时下流行什么react, avalon, angular, vue什么,其核心都离不开前端模板。理解前端模板,是我们了解MV* 的关键。
前端框架最重要的目的是将页面渲染出来。“渲染”(render)这个词最初不是前端的东西的。前端之前叫做切图,将设计师做的PSD变成一个静态页面,然后加上动态交互。但是我们有许多数据是来自后端,如何将数据加入静态页面呢?于是又多了一套工序叫“套页面”。套页面的过程实际就是将静态页面变成切割成一块块,每一块都是一个php,jsp或vm文件,它们是后端模板引擎的处理对象!
其实模板是不局限于后端还是前端的, 模板的本质是用于从数据(变量)到实际的视觉表现(HTML代码)这项工作的一种实现手段。由于后端近水楼台先得月(取数据比较方便),因此先在后端发展出这种技术。这些后端模板文件是活动于服务器的,然后经过复杂的处理,***由浏览器渲染出来。这时的渲染是将服务器拼接好的静态文本变成一个DOM树的过程。
如果要实现前端实现MVC或MVP,那些工序必须发生改变。静态文件产出是不变,尤其是大公司,分工够细,有专门的切图组(大多数是妹子)将它们做出来。接着是套页面,这时就不能使用后端模板引擎,需要引入前端模板引擎。由于实现一个前端模板引擎太简单了,经过多年的发展,已经有众多好用的轮子:
https://github.com/janl/musta…
基于JavaScript的Logic-less(无逻辑或轻逻辑)模板。
https://github.com/twitter/ho…
上面的优化版,twitter出品
https://github.com/wycats/han…
完全兼容mustcache的语法
https://github.com/paularmstr…
拥有更强悍的模板继承与block 重写功能
https://github.com/mozilla/nu…
跟django的模板系统相似,可以说swig的升级版,是gitbook的御用前端模板
其它推荐的还有ejs, 易学易用,对有过ASP/PHP/JSP编程经验的人来说,非常亲切自然,缺点就是功能有点简单。
其他doT, xtempalate, Underscore Templates。
最不推荐是jade, 有点华而不实,过度设计,导致套页面工作量大,性能其差。
虚拟DOM时代流行的jsx就是无逻辑模板。之所以流行无逻辑或轻逻辑模板,其主要原因是改动成本比较少,像jade这样自造语法糖太多,从美工手中拿来的html需要大动干戈,进行摧心折骨般的改造才能套数据。对于模板来说,最简单而言,就是将某个可变数据放到适当的地方(填空),而其次,可以控制这个区域输出不输入(if指令),或让其个区域循环输入多次(for指令),更强制,实现模板互相套嵌(layout与block)。为了实现if与for有两种方法,一种是单纯的区域,插入一个js 语句,里面有if语句与for语句,另一种是使用语法糖,比如说 ms-for, ms-repeat, ng-if, ng-repeat。语法糖的用法比直接使用JS语句简单,但是带来学习成本与拓展功能。每一个模板 if, for指令的语法都不一样的,并且你想在循环做一些处理,比如过滤一些数据,或突然在某处中断,这又得引用一些新的语句。随着模板要求前后共用,就有了传输成本,直接写JS语句在模板里面肯定比不过语法糖。因此基于这种种原因,mustache风格的模板就成为主流。
现在三种模板风格:
PHP/ASP/JSP风格:
- <% if ( list.length ) { %>
- <ol>
- <% for ( n=0; n<list.length; ++n ) { %>
- <li>
- <%= list[n] %>
- </li>
- <% } %>
- </ol>
- <% } %>
mustcache风格,高级语法有限,通常难自定义拓展:
- {{#if list.length}}
- <ol>
- {{#each list item}}
- <li>
- {{ item }}
- </li>
- {{/each}}
- </ol>
- {{/if}}
属性绑定风格:
- <ol ms-if="list.length">
- <li ms-for="item in list">
- {{item}}
- </li>
- </ol>
前两者只能出现于script, textarea等容器元素内部。因此<分隔符与标签的<容器造成冲突,并且也不利于IDE的格式化处理。属性绑定风格则是MVVM时期***的模板定义风格,某页面某个区域就是一个模板,不需要进行入append等操作。
我们再来看如何实现前端模板。前端模板的本质就是一个可以转换函数(渲染函数)的字符串。渲染函数放进一个充满数据的对象后,还原为一个全新的字符串。因此重点是如何构建一个渲染函数。最简单的方式是正则,还记得第二章的format方法吗,这就是一个轻型的填充数据的方法。
- function format(str, object) {
- var array = Array.prototype.slice.call(arguments, 1);
- return str.replace(/\\?\#{([^{}]+)\}/gm, function(match, name) {
- if (match.charAt(0) == '\\')
- return match.slice(1);
- var index = Number(name)
- if (index >= 0)
- return array[index];
- if (object && object[name] !== void 0)
- return object[name];
- return '';
- });
- }
format方法是通过#{ }来划分静态内容与动态内容的,一般来说它们称之为定界符(delimiter)。#{为前定界符,}为后界符,这个#{}其实是ruby风格的定界符。通常的定界符是<%与%>,{{与}} 。通常在前定界符中还有一些修饰符号,比如=号,表示这个会输出到页面,-号,表示会去掉两旁的空白。
将下例,要编译成一个渲染函数
- var tpl = '你好,我的名字啊<%name%>, 今年已经 <%info.age%>岁了'
- var data = {
- name: "司徒正美",
- age: 20
- }
大抵是这样
