开发人员经常说,如果你想开始机器学习,你应该首先学习算法。但是我的经验则不是。
我说你应该首先了解:应用程序如何工作。一旦了解了这一点,深入探索算法的内部工作就会变得更加容易。
那么,你如何 开发直觉学习,并实现理解机器学习这个目的?一个很好的方法是创建机器学习模型。
假设您仍然不知道如何从头开始创建所有这些算法,您可以使用一个已经为您实现所有这些算法的库。那个库是 TensorFlow。
在本文中,我们将创建一个机器学习模型来将文本分类到类别中。我们将介绍以下主题:
- TensorFlow 的工作原理
- 什么是机器学习模型
- 什么是神经网络
- 神经网络如何学习
- 如何操作数据并将其传递给神经网络
- 如何运行模型并获得预测结果
你可能会学到很多新东西,所以让我们开始吧!
TensorFlow
TensorFlow 是一个机器学习的开源库,由 Google 首创。库的名称帮助我们理解我们怎样使用它:tensors 是通过图的节点流转的多维数组。
tf.Graph
在 TensorFlow 中的每一个计算都表示为数据流图,这个图有两类元素:
- 一类 tf.Operation,表示计算单元
- 一类 tf.Tensor,表示数据单元
要查看这些是怎么工作的,你需要创建这个数据流图:
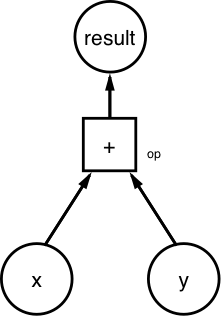
(计算x+y的图)
你需要定义 x = [1,3,6] 和 y = [1,1,1]。由于图用 tf.Tensor 表示数据单元,你需要创建常量 Tensors:
import tensorflow as tf
x = tf.constant([1,3,6])
y = tf.constant([1,1,1])
- 1.
- 2.
- 3.
- 4.
- 5.
现在你将定义操作单元:
import tensorflow as tf
x = tf.constant([1,3,6])
y = tf.constant([1,1,1])
op = tf.add(x,y)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
你有了所有的图元素。现在你需要构建图:
import tensorflow as tf
my_graph = tf.Graph()
with my_graph.as_default():
x = tf.constant([1,3,6])
y = tf.constant([1,1,1])
op = tf.add(x,y)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
这是 TensorFlow 工作流的工作原理:你首先要创建一个图,然后你才能计算(实际上是用操作‘运行’图节点)。你需要创建一个 tf.Session 运行图。
tf.Session
tf.Session 对象封装了 Operation 对象的执行环境。Tensor 对象是被计算过的(从文档中)。为了做到这些,我们需要在 Session 中定义哪个图将被使用到:
import tensorflow as tf
my_graph = tf.Graph()
with tf.Session(graph=my_graph) as sess:
x = tf.constant([1,3,6])
y = tf.constant([1,1,1])
op = tf.add(x,y)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
