













一、前言
众所周知,深度学习在计算机视觉、自然语言处理、人工智能等领域取得了极大的进展,在安全领域也开始崭露头角走向了实际应用。本文中进行的实验主要以文本分类的方法,使用深度学习检测XSS攻击,由于本人是初学者,难免对算法本身的理解不够确切,所以本文尽量使用通俗简单的方式介绍算法,不会过多的讲解细节,以免误导大家。
二、数据集
安全领域的公开数据集非常的稀缺,本文提供的实验数据包含两个部分:从xssed爬取的黑样本作为正样例,有4万多条;另外提供约20万条正常的http get请求记录作为负样例,为了保证数据安全,去除了url中的host、path等信息,仅保留了payload的部分。
以上数据url编码后保存在csv中,由于部分原始数据进行过url编码,所以要两次url解码后才能使用。
正样例:
topic=http://gmwgroup.harvard.edu/techniques/index.php?topic=<script>alert(document.cookie)</script>
siteID=';alert(String.fromCharCode(88,83,83))//\';alert(String.fromCharCode(88,83,83))//";alert(String.fromCharCode(88,83,83))//\";alert(String.fromCharCode(88,83,83))//--></SCRIPT>">'><SCRIPT>alert(String.fromCharCode(88,83,83))</SCRIPT>
js='"--></style></script><script>alert(/meehinfected/)</script></title><marquee><h1>XSS:)</h1><marquee><strong><blink>XSSTEST</blink></strong></marquee><h1 >XSS :) </h1></marquee>
- 1.
- 2.
- 3.
负样例:
_=1498584888937/&list=FU1804,FU0,FU1707,FU1708,FU1709,FU1710,FU1711,FU1712
hid=sgpy-windows-generic-device-id&v=8.4.0.1062&brand=1&platform=6&ifbak=0&ifmobile=0&ifauto=1&type=1&filename=sgim_privilege.zip
iid=11491672248&device_id=34942737887&ac=wifi&channel=huawei&aid=13&app_name=news_article&version_code=621&version_name=6.2.1&device_platform=android&ssmix=a&device_type=FDR-A03L&device_brand=HUAWEI&language=zh&os_api=22&os_version=5.1.1&uuid=860947033207318&openudid=fc19d05187ebeb0&manifest_version_code=621&resolution=1200*1848&dpi=240&update_version_code=6214&_rticket=1498580286466
- 1.
- 2.
- 3.
三、分词
使用文本分类的方法自然涉及到如何将文本分词。观察以上正样例,人是如何辨别XSS的:参数内包含完整可执行的HTML标签和DOM方法。所以要支持的分词原则为:
单双引号包含的内容 ‘xss’
http/https链接
<>标签 <script>
<>开头 <h1
参数名 topic=
函数体 alert(
字符数字组成的单词
另外,为了减小分词数量,需要把数字和超链接范化,将数字替换为”0”,超链接替换为http://u。
实现的代码如下:
def GeneSeg(payload):
payload=payload.lower()
payload=unquote(unquote(payload))
payload,num=re.subn(r'\d+',"0",payload)
payload,num=re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?]+',"http://u", payload)
r = '''
(?x)[\w\.]+?\(
|\)
|"\w+?"
|'\w+?'
|http://\w
|</\w+>
|<\w+>
|<\w+
|\w+=
|>
|[\w\.]+
'''
return nltk.regexp_tokenize(payload,r)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
分词后的正样例:
['topic=', 'http://u', '<script>', 'alert(','document.cookie', ')', '</script>']
['siteid=', 'alert(', 'string.fromcharcode(', '0','0', '0', ')', ')', 'alert(', 'string.fromcharcode(', '0', '0', '0', ')', ')','alert(', 'string.fromcharcode(', '0', '0', '0', ')', ')', 'alert(','string.fromcharcode(', '0', '0', '0', ')', ')', '>', '</script>','>', '>', '<script>', 'alert(', 'string.fromcharcode(', '0', '0','0', ')', ')', '</script>']
['js=', '>', '</style>', '</script>','<script>', 'alert(', 'meeh', 'infected', ')', '</script>','</title>', '<marquee>', '<h0>', 'xss', ')', '</h0>','<marquee>', '<strong>', '<blink>', 'xss', 'test','</blink>', '</strong>', '</marquee>', '<h0', '>','xss', ')', '</h0>', '</marquee>']
- 1.
