此系列专栏的***篇文章《CVPR 2017论文解读:用于单目图像车辆3D检测的多任务网络》
此系列专栏的第二篇文章《CVPR 2017论文解读:特征金字塔网络FPN》
日前,CVPR 2017获奖论文公布,其中一篇***论文为康奈尔大学、清华大学、Facebook FAIR 实验室合著的《Densely Connected Convolutional Networks》。在这篇文章中,Momenta 高级研发工程师胡杰对这篇文章进行了解读。此文为该系列专栏的第三篇。
近几年来,随着卷积神经网络(CNNs)的迅速发展,学术界涌现出一大批非常高效的模型,如 GoogleNet、VGGNet、ResNet 等,在各种计算机视觉任务上均崭露头角。但随着网络层数的加深,网络在训练过程中的前传信号和梯度信号在经过很多层之后可能会逐渐消失。先前有一些非常好的工作来解决这一问题。如在 Highway 和 ResNet 结构中均提出了一种数据旁路(skip-layer)的技术来使得信号可以在输入层和输出层之间高速流通,核心思想都是创建了一个跨层连接来连通网路中前后层。在本文中,作者基于这个核心理念设计了一种全新的连接模式。为了***化网络中所有层之间的信息流,作者将网络中的所有层两两都进行了连接,使得网络中每一层都接受它前面所有层的特征作为输入。由于网络中存在着大量密集的连接,作者将这种网络结构称为 DenseNet。其结构示意图如下左图所示:

它主要拥有以下两个特性:1)一定程度上减轻在训练过程中梯度消散的问题。因为从上左图我们可以看出,在反传时每一层都会接受其后所有层的梯度信号,所以不会随着网络深度的增加,靠近输入层的梯度会变得越来越小。2)由于大量的特征被复用,使得使用少量的卷积核就可以生成大量的特征,最终模型的尺寸也比较小。
上右图所示的是构成 DenseNet 的单元模块,看上去和 ResNet 的单元模块非常相似,但实际上差异较大。我对结构设计上的细节进行了以下总结:
1)为了进行特征复用,在跨层连接时使用的是在特征维度上的 Concatenate 操作,而不是 Element-wise Addition 操作。
2)由于不需要进行 Elewise-wise 操作,所以在每个单元模块的***不需要一个 1X1 的卷积来将特征层数升维到和输入的特征维度一致。
3)采用 Pre-activation 的策略来设计单元,将 BN 操作从主支上移到分支之前。(BN->ReLU->1x1Conv->BN->ReLU->3x3Conv)
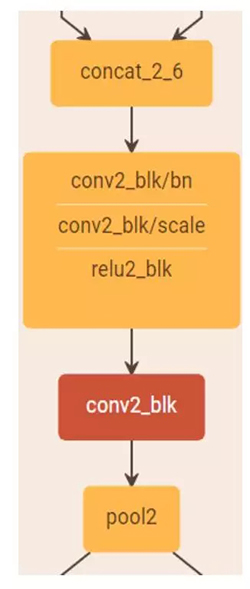
4)由于网络中每层都接受前面所有层的特征作为输入,为了避免随着网络层数的增加,后面层的特征维度增长过快,在每个阶段之后进行下采样的时候,首先通过一个卷积层将特征维度压缩至当前输入的一半,然后再进行 Pooling 的操作。如下图所示:
5)增长率的设置。增长率指的是每个单元模块***那个 3x3 的卷积核的数量,记为 k。由于每个单元模块***是以 Concatenate 的方式来进行连接的,所以每经过一个单元模块,下一层的特征维度就会增长 k。它的值越大意味着在网络中流通的信息也越大,相应地网络的能力也越强,但是整个模型的尺寸和计算量也会变大。作者在本文中使用了 k=32 和 k=48 两种设置。
作者基于以上原则针对于 ImageNet 物体识别任务分别设计了 DesNet-121(k=32)、DesNet-169(k=32)、DesNet-201(k=32) 和 DesNet-161(k=48) 四种网络结构。其网络的组织形式和 ResNet 类似,也是分为 4 个阶段,将原先的 ResNet 的单元模块进行了替换,下采样过程略有不同。整体结构设计如下所示:

在 ImageNet 上的实验结果如下:
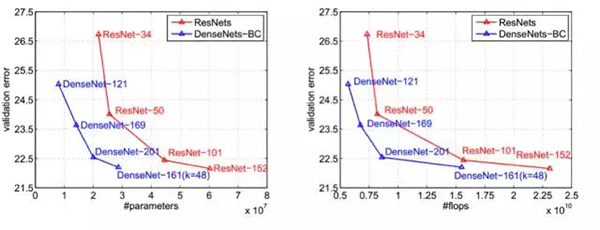
上左图表示的是参数量和错误率的关系,上右图表示的是模型测试的计算量和错误率的关系。我们不难看出,在达到相同精度时,DenseNet 的参数量和计算量均为 ResNet 的一半左右。
总的来说,这是一篇非常有创新性的工作,提出了共享特征、任意层间互连的概念很大程度上减轻了深层网络在训练过程中梯度消散而难以优化的问题,同时也减小了模型的尺寸和计算量,在标准数据集上获得了非常好的性能。唯一可能的不足是网络不能设计地特别「深」,因为随着 DenseNet 网络层数的增加,模型的特征维度会线性增长,使得在训练过程中的计算量和显存开销也会爆发地增长。
Q&A:
1.DenseNet 是否可以在物体检测任务中使用?效果如何?
A:当然,DenseNet 可以通过和 ResNet 一样的方法被应用到物体检测任务中。但是作者并没有在物体检测任务上进行实验,如果关注 DenseNet 在物体检测任务上的效果,可以参考第三方的将 DenseNet 用在物体检测任务上的实验结果。
2.通过图表可以看到,DenseNet 在相对较小计算量和相对较小的模型大小的情况下,相比同等规模的 ResNet 的准确率提升会更明显。是否说明 DenseNet 结构更加适合小模型的设计?
A:确实,在小模型的场景下 DenseNet 有更大的优势。同时,作者也和近期发表的 MobileNet 这一针对移动端和小模型设计的工作进行了对比,结果显示 DenseNet(~400MFlops)可以在更小的计算量的情况下取得比 MobileNet(~500MFlops)更高的 ImageNet 分类准确率。
3.DenseNet 中非常关键的连续的跨层 Concatenate 操作仅存在于每个 Dense Block 之内,不同 Dense Block 之间则没有这种操作,是怎样一种考虑?
A:事实上,每个 Dense Block ***的特征图已经将当前 Block 内所有的卷积模块的输出拼接在一起,整体经过降采样之后送入了下一个 Dense Block,其中已经包含了这个 Dense Block 的全部信息,这样做也是一种权衡。
4.DenseNet 这样的模型结构在训练过程中是否有一些技巧?
A:训练过程采用了和 ResNet 的文章完全相同的设定。但仍然存在一些技巧,例如因为多次 Concatenate 操作,同样的数据在网络中会存在多个复制,这里需要采用一些显存优化技术,使得训练时的显存占用可以随着层数线性增加,而非增加的更快,相关代码会在近期公布。
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】