- var body = '你好,我的名字叫'+ data.name+ ', 今年已经 '+data.info.age+ '岁了'
- var render = new Function('data', 'return '+ body)
或者聪明一点,使用数组来join:
- var array = ['return ']
- array.push('你好,我的名字叫')
- array.push(data.name)
- array.push(', 今年已经')
- array.push(data.info.age)
- array.push( '岁了')
- var render = new Function('data', array.join('+'))
这就得区分静态内容与为变量前加data.前缀。这一步可以用正则来做,也可以用纯字符串。我们试一下纯字符串方式。假令前定界符为openTag,后定界符为closeTag,通过indexOf 与slice方法,就可以将它切成一块块。
- function tokenize(str) {
- var openTag = '<%'
- var closeTag = '%>'
- var ret = []
- do {
- var index = str.indexOf(openTag)
- index = index === -1 ? str.length : index
- var value = str.slice(0, index)
- //抽取{{前面的静态内容
- ret.push({
- expr: value,
- type: 'text'
- })
- //改变str字符串自身
- str = str.slice(index + openTag.length)
- if (str) {
- index = str.indexOf(closeTag)
- var value = str.slice(0, index)
- //抽取{{与}}的动态内容
- ret.push({
- expr: value.trim(),//JS逻辑两旁的空白可以省去
- type: 'js'
- })
- //改变str字符串自身
- str = str.slice(index + closeTag.length)
- }
- } while (str.length)
- return ret
- }
- console.log(tokenize(tpl))

然后通过render方法将它们拼接起来。
- function render(str) {
- var tokens = tokenize(str)
- var ret = []
- for (var i = 0, token; token = tokens[i++]; ) {
- if (token.type === 'text') {
- ret.push('"' + token.expr + '"')
- } else {
- ret.push(token.expr)
- }
- }
- console.log("return "+ ret.join('+'))
- }
打印出来如下
- return "你好,我的名字叫"+name+", 今年已经 "+info.age+"岁了"
这个方法还不完整。首先光是在两旁加上双引号是不可靠的,万一里面还有双引号怎么办。因此我们需要引入第二章介绍的quote方法,当类型为文本时,ret.push(+quote(token.expr)+)。其次需要对动态部分的变量加上.data。怎么知道它是一个变量呢。我们回想一下变量的定义,就是以_,$或字母开头的字符组合。为了简洁起见,我们暂时不用里会中文的情况。不过,info.age这个字符串里面,其实有两个符合变量的子串,而我只需要在info前面加data.。这时,我们需要设法在匹配变量前,将对象的子级属性替换掉,替换成不符合变量的字符,然后再替换为去。为此,我搞了一个dig与fill方法,将子级属性变成??12这样的字符串:
- var quote = JSON.stringify//自己到第二章找完整函数
- var rident = /[$a-zA-Z_][$a-zA-Z0-9_]*/g
- var rproperty = /\.\s*[\w\.\$]+/g
- var number = 1
- var rfill = /\?\?\d+/g
- var stringPool = {}
- function dig(a) {
- var key = '??' + number++
- stringPool[key] = a
- return key
- }
- function fill(a) {
- return stringPool[a]
- }
- function render(str) {
- stringPool = {}
- var tokens = tokenize(str)
- var ret = []
- for (var i = 0, token; token = tokens[i++]; ) {
- if (token.type === 'text') {
- ret.push(quote(token.expr))
- } else {
- // 先去掉对象的子级属性,减少干扰因素
- var js = token.expr.replace(rproperty, dig)
- js = js.replace(rident, function (a) {
- return 'data.' + a
- })
- js = js.replace(rfill, fill)
- ret.push(js)
- }
- }
- console.log("return " + ret.join('+'))
- }
- render(tpl)
输出为
- return "你好,我的名字叫"+data.name+", 今年已经 "+data.info.age+"岁了"
***,我们修改一下后面两行,得到我们梦魅以求的渲染函数,它的实现过程比format方法复杂多了,但却是所有扩展性极强的前端模板的一般实现过程。
- function render(str){
- //略。。。
- return new Function("data", "return " + ret.join('+'))
- }
- var fn = render(tpl)
- console.log(fn+"")
