昨日,CVPR 2017获奖论文公布,引起了业内极大的关注。但除了这些获奖论文,还有众多精彩的论文值得一读。因此在大会期间,国内自动驾驶创业公司 Momenta 联合机器之心推出CVPR 2017精彩论文解读专栏,本文是此系列专栏的***篇,作者为 Momenta 高级研发工程师贾思博。
论文:
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image

这篇文章主要处理单目图像中的车辆检测问题。车辆检测是一个经典的基于图像的目标检测问题,也是智能驾驶感知过程的核心问题之一。现有的多种目标检测框架如 Faster RCNN、YOLO 等已经可以较好地处理一般的目标检测问题,但是在应用于车辆检测时还有两个主要的痛点:(1)现有目标检测算法在平均准确率(AP)衡量下可以做到较高精度,但是目标包围框的定位(Localization)精度不够,后者对于车辆检测进一步分析有重要作用;(2)目标检测局限在图像空间中,缺乏有效算法预测车辆在真实 3D 空间中的位置和姿态。
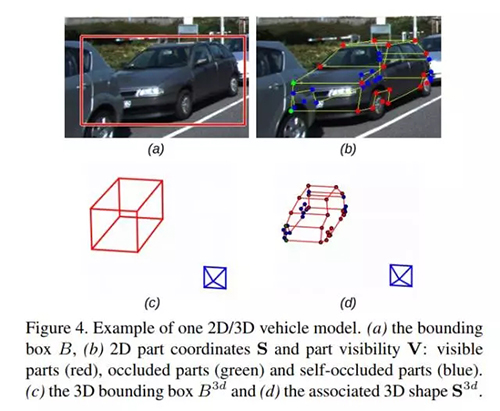
针对以上问题,作者在这篇文章中提出了一种基于单目图像检测车辆并预测 3D 信息的框架。在文章中,对于一个 3D 车辆目标的描述,包括:车辆包围立方体的位置坐标,各个部件(如车轮、车灯等)的 3D 坐标、可见性、地平面方向上的旋转角,以及车辆自身 3D 尺寸。下图是车辆建模的示意图。论文通过预测车辆自身 3D 尺寸,从标注的 3D 模型库中找到最相近的 3D 模型,进一步根据预测出的部件的 2D 坐标与 3D 模型坐标进行 PnP 匹配得到车辆的 3D 位置与姿态。
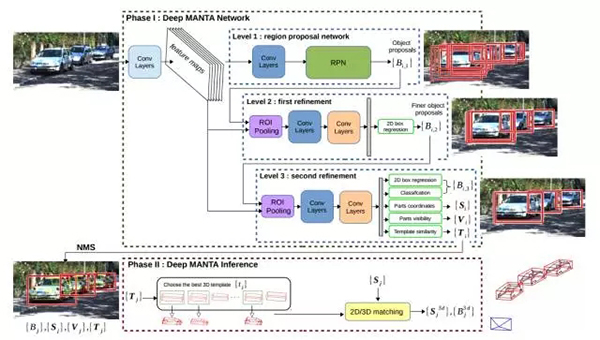
论文使用的网络结构基于 Faster RCNN 框架。新的训练方式最突出的特点有以下几点:(1)网络不仅预测车辆包围框,同时还预测车辆部件坐标、部件可见性、车辆自身尺寸等丰富的信息;(2)网络使用了级联的结构(cascade)预测以上信息,在共享底层特征(feature map)的同时提供足够的拟合能力预测多种信息,并反复回归包围框,提高定位精度;(3)在网络推测(inference)时使用上述预测的信息进行 2D/3D 匹配以得到车辆的 3D 姿态与位置信息。训练/推测过程的流程图如下图。此外,论文还提出了适合这一训练框架的标注方法,只需要标注 3D 空间下车辆的 3D 包围框,程序可以自动从 3D 模型库中找到尺寸最相近的模型,并根据姿态信息自动生成部件坐标、部件可见性。这一标注方案对于 KITTI 这类带有 3D 信息的数据集来说是很方便的。
文章使用了 103 个标准车辆 3D 模型,每个模型包含 36 个部件坐标信息。网络基础结构使用了 GoogleNet 以及 VGG16,具体训练参数详见文章第 5 节。模型在 KITTI 的车辆检测、角度回归、3D 定位任务中均达到了领先水平,验证了这一方法的有效性。
Q&A
1.在多任务网络中是如何平衡各个任务的 loss,以及如何利用部件可见性这一任务的?
A:除了部件坐标外均使用经验值 loss weight = 1,对于部件坐标尝试 loss weight = 3 时效果更佳。部件可见性主要用于辅助网络学习部件坐标信息,在 inference 中并没有用到这一信息。另外,在回归部件坐标时,对于不可见的部件关键点没有给 loss,对于可见的部件关键点给了 N_total/N_visible的 loss,即总的关键点个数比上可见的关键点个数,论文原文中没有提到这一点。
2. 在分类不同车型时,为什么回归 Template similarity 即车辆尺寸与每一个模型的尺寸比例,而不是直接回归车辆尺寸?如果有不同车型具有同样尺寸怎么办?
A:使用 Template similarity 是一个简便的提供归一化的方法,如果直接回归尺寸,对于不同的车型 scale 相差较大,效果不好。Caltech 模型库中确实有可能出现同样尺寸的情形,但从训练结果看并没有造成明显的问题。
3. 关于作者提出的「弱标注方法」,是如何标注车辆的 3D 框的?
A:KITTI 数据集中有车辆的 3D groundtruth,所以可以直接生成 3D 框数据,不需要额外标注。对于真实环境下的数据,作者正在尝试解决,现在还没有一个比较有效的方案。
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】