交叉路口是自动驾驶系统所面临的难点之一。今年五月,来自宾夕法尼亚大学、本田研究院和乔治亚理工学院的研究者提出了一种使用深度强化学习帮助自动驾驶汽车通过交叉路口的方法。机器之心技术分析师 Shixin Gu 对这项研究进行了解读,论文原文可访问:https://arxiv.org/abs/1705.01196
对无人汽车的研究已经不再仅仅局限于识别交通灯或交通标志的简单过程,而已经扩展到了多个生活场景中。用于衡量自动汽车的一个关键标准是看自动汽车是否能够通过没有信号的交叉路口。在这篇论文中,作者为我们提供了一种使用深度强化学习的新策略。与当前基于规则的方法相比,该方法能以一种有用的方式存储和操作知识并解读其中的信息,从而在任务完成时间和目标成功率等指标上达到更好的表现。该论文还表明,通过这个新策略使用深度强化学习可以实现更好的结果,平均成功率可以达到 99.64%,进行一次尝试的时间成功地缩短到了平均 5.5 秒。该论文也指出在提升稳健性上还需要更多努力。
1. 引言
即使是人类司机,交通事故中也有高达 20% 发生在交叉路口 [1]。这就意味着无人驾驶汽车要想学好通过交叉路口不是件容易的事。要成功通过交叉路口,需要完成三件事:1) 理解汽车的动态行为,2) 解读其他司机的意图,3) 以可被预测的方式行动以便其他司机能够合适地响应。这需要在大量有冲突的目标之间寻找平衡,其中包括安全性、效率和最小化对车流的破坏。
基于规则的处理交叉路口任务的方法主要分为两大类:协同方法(cooperative methods)[2] 和启发式方法(heuristic methods)[3]。由于需要车辆与车辆之间的通信,协同方法不能扩展用于通用的交叉路口处理。当前最佳的方法是一种基于碰撞时间(TTC/time-to-collision)[4] 的基于规则的方法。TTC 有很多优势,比如它很可靠,但也有一些局限性。首先,TTC,由于假设汽车速度恒定,所以 TTC 模型会忽略几乎所有关于司机意图的信息。其次,人类司机的不可预测的行为使得基于规则的算法用起来非常复杂。最后,有很多案例表明使用 TTC 可能过于小心谨慎,这会带来不必要的延迟。
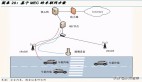
正如该论文提到的那样,用于处理交叉路口任务的机器学习方法主要有三种:模仿学习(imitation learning)、在线规划(online planning)和离线学习(offline learning)。该论文的作者选择了离线学习方法,并且也解释了模仿学习和在线规划不合适的原因。对于模仿学习而言,当其智能体处于一个其从未学习过的状态时,它就无法提供解决方案。在线规划模型则依赖于已有的准确的生成模型。图 1 给出了通过繁忙的交叉路口的过程。
图 1:通过一个繁忙的交叉路口。红色车是自动汽车,黄色车是当前交通状况。目标是确定一路上的加速方式。
2. 方法
在这一节,该论文的作者将交叉路口处理任务看作是强化学习问题。他们使用了一个深度 Q 网络(DQN)来学习状态-动作价值 Q 函数。该方法可以分为 5 个部分:
强化学习(RL):这部分是介绍强化学习,我将使用最简单的方法来描述强化学习的过程。在强化学习模型中,处在状态 st 的智能体会根据在时间 t 的策略 p 采取动作 at,然后该智能体转换到状态 st+1,并获得奖励 rt。这被形式化为了一个马尔可夫决策过程(MDP),然后使用 Q 学习来执行优化。
Q 学习:这部分介绍了 Q 学习。我推荐读者先学习一下 Q 学习,这样读这篇论文会更容易。Q 学习的本质是使用动作价值函数 Qp(s,a) 的平均值来估计实际值,而且其会随数据的增加而更新。
动态帧跳过(Dynamic Frame Skipping):动态帧跳过是选择(options)[5] 的一种简化版本,让智能体可以在更长的时间范围里选择动作,这可以改善智能体的学习时间。
经验回放优先级排序(Prioritized Experience Replay):该论文使用了经验回放来打破智能体连续步骤之间的关联。经验回放缓冲器(experience replay buffer)会保存之前的轨迹,这意味着发生频率较低的重要序列也会被采样。这将能避免排序列表的计算,平衡各种轨迹的奖励的样本可以替代这种计算。
状态-动作表征:因为自动汽车使用了传感器,所以允许大量的状态和动作表征。这篇论文提出了两种表征。第一是序列动作(sequential action),其中智能体会获得一个期望路径,然后决定选择加速、减速或保持速度。第二是 Time-to-Go,其中智能体要确定等待或出发的时间。前者让我们可以观察是否更复杂的行为就更好,后者让我们可以关注出发时间,从而让我们可以了解出发时间变化会如何影响汽车的表现。
3. 实验
在这一部分,论文作者基于各种交叉路口场景训练了两个 DQN(序列动作和 Time-to-Go)。然后他们将得到的表现与启发式 Time-to-Collision(TTC)算法进行了比较。TTC 策略使用了单个阈值来决定何时通过路口,这也是本论文分析的基准。本论文使用了 Sumo 模拟器 [6] 来运行实验。该模拟软件包可以帮助用户模拟不同场景下的各种交通情况。它可以帮助建模道路网络、道路标志、交通灯、大量汽车,而且还可以促进在线的交互和车辆控制。如图 2 所示,有 5 种不同的交叉路口场景。该论文作者给出了一系列参数来设置场景,并且还给出了 4 个评估该方法的指标:成功百分比、碰撞百分比、平均时间和平均制动时间。对于 TTC 和 Time-to-Go DQN,所有的状态表征都忽略了遮挡,并假设所有的汽车都总是可见的。
序列动作网络(sequential action network)是一个带有 leaky ReLU 激活函数的全连接网络。其中有 3 个隐藏层,每个隐藏层有 100 个节点;最后还有一个线性层,有 12 个输出,分别对应于 4 个时间尺度(1、2、4、8 个时间步骤)的 3 个动作(加速、减速和保持速度)。Time-to-Go DQN 网络使用了一个卷积神经网络,其带有两个卷积层和一个全连接层。第一个卷积层有 32 个 6×6 的滤波器,步幅为 2;第二个卷积层有 64 个 3×3 的滤波器,步幅也为 2;全连接层有 100 个节点。所有层都使用了 leaky ReLU 激活函数。最后的线性输出层有 5 个输出:一个 go 动作和 4 个时间尺度(1、2、4、8 个时间步骤)的 wait 动作。在本实验中,经验回放缓冲器可存储 100,000 个时间步骤,并且有两个缓冲器,一个用于碰撞,另一个用于成功和超时。对于奖励,该论文使用 +1 表示成功,-10 表示碰撞,-0.01 用于步骤成本。