- console.log(fn(data))

我们再看一下如何引入循环语句,比如将上面的模板与数据改成这样
- var tpl = '你好,我的名字叫<%name%>, 今年已经 <%info.age%>岁了,喜欢<% for(var i = 0, el; el = list[i++];){%><% el %><% } %>'
- var data = {
- name: "司徒正美",
- info: {
- age: 20
- },
- list: ["苹果","香蕉","雪梨"]
- }
这时我们就添加一种新的类型,不输出到页面的动态内容。这在token方法中做一些修改
- value = value.trim()
- if (/^(if|for|})/.test(value)) {
- ret.push({
- expr: value,
- type: 'logic'
- })
- } else {
- ret.push({
- expr: value,
- type: 'js'
- })
- }
但render方法怎么修改好呢,显示这时继续用+已经不行了,否则下场是这样
- return "你好,我的名字叫"+data.name+", 今年已经 "+data.info.age+"岁了,喜欢"+for(var i = 0, el; el = list[i++];){+""+data.el+" "+}
这时, 我们需要借用数组,将要输入的数据(text, js类型 )放进去,logic类型不放进去。
- function addPrefix(str) {
- // 先去掉对象的子级属性,减少干扰因素
- var js = str.replace(rproperty, dig)
- js = js.replace(rident, function (a) {
- return 'data.' + a
- })
- return js.replace(rfill, fill)
- }
- function addView(s) {
- return '__data__.push(' + s + ')'
- }
- function render(str) {
- stringPool = {}
- var tokens = tokenize(str)
- var ret = ['var __data__ = []']
- tokens.forEach(function(token){
- if (token.type === 'text') {
- ret.push(addView(quote(token.expr)))
- } else if (token.type === 'logic') {
- //逻辑部分都经过addPrefix方法处理
- ret.push(addPrefix(token.expr))
- } else {
- ret.push(addView(addPrefix(token.expr)))
- }
- })
- ret.push("return __data__.join('')")
- console.log( ret.join('\n'))
- }
- var fn = render(tpl)
得到的内部结构是这样的,显然addPrefix方法出问题,我们应该过滤掉if, for等关键字与保留字。
- var __data__ = []
- __data__.push("你好,我的名字叫")
- __data__.push(data.name)
- __data__.push(", 今年已经 ")
- __data__.push(data.info.age)
- __data__.push("岁了,喜欢")
- data.for(data.var data.i = 0, data.el; data.el = data.list[data.i++]){
- __data__.push("")
- __data__.push(data.el)
- __data__.push(" ")
- }
- return __data__.join('')
但即使我们处理掉关键字与保留字,对于中间生成i, el怎么区分呢?是区分不了。于是目前有两种方法,一是使用with, 这时我们就不需要加data.前缀。第二种引入新的语法。比如,前面是@就替换为data.。
先看***种:
- function render(str) {
- stringPool = {}
- var tokens = tokenize(str)
- var ret = ['var __data__ = [];', 'with(data){']
- for (var i = 0, token; token = tokens[i++]; ) {
- if (token.type === 'text') {
- ret.push(addView(quote(token.expr)))
- } else if (token.type === 'logic') {
- ret.push(token.expr)
- } else {
- ret.push(addView(token.expr))
- }
- }
- ret.push('}')
- ret.push('return __data__.join("")')
- return new Function("data", ret.join('\n'))
- }
- var fn = render(tpl)
- console.log(fn + "")
- console.log(fn(data))
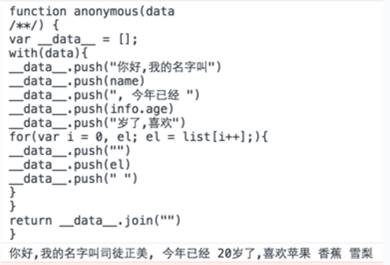
许多迷你模板都是用with减少替换工作。
第二种方法,使用引导符@, avalon2就是这么玩。这样addPrefix方法可以减少许多代码。相对应,模板也要改动一下
- var tpl = '你好,我的名字叫<%@name%>, 今年已经 <%@info.age%>岁了,喜欢<% for(var i = 0, el; el = @list[i++];){%><% el%> <% } %>'
- var rguide = /(^|[^\w\u00c0-\uFFFF_])(@|##)(?=[$\w])/g
- function addPrefix(str) {
- return str.replace(rguide, '$1data.')