为了执行操作,你需要使用方法 tf.Session.run()。这个方法通过运行必要的图段去执行每个 Operation 对象并通过参数 fetches 计算每一个 Tensor 的值的方式执行 TensorFlow 计算的一’步’:
import tensorflow as tf
my_graph = tf.Graph()
with tf.Session(graph=my_graph) as sess:
x = tf.constant([1,3,6])
y = tf.constant([1,1,1])
op = tf.add(x,y)
result = sess.run(fetches=op)
print(result)
>>> [2 4 7]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
预测模型
现在你知道了 TensorFlow 的工作原理,那么你得知道怎样创建预测模型。简而言之
机器学习算法+数据=预测模型
构建模型的过程就是这样:
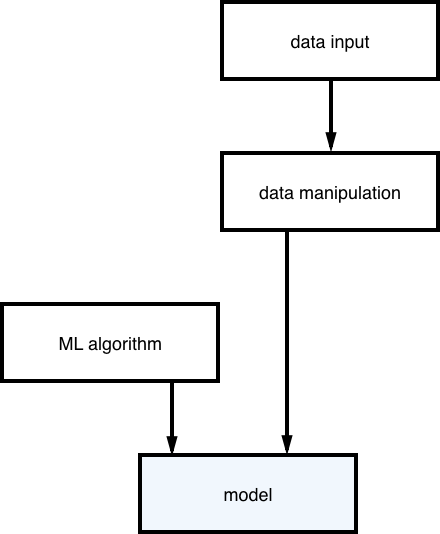
(构建预测模型的过程)
正如你能看到的,模型由数据“训练过的”机器学习算法组成。当你有了模型,你就会得到这样的结果:

(预测工作流)
你创建的模型的目的是对文本分类,我们定义了:
input: text, result: category
我们有一个使用已经标记过的文本(每个文本都有了它属于哪个分类的标记)训练的数据集。在机器学习中,这种任务的类型是被称为监督学习。
“我们知道正确的答案。该算法迭代的预测训练数据,并由老师纠正
” — Jason Brownlee
你会把数据分成类,因此它也是一个分类任务。
为了创建这个模型,我们将会用到神经网络。
神经网络
神经网络是一个计算模型(一种描述使用机器语言和数学概念的系统的方式)。这些系统是自主学习和被训练的,而不是明确编程的。
神经网络是也从我们的中枢神经系统受到的启发。他们有与我们神经相似的连接节点。
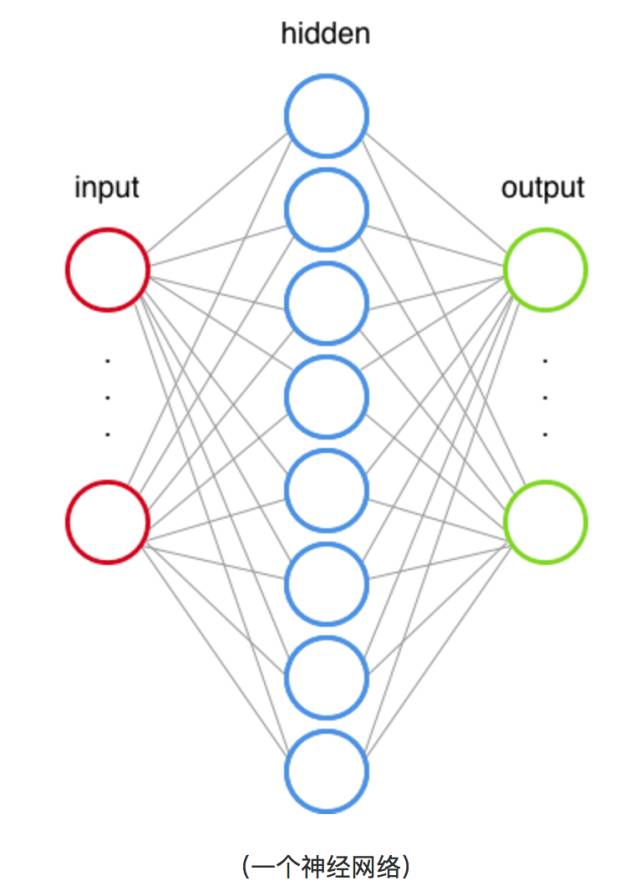
感知器是***个神经网络算法。这篇文章 很好地解释了感知器的内部工作原理(“人工神经元内部” 的动画非常棒)。
为了理解神经网络的工作原理,我们将会使用 TensorFlow 建立一个神经网络架构。在这个例子中,这个架构被 Aymeric Damien 使用过。
神经网络架构
神经网络有两个隐藏层(你得选择 网络会有多少隐藏层,这是结构设计的一部分)。每一个隐藏层的任务是 把输入的东西转换成输出层可以使用的东西。
隐藏层 1
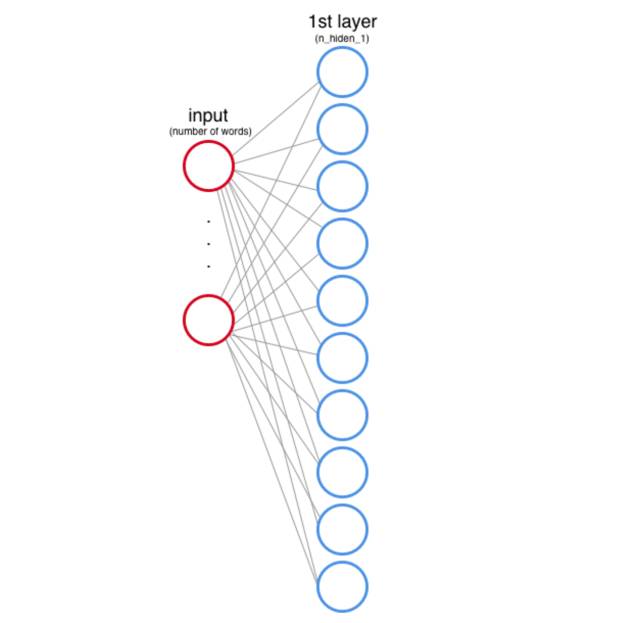
(输入层和***个隐藏层)
你也需要定义***个隐藏层会有多少节点。这些节点也被称为特征或神经元,在上面的例子中我们用每一个圆圈表示一个节点。
输入层的每个节点都对应着数据集中的一个词(之后我们会看到这是怎么运行的)
如 这里 所述,每个节点(神经元)乘以一个权重。每个节点都有一个权重值,在训练阶段,神经网络会调整这些值以产生正确的输出(过会,我们将会学习更多关于这个的信息)
除了乘以没有输入的权重,网络也会增加一个误差 (在神经网络中误差的角色)。
在你的架构中,将输入乘以权重并将值与偏差相加,这些数据也要通过激活函数传递。这个激活函数定义了每个节点的最终输出。比如说:想象一下,每一个节点是一盏灯,激活函数决定灯是否会亮。