- 2.
- 3.
分词后的负样例:
['_=', '0', 'list=', 'fu0', 'fu0', 'fu0', 'fu0','fu0', 'fu0', 'fu0', 'fu0']
['hid=', 'sgpy', 'windows', 'generic', 'device', 'id','v=', '0.0.0.0', 'brand=', '0', 'platform=', '0', 'ifbak=', '0', 'ifmobile=','0', 'ifauto=', '0', 'type=', '0', 'filename=', 'sgim_privilege.zip']
['iid=', '0', 'device_id=', '0', 'ac=', 'wifi','channel=', 'huawei', 'aid=', '0', 'app_name=', 'news_article','version_code=', '0', 'version_name=', '0.0.0', 'device_platform=', 'android','ssmix=', 'a', 'device_type=', 'fdr', 'a0l', 'device_brand=', 'huawei','language=', 'zh', 'os_api=', '0', 'os_version=', '0.0.0', 'uuid=', '0','openudid=', 'fc0d0ebeb0', 'manifest_version_code=', '0', 'resolution=', '0','0', 'dpi=', '0', 'update_version_code=', '0', '_rticket=', '0']
- 1.
- 2.
- 3.
四、嵌入式词向量
如何将分词后的文本转化为机器学习的问题,第一步是要找到一种方法把这些词数学化。最常见的方法是独热编码(one-hot),这种方法是把词表表示为一个很长的向量,只有一个维度的值为1,其他都为0,如””””<script>”表示为[0,0,0,1,0,0,0,0…….]。这种方法存在一个重要的问题是,构成文本的向量是极其稀疏的,词与词之间是相互独立的,机器学习无法理解词的语义。嵌入式词向量就是通过学习文本来用词向量表征词的语义信息,通过将词嵌入空间使得语义相似的词在空间内的距离接近。空间向量可以表达如“话筒”和“麦克”这样的同义词,”cat”、”dog”、”fish”等词在空间中也会聚集到一起。
在这里我们要使用嵌入式词向量模型建立一个XSS的语义模型,让机器能够理解<script>、alert()这样的HTML语言。取正样例中出现次数最多的3000个词,构成词汇表,其他的词标记为“UKN”,使用gensim模块的word2vec类建模,词空间维度取128维。
核心代码:
def build_dataset(datas,words):
count=[["UNK",-1]]
counter=Counter(words)
count.extend(counter.most_common(vocabulary_size-1))
vocabulary=[c[0] for c in count]
data_set=[]
for data in datas:
d_set=[]
for word in data:
if word in vocabulary:
d_set.append(word)
else:
d_set.append("UNK")
count[0][1]+=1
data_set.append(d_set)
return data_set
data_set=build_dataset(datas,words)
model=Word2Vec(data_set,size=embedding_size,window=skip_window,negative=num_sampled,iter=num_iter)
embeddings=model.wv
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
五、数据预处理
通过建立好的词向量模型,我们就可以用空间向量表示一个文本,结合前面的过程,完整的流程如图:
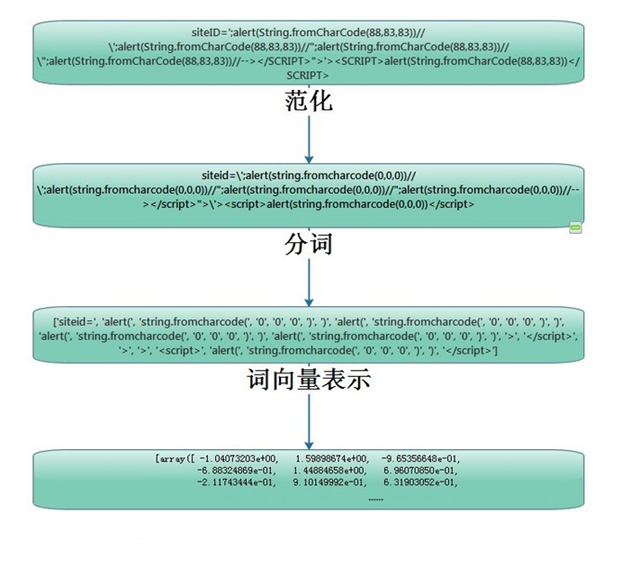
最后将全部数据随机切分为70%训练数据和30%测试数据,用于以下三个神经网络的训练和测试,代码示例:
from sklearn.model_selection import train_test_split
train_datas,test_datas,train_labels,test_labels=train_test_split(datas,labels,test_size=0.3)
- 1.