图 2:不同交叉路口场景的可视化
4. 结果

表 1:不同算法的比较
结果可见于表 1、图 3、图 4,我们可以看到以下结果:
(1)TTC 方法在任何场景下都没有碰撞。在 DQN 方法中,DQN Time-to-Go 有比 DQN-sequential 远远更低的碰撞率。
(2)与 TTC 相比,DQN 方法在实现目标上要有效得多。平均而言,DQN Time-to-Go 在实现目标上比 TTC 快 28%,DQN Sequential 比 TTC 快 19%。这意味着 DQN 方法有减少交通堵塞的潜力。
(3)除了一个案例外,DQN Time-to-Go 有最高的几率得到最好的结果,参见图 3.

图 3:所有方法和场景的结果比较
(4)尽管 DQN 方法显著更高效,但它们并不如 TTC 一样善于最小化碰撞次数。
(5)在图 4 中,我们可以看到当论文作者在速度与安全性之间寻求权衡时,DQN 的表现超越了 TTC 的表现。这说明设计一个 0 碰撞率的算法是可能的。

图 4:随着 TTC 的阈值变化,通过时间与碰撞率的权衡
注意 DQN 的表现在每个案例中都最好。由于尺度原因,高难度场景没有包括进来,但结果是类似的。
由于 DQN 没有实现 0% 的碰撞率,所以该论文作者尝试寻找解决这一问题的方法,因为 0 碰撞率是非常重要的。根据多任务学习 [7] 的核心原理,作者认为在多场景上训练可以提升表现。图 5 给出了迁移表现,具体数据参见表 2 和表 3,这将有助于作者理解深度网络系统的泛化方式。我们可以看到更有难度的场景可以迁移到更容易的场景,但车道数量的变化会带来干扰。

图 5:迁移表现。在一个场景中训练的网络在不同的场景中运行,以评估每种方法的泛化能力。

表 2:DQN Sequential 的迁移表现;表 3:DQN Time-to-Go 的迁移表现
然后论文作者给出了一个定性分析。在该分析中,作者指出该 DQN 可以准确预测远处车道在当前车辆通过该车道时的交通状况。另外该 DQN 司机还能预测即将到来的车流是否有足够的时间制动。作者还解释了会有一些碰撞的原因。这种由离散化(discretization)导致的碰撞会在汽车几乎错过即将到来的车流时产生影响。论文还指出 TTC 往往会等到道路完全清空后才通过,如图 6 所示,这种方法在实际情况下是不够好的。

图 6:DQN Time-to-Go 预测开阔空间出现的时机,然后开始按预期的明确路径加速。TTC 会等到所有车都走过,但这会错失机会。
5. 结论
对于这篇论文,作者提到了三个贡献。第一个贡献是将当前多种深度学习技术结合起来提升水平的全新思想。第二个贡献是在 5 个不同的交叉路口模拟场景中将 DQN 与 TTC 的表现进行了比较分析。第三个贡献是分析了训练后的 DQN 策略迁移到不同场景的能力。
在我看来,未来还有两个方面有待提升。一是卷积神经网络的架构。有更多的复杂场景时,更深度的神经网络可以得到更好的结果。我们可以在参考文献 [8] 中找到同样的结论,有一家自动驾驶公司将深度学习看作是打造可信赖的无人驾驶汽车的唯一可行方式,因为驾驶涉及到的情况太多了,而且很多事情都很艰难和微妙。另一个方面是关于碰撞率。我认为应该还有另一种让碰撞率为 0 的方法,因为在人类选择无人驾驶汽车时,安全性无疑是最重要的部分。这里只是通过这个模型或算法还不能实现这个目标,应该还有其它解决这个问题的方式。在奥迪汽车中,工程师应用了毫米波雷达、激光雷达、相机、超声波探头等等设备来互相补偿和验证,这可以帮助汽车做出正确的选择
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】