有很多类型的激活函数。你将会使用 Rectified Linear Unit (ReLu)。这个函数是这样定义的:
f(x) = max(0,x) [输出 x 或者 0(零)中***的数]
例如:如果 x = -1, f(x) = 0(zero); 如果 x = 0.7, f(x) = 0.7.
隐藏层 2
第二个隐藏层做的完全是***个隐藏层做的事情,但现在第二层的输入是***层的输出。
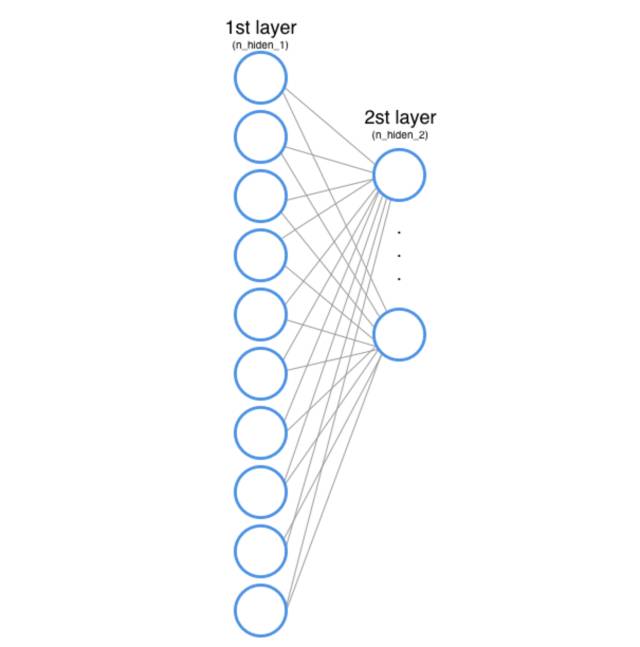
(***和第二隐藏层)
输出层
现在终于到了***一层,输出层。你将会使用 One-Hot 编码 得到这个层的结果。在这个编码中,只有一个比特的值是 1,其他比特的值都是 0。例如,如果我们想对三个分类编码(sports, space 和computer graphics)编码:
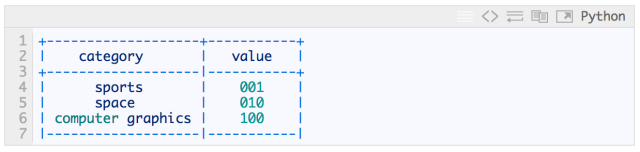
因此输出节点的编号是输入的数据集的分类的编号。
输出层的值也要乘以权重,并我们也要加上误差,但是现在激活函数不一样。
你想用分类对每一个文本进行标记,并且这些分类相互独立(一个文本不能同时属于两个分类)。考虑到这点,你将使用 Softmax 函数而不是 ReLu 激活函数。这个函数把每一个完整的输出转换成 0 和 1 之间的值,并且确保所有单元的和等于一。这样,输出将告诉我们每个分类中每个文本的概率。
| 1.2 0.46|
| 0.9 -> [softmax] -> 0.34|
| 0.4 0.20|
- 1.
- 2.
- 3.
- 4.
- 5.
现在有了神经网络的数据流图。把我们所看到的都转换为代码,结果是:
# Network Parameters
n_hidden_1 = 10 # 1st layer number of features
n_hidden_2 = 5 # 2nd layer number of features
n_input = total_words # Words in vocab
n_classes = 3 # Categories: graphics, space and baseball
def multilayer_perceptron(input_tensor, weights, biases):
layer_1_multiplication = tf.matmul(input_tensor, weights['h1'])
layer_1_addition = tf.add(layer_1_multiplication, biases['b1'])
layer_1_activation = tf.nn.relu(layer_1_addition)
# Hidden layer with RELU activation
layer_2_multiplication = tf.matmul(layer_1_activation, weights['h2'])
layer_2_addition = tf.add(layer_2_multiplication, biases['b2'])
layer_2_activation = tf.nn.relu(layer_2_addition)
# Output layer with linear activation
out_layer_multiplication = tf.matmul(layer_2_activation, weights['out'])