- 2.
- 3.
六、多层感知机
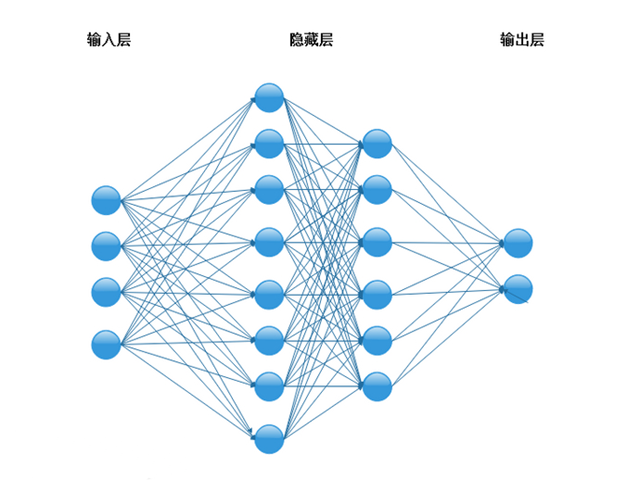
多层感知机(MLP)包含一个输入层、输出层和若干隐藏层。Keras可以使用Tensorflow作为后端轻松实现多层感知机,最终整个算法的准确率为99.9%,召回率为97.5%。核心代码如下:
模型训练:
deftrain(train_generator,train_size,input_num,dims_num):
print("Start Train Job! ")
start=time.time()
inputs=InputLayer(input_shape=(input_num,dims_num),batch_size=batch_size)
layer1=Dense(100,activation="relu")
layer2=Dense(20,activation="relu")
flatten=Flatten()
layer3=Dense(2,activation="softmax",name="Output")
optimizer=Adam()
model=Sequential()
model.add(inputs)
model.add(layer1)
model.add(Dropout(0.5))
model.add(layer2)
model.add(Dropout(0.5))
model.add(flatten)
model.add(layer3)
call=TensorBoard(log_dir=log_dir,write_grads=True,histogram_freq=1)
model.compile(optimizer,loss="categorical_crossentropy",metrics=["accuracy"])
model.fit_generator(train_generator,steps_per_epoch=train_size//batch_size,epochs=epochs_num,callbacks=[call])
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
测试:
deftest(model_dir,test_generator,test_size,input_num,dims_num,batch_size):
model=load_model(model_dir)
labels_pre=[]
labels_true=[]
batch_num=test_size//batch_size+1
steps=0
for batch,labels in test_generator:
if len(labels)==batch_size:
labels_pre.extend(model.predict_on_batch(batch))
else:
batch=np.concatenate((batch,np.zeros((batch_size-len(labels),input_num,dims_num))))
labels_pre.extend(model.predict_on_batch(batch)[0:len(labels)])
labels_true.extend(labels)
steps+=1
print("%d/%dbatch"%(steps,batch_num))
labels_pre=np.array(labels_pre).round()
def to_y(labels):
y=[]
for i in range(len(labels)):
if labels[i][0]==1:
y.append(0)
else:
y.append(1)
return y
y_true=to_y(labels_true)
y_pre=to_y(labels_pre)
precision=precision_score(y_true,y_pre)
recall=recall_score(y_true,y_pre)
print("Precision score is:",precision)
print("Recall score is:",recall)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
七、循环神经网络
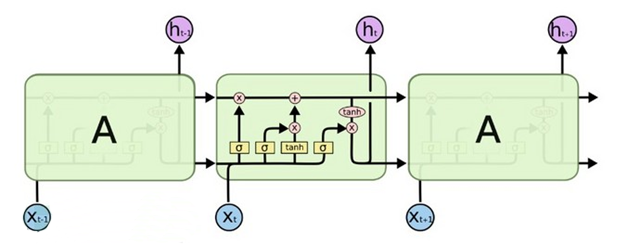
循环神经网络是一种时间递归神经网络,能够理解序列中上下文的知识,同样使用Keras建立网络,最终模型的准确率为99.5%,召回率为98.7%。核心代码:
模型训练:
def train(train_generator,train_size,input_num,dims_num):
print("Start Train Job! ")
start=time.time()
inputs=InputLayer(input_shape=(input_num,dims_num),batch_size=batch_size)
layer1=LSTM(128)
output=Dense(2,activation="softmax",name="Output")
optimizer=Adam()
model=Sequential()
model.add(inputs)
model.add(layer1)
model.add(Dropout(0.5))
model.add(output)
call=TensorBoard(log_dir=log_dir,write_grads=True,histogram_freq=1)
model.compile(optimizer,loss="categorical_crossentropy",metrics=["accuracy"])
model.fit_generator(train_generator,steps_per_epoch=train_size//batch_size,epochs=epochs_num,callbacks=[call])
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
使用tensorboard对网络的可视化:

八、卷积神经网络
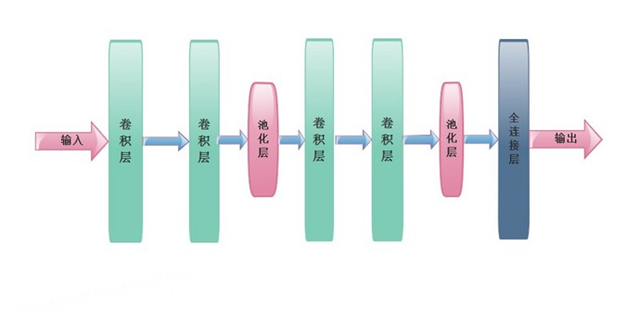
卷积神经网络(CNN)相对于MLP网络减少了需要训练的参数数量,降低了计算量,同时能够提炼深度特征进行分析,这里使用类似于Google VGG的一维卷积神经网络,包含四个卷积层、两个最大池化层、一个全连接层,最终的准确率为99.5%,召回率为98.3%,核心代码:
deftrain(train_generator,train_size,input_num,dims_num):
print("Start Train Job! ")
start=time.time()
inputs=InputLayer(input_shape=(input_num,dims_num),batch_size=batch_size)
layer1=Conv1D(64,3,activation="relu")
layer2=Conv1D(64,3,activation="relu")
layer3=Conv1D(128,3,activation="relu")
layer4=Conv1D(128,3,activation="relu")
layer5=Dense(128,activation="relu")
output=Dense(2,activation="softmax",name="Output")
optimizer=Adam()
model=Sequential()
model.add(inputs)
model.add(layer1)
model.add(layer2)
model.add(MaxPool1D(pool_size=2))model.add(Dropout(0.5))
model.add(layer3)
model.add(layer4)
model.add(MaxPool1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(layer5)
model.add(Dropout(0.5))
model.add(output)
call=TensorBoard(log_dir=log_dir,write_grads=True,histogram_freq=1)
model.compile(optimizer,loss="categorical_crossentropy",metrics=["accuracy"])
model.fit_generator(train_generator,steps_per_epoch=train_size//batch_size,epochs=epochs_num,callbacks=[call])
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
九、总结
本文介绍了如何使用嵌入式词向量建立XSS语义识别模型,并分别使用MLP、循环神经网络、卷积神经网络三种算法检测XSS攻击,三种算法都取得了不错的效果。