- }
- function render(str) {
- stringPool = {}
- var tokens = tokenize(str)
- var ret = ['var __data__ = [];']
- for (var i = 0, token; token = tokens[i++]; ) {
- if (token.type === 'text') {
- ret.push(addView(quote(token.expr)))
- } else if (token.type === 'logic') {
- //逻辑部分都经过addPrefix方法处理
- ret.push(addPrefix(token.expr))
- } else {
- ret.push(addView(addPrefix(token.expr)))
- }
- }
- ret.push('return __data__.join("")')
- return new Function("data", ret.join('\n'))
- }
- var fn = render(tpl)
- console.log(fn + "")
- console.log(fn(data))

第二种比***种的优势在于,性能更高,并且避开es5严格模式的限制。
我们再认真思考一下,其实循环语句与条件语句,不单是for, if两个,还有while, do while, else什么。因此这需要优化。这也有两种方法,添加更多语法符合,比如上面所说的=就是输出,没有则不输出。这是ASP/JSP/PHP等模板采用的手段:
- //tokenize方法
- if (value.charAt(0) === '=') {
- ret.push({
- expr: value,
- type: 'js'
- })
- } else {
- ret.push({
- expr: value,
- type: 'logic'
- })
- }
另一种,使用语法糖,如#each (el, index) in @list , ‘#eachEnd’, ‘#if ‘,’#ifEnd’。还是改动tokenize方法
- if (value.charAt(0) === '#') {
- if (value === '#eachEnd' || value === '#ifEnd') {
- ret.push({
- expr: '}',
- type: 'logic'
- })
- } else if (value.slice(0, 4) === '#if ') {
- ret.push({
- expr: 'if(' + value.slice(4) + '){',
- type: 'logic'
- })
- } else if (value.slice(0, 6) === '#each ') {
- var arr = value.slice(6).split(' in ')
- var arrayName = arr[1]
- var args = arr[0].match(/[$\w_]+/g)
- var itemName = args.pop()
- var indexName = args.pop() || '$index'
- value = ['for(var ', ' = 0;', '<' + arrayName + '.length;', '++){'].join(indexName) +
- '\nvar ' + itemName + ' = ' + arrayName + '[' + indexName + '];'
- ret.push({
- expr: value,
- type: 'logic'
- })
- }
- } else{
- //...
- }
对应的模板改成
- var tpl = '你好,我的名字叫<%@name%>, 今年已经 <%@info.age%>岁了,喜欢<%#each el in <a href="http://www.jobbole.com/members/wx1825862276">@list</a> %><% el %> <% #eachEnd %>'
- var fn = render(tpl)
- console.log(fn + "")
- console.log(fn(data))

可能有人觉#for, #forEnd这样的语法糖比较丑,无问题,这个可以改,主要我们的tokenize方法足够强大,就能实现mustache这样的模板引擎。但所有模板引擎也基本上是这么实现的,有的还支持过滤器,也就是在js 类型的语句再进行处理,将|后面的字符器再切割出来。
如果虚拟DOM呢?那就需要一个html parser,这个工程巨大,比如reactive这个库,早期不使用html parser与虚拟DOM,只有3,4千行,加入这些炫酷功能后就达到1W6K行。返回一个字符串与返回一个类似DOM树的对象树结构是不一样。