out_layer_addition = out_layer_multiplication + biases['out']return out_layer_addition
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
(我们将会在后面讨论输出层的激活函数)
神经网络怎么学习
就像我们前面看到的那样,神经网络训练时会更新权重值。现在我们将看到在 TensorFlow 环境下这是怎么发生的。
tf.Variable
权重和误差存储在变量(tf.Variable)中。这些变量通过调用 run() 保持在图中的状态。在机器学习中我们一般通过 正太分布 来启动权重和偏差值。
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
当我们***次运行神经网络的时候(也就是说,权重值是由正态分布定义的):
input values: x
weights: w
bias: b
output values: z
expected values: expected
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
为了知道网络是否正在学习,你需要比较一下输出值(Z)和期望值(expected)。我们要怎么计算这个的不同(损耗)呢?有很多方法去解决这个问题。因为我们正在进行分类任务,测量损耗的***的方式是 交叉熵误差。
James D. McCaffrey 写了一个精彩的解释,说明为什么这是这种类型任务的***方法。
通过 TensorFlow 你将使用 tf.nn.softmax_cross_entropy_with_logits() 方法计算交叉熵误差(这个是 softmax 激活函数)并计算平均误差 (tf.reduced_mean())。
# Construct model
prediction = multilayer_perceptron(input_tensor, weights, biases)
# Define loss
entropy_loss = tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=output_tensor)
loss = tf.reduce_mean(entropy_loss)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
你希望通过权重和误差的***值,以便最小化输出误差(实际得到的值和正确的值之间的区别)。要做到这一点,将需使用 梯度下降法。更具体些是,需要使用 随机梯度下降。
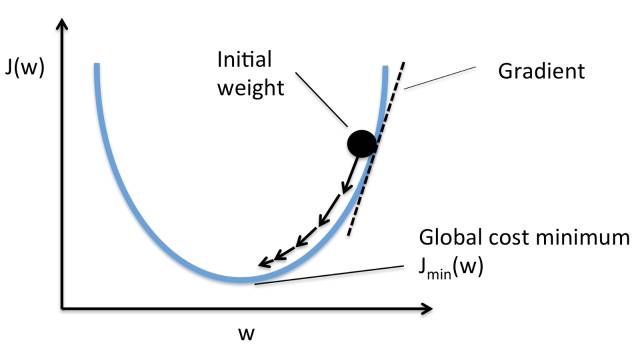
(梯度下降。源: https://sebastianraschka.com/faq/docs/closed-form-vs-gd.html)
为了计算梯度下降,将要使用 Adaptive Moment Estimation (Adam)。要在 TensorFlow 中使用此算法,需要传递 learning_rate 值,该值可确定值的增量步长以找到***权重值。
方法 tf.train.AdamOptimizer(learning_rate).minimize(loss) 是一个 语法糖,它做了两件事情:
- compute_gradients(loss, <list of variables>)
- apply_gradients(<list of variables>)
