到一个关于 w 的多元函数了,那么我为什么不直接对每一个 w 进行求偏导呢,然后直接进行更新即可,为什么神经网络的火起还需要 bp 算法的提出才复兴呢!我的疑惑就是为什么不可以直接求偏导,而必须出现 BP 算法之后才使得神经网络如此的适用呢?下面给出我的思考和理解(欢迎交流~)
1. 为什么不可以直接求导数?
在神经网络中,由于激活函数的存在,很多时候我们在最后的代价函数的时候,包含 w 参数的代价函数并不是线性函数,比如最简单的<img src="https://static.leiphone.com/uploads/new/article/pic/201708/e23ef5fe5d4f3d0cd77192101630cb0e.png" data-rawwidth="308" data-rawheight="95" class="content_image" width="308" _src="https://static.leiphone.com/uploads/new/article/pic/201708/e23ef5fe5d4f3d0cd77192101630cb0e.png"/>
这个函数对 w 进行求导是无法得到解析解的,那么说明了无法直接求导的原因。
2. 那么既然我们我们不能够直接求导,我们是否可以近似的求导呢?比如可以利用
根据这个公式我们可以近似的求出对每个参数的导数,间距越小就越接近,那么为什么不可以这样,而必须等到 BP 算法提出来的时候呢?思考中……
答:是因为计算机量的问题,假设我们的网络中有 100 万个权重,那么我们每一次算权重的偏导时候,都需要计算一遍改变值,而改变值必须要走一遍完整的正向传播。那么对于每一个训练样例,我们需要 100 万零一次的正向传播(还有一次是需要算出 C),而我们的 BP 算法求所有参数的偏导只需要一次反向传播即可,总共为俩次传播计时。到这里我想已经解决了为什么不能够用近似的办法,因为速度太慢,计算复杂度太大了~ 每一次的传播,如果参数多的话,每次的矩阵运算量非常大,以前的机器速度根本无法承受~ 所以直到有了 BP 这个利器之后,加快了神经网络的应用速度。
以上仅个人理解,感谢德川的帮助!欢迎知友提出问题交流~零基础入门深度学习 (1) - 感知器