












kafka历史背景
Kafka是2010年Kafka是Linkedin于2010年12月份开源的消息系统,我接触的不算早,大概14年的时候,可以看看我们14年写的文章《高速总线kafka介绍》。
消息总线一直是作IT系统集成的核心概念,IBM/oracle等传统厂商都有相关中间件产品。传统消息中间件解决是消息的传输,一般支持AMQP协议来实现,如RabbitMQ。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
Kafka上来剑走偏锋,追求高吞吐量,所以特别适合,大数据的数据收集和分发等功能。高吞吐的原因核心是kafka的一些独特的涉及,包括直接使用linux cache/zero-copy/数据存放方法等,这方面的分析很多,我前面的文章《高速总线kafka介绍》第4节也简单写了下。Kafka一直缺乏一个商业公司来推动,所以发展并不是很快。几年过去了,自己看了看,还是0.10版本,特性也发展比较慢。
Kafka一直缺乏一个商业公司来推动,这个问题现在要稍稍改变一些了,原LinkedIn Kafka作者离职后创业Confluent Inc来推动kafka商业化,并推出Kafka Stream。

详细的设计理念,概念,大家看看slidershare上的PPT,讲的比较清楚,不详细展开了:https://www.slideshare.net/GuozhangWang/introduction-to-kafka-streams。
kafka stream
今天只讲kafka stream几个有意思的点:
1. 首先是定位:
比较成熟度的框架有:Apache Spark, Storm(我们公司开源Jstorm), Flink, Samza 等。第三方有:Google’s DataFlow,AWS Lambda。
1)现有框架的好处是什么?
强大计算能力,例如Spark Streaming上已经包含Graph Compute,MLLib等适合迭代计算库,在特定场景中非常好用。
2)问题是什么?
A、使用起来比较复杂,例如将业务逻辑迁移到完备的框架中,Spark RDD,Spout等。有一些工作试图提供SQL等更易使用模式降低了开发门槛,但对于个性化ETL工作(大部分ETL其实是不需要重量级的流计算框架的)需要在SQL中写UDF,流计算框架就退化为一个纯粹的容器或沙箱。
B、作者认为部署Storm,Spark等需要预留集群资源,对开发者也是一种负担。

Kafka Stream定位是轻量级的流计算类库,简单体现在什么方面?
C、所有功能放在Lib中实现,实现的程序不依赖单独执行环境
D、可以用Mesos,K8S,Yarn和Ladmda等独立调度执行Binary,试想可以通过Lamdba+Kafka实现一个按需付费、并能弹性扩展的流计算系统,是不是很cool?
E、可以在单、单线程、多线程进行支持
F、在一个编程模型中支持Stateless,Stateful两种类型计算
编程模型比较简洁,基于Kafka Consumer Lib,及Key-Affinity特性开发,代码只要处理执行逻辑就可以,Failover和规模等问题由Kafka本身特性帮助解决。
2. 设计理念和概念抽象
强调简单化,Partition中的数据到放入消费队列之前进行一定的逻辑处理(Processor Topology)提供一定的数据处理能力(api),没有Partition之间的数据交换,实现代码9K行。
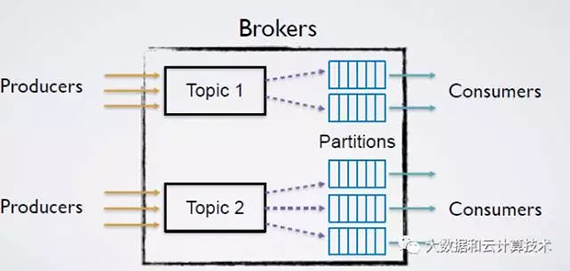
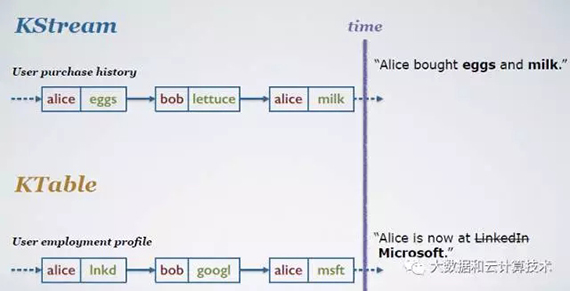
数据抽象分两种:
1)KStream:data as record stream, KStream为一个insert队列,新数据不断增加进来
2)KTable: data as change log stream, KTable为一个update队列,新数据和已有数据有相同的key,则用新数据覆盖原来的数据
后面的并发,可靠性,处理能力都是围绕这个数据抽象来搞。
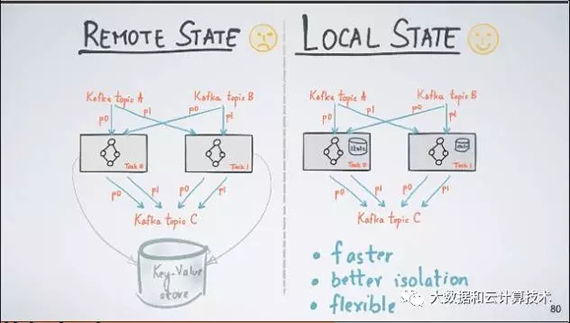
3. 支持两种处理能力

1)Stateless(无状态):例如Filter,Map,Joins,这些只要数据流过一遍即可,不依赖于前后的状态。
2)Stateful(有状态):主要是基于时间Aggregation,例如某段时间的TopK,UV等,当数据达到计算节点时需要根据内存中状态计算出数值。
Kafka Streams把这种基于流计算出来的表存储在一个本地数据库中(默认是RocksDB,但是你可以plugin其它数据库)
4. 未来支持exactly once
未来0.11版本会支持exactly once ,这是比较牛逼的能力。(提前预告)
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
1)at most once: 消费者fetch消息,保存offset,处理消息
消费者处理消息过程中出现意外,消费者恢复之后,将不能恢复处理出错的消息
2)at least once: 消费者fetch消息,处理消息,保存offset
消费者处理消息过程中出现意外,可以恢复之后再重新读取offsert处的原来的消息
3)exactly once: 确保消息唯一消费一次,这个是分布式流处理最难的部分。
“processing.guarantee=exactly_once”
这个是怎么实现的,去看看《分布式系统的一致性探讨》http://blog.jobbole.com/95618/
和《关于分布式事务、两阶段提交协议、三阶提交协议》
http://blog.jobbole.com/95632/。
5. 主要应用场景
kafka的核心应用场景还是轻量级ETL,和flink/storm更多是一个补充作用。
Building a Real-Time Streaming ETL Pipeline in 20 Minutes
https://www.confluent.io/blog/building-real-time-streaming-etl-pipeline-20-minutes/
最后希望kafka在商业公司的推动下有个更大的发展。
【本文为51CTO专栏作者“大数据和云计算”的原创稿件,转载请通过微信公众号获取联系和授权】



