这个方法用新的值更新了所有的 tf.Variables ,因此我们不需要传递变量列表。现在你有了训练网络的代码:
learning_rate = 0.001
# Construct model
prediction = multilayer_perceptron(input_tensor, weights, biases)
# Define loss
entropy_loss = tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=output_tensor)
loss = tf.reduce_mean(entropy_loss)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
数据操作
将要使用的数据集有很多英文文本,我们需要操作这些数据将其传递给神经网络。要做到这一点,需要做两件事:
- 为每一个工作创建索引
- 为每一个文本创建矩阵,在矩阵里,如果单词在文本中则值为 1,否则值为 0
让我们看着代码来理解这个过程:
import numpy as np #numpy is a package for scientific computing
from collections import Counter
vocab = Counter()
text = "Hi from Brazil"#Get all wordsfor word in text.split(' '):
vocab[word]+=1
#Convert words to indexes
def get_word_2_index(vocab):
word2index = {} for i,word in enumerate(vocab):
word2index[word] = i
return word2index
#Now we have an index
word2index = get_word_2_index(vocab)
total_words = len(vocab)
#This is how we create a numpy array (our matrix)
matrix = np.zeros((total_words),dtype=float)
#Now we fill the valuesfor word in text.split():
matrix[word2index[word]] += 1print(matrix)
>>> [ 1. 1. 1.]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
上面例子中的文本是‘Hi from Brazil’,矩阵是 [ 1. 1. 1.]。如果文本仅是‘Hi’会怎么样?
matrix = np.zeros((total_words),dtype=float)
text = "Hi"for word in text.split():
matrix[word2index[word.lower()]] += 1print(matrix)
>>> [ 1. 0. 0.]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
将会与标签(文本的分类)相同,但是现在得使用独热编码(one-hot encoding):
y = np.zeros((3),dtype=float)if category == 0:
y[0] = 1. # [ 1. 0. 0.]
elif category == 1:
y[1] = 1. # [ 0. 1. 0.]else:
y[2] = 1. # [ 0. 0. 1.]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
运行图并获取结果
现在进入最精彩的部分:从模型中获取结果。先仔细看看输入的数据集。
数据集
对于一个有 18.000 个帖子大约有 20 个主题的数据集,将会使用到 20个新闻组。要加载这些数据集将会用到 scikit-learn 库。我们只使用 3 种类别:comp.graphics, sci.space 和 rec.sport.baseball。scikit-learn 有两个子集:一个用于训练,另一个用于测试。建议不要查看测试数据,因为这可能会在创建模型时干扰你的选择。你不会希望创建一个模型来预测这个特定的测试数据,因为你希望创建一个具有很好的泛化性能的模型。
这里是如何加载数据集的代码:
from sklearn.datasets import fetch_20newsgroups
categories = ["comp.graphics","sci.space","rec.sport.baseball"]
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
训练模型
在 神经网络的术语里,一次 epoch = 一个向前传递(得到输出的值)和一个所有训练示例的向后传递(更新权重)。
还记得 tf.Session.run() 方法吗?让我们仔细看看它:
tf.Session.run(fetches, feed_dict=None, options=None, run_metadata=None)
- 1.
在这篇文章开始的数据流图里,你用到了和操作,但是我们也可以传递一个事情的列表用于运行。在这个神经网络运行中将传递两个事情:损耗计算和优化步骤。
feed_dict 参数是我们为每步运行所输入的数据。为了传递这个数据,我们需要定义tf.placeholders(提供给 feed_dict)
正如 TensorFlow 文档中说的:
“占位符的存在只作为输入的目标,它不需要初始化,也不包含数据。” — Source
因此将要像这样定义占位符:
n_input = total_words # Words in vocab
n_classes = 3 # Categories: graphics, sci.space and baseball
input_tensor = tf.placeholder(tf.float32,[None, n_input],name="input")
output_tensor = tf.placeholder(tf.float32,[None, n_classes],name="output")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
还将要批量分离你的训练数据:
“如果为了能够输入而使用占位符,可通过使用 tf.placeholder(…, shape=[None, …]) 创建占位符来指定变量批量维度。shape 的 None 元素对应于大小可变的维度。” — Source
在测试模型时,我们将用更大的批处理来提供字典,这就是为什么需要定义一个可变的批处理维度。
get_batches() 函数为我们提供了批处理大小的文本数。现在我们可以运行模型:
training_epochs = 10# Launch the graph
with tf.Session() as sess:
sess.run(init) #inits the variables (normal distribution, remember?)
# Training cycle for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(len(newsgroups_train.data)/batch_size)
# Loop over all batches for i in range(total_batch):
batch_x,batch_y = get_batch(newsgroups_train,i,batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
c,_ = sess.run([loss,optimizer], feed_dict={input_tensor: batch_x, output_tensor:batch_y})
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
现在有了这个经过训练的模型。为了测试它,还需要创建图元素。我们将测量模型的准确性,因此需要获取预测值的索引和正确值的索引(因为我们使用的是独热编码),检查它们是否相等,并计算所有测试数据集的平均值:
# Test model
index_prediction = tf.argmax(prediction, 1)
index_correct = tf.argmax(output_tensor, 1)
correct_prediction = tf.equal(index_prediction, index_correct)
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
total_test_data = len(newsgroups_test.target)
batch_x_test,batch_y_test = get_batch(newsgroups_test,0,total_test_data)
print("Accuracy:", accuracy.eval({input_tensor: batch_x_test, output_tensor: batch_y_test}))
Epoch: 0001 loss= 1133.908114347
Epoch: 0002 loss= 329.093700409
Epoch: 0003 loss= 111.876660109
Epoch: 0004 loss= 72.552971845
Epoch: 0005 loss= 16.673050320
Epoch: 0006 loss= 16.481995190
Epoch: 0007 loss= 4.848220565
Epoch: 0008 loss= 0.759822878
Epoch: 0009 loss= 0.000000000
Epoch: 0010 loss= 0.079848485
Optimization Finished!
Accuracy: 0.75
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
就是这样!你使用神经网络创建了一个模型来将文本分类到不同的类别中。恭喜!
可在 这里(https://github.com/dmesquita/understanding_tensorflow_nn) 看到包含最终代码的笔记本。
提示:修改我们定义的值,以查看更改如何影响训练时间和模型精度。
还有其他问题或建议?留下你们的评论。谢谢阅读!