一、模块化、组件化与插件化
项目发展到一定程度,随着人员的增多,代码越来越臃肿,这时候就必须进行模块化的拆分。在我看来,模块化是一种指导理念,其核心思想就是分而治之、降低耦合。而在 Android 工程中如何实施,目前有两种途径,也是两大流派,一个是组件化,一个是插件化。
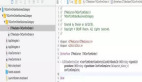
提起组件化和插件化的区别,有一个很形象的图:
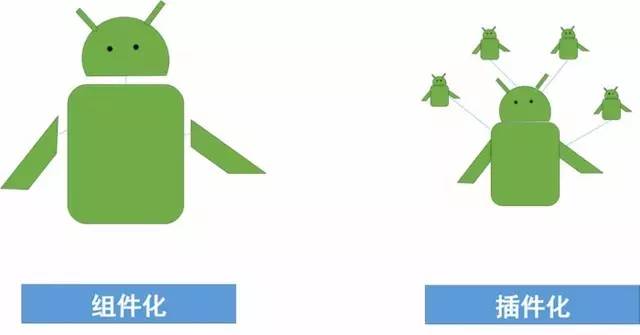
上面的图看上去比较清晰,其实容易导致一些误解,有下面几个小问题,图中可能说的不太清楚:
组件化是一个整体吗?去了头和胳膊还能存在吗?左图中,似乎组件化是一个有机的整体,需要所有器官都健在才可以存在。而实际上组件化的目标之一就是降低整体(app)与器官(组件)的依赖关系,缺少任何一个器官 app 都是可以存在并正常运行的。
头和胳膊可以单独存在吗?左图也没有说明白,其实答案应该是肯定的。每个器官(组件)可以在补足一些基本功能之后都是可以独立存活的。这个是组件化的第二个目标:组件可以单独运行。
组件化和插件化可以都用右图来表示吗?如果上面两个问题的答案都是 YES 的话,这个问题的答案自然也是 YES。每个组件都可以看成一个单独的整体,可以按需的和其他组件(包括主项目)整合在一起,从而完成的形成一个 app。
右图中的小机器人可以动态的添加和修改吗?如果组件化和插件化都用右图来表示,那么这个问题的答案就不一样了。对于组件化来讲,这个问题的答案是部分可以,也就是在编译期可以动态的添加和修改,但是在运行时就没法这么做了。而对于插件化,这个问题的答案很干脆,那就是完全可以,不论实在编译期还是运行时!
本文主要集中讲的是组件化的实现思路,对于插件化的技术细节不做讨论,我们只是从上面的问答中总结出一个结论:组件化和插件化的***区别(应该也是唯一区别)就是组件化在运行时不具备动态添加和修改组件的功能,但是插件化是可以的。
暂且抛弃对插件化“道德”上的批判,我认为对于一个 Android 开发者来讲,插件化的确是一个福音,这将使我们具备极大的灵活性。但是苦于目前还没有一个完全合适、***兼容的插件化方案(RePlugin 的饥饿营销做的很好,但还没看到疗效),特别是对于已经有几十万代码量的一个成熟产品来讲,套用任何一个插件化方案都是很危险的工作。所以我们决定先从组件化做起,本着做一个最彻底的组件化方案的思路去进行代码的重构,下面是最近的思考结果,欢迎大家提出建议和意见。
二、如何实现组件化
要实现组件化,不论采用什么样的技术路径,需要考虑的问题主要包括下面几个:
- 代码解耦。如何将一个庞大的工程拆分成有机的整体?
- 组件单独运行。上面也讲到了,每个组件都是一个完整的整体,如何让其单独运行和调试呢?
- 数据传递。因为每个组件都会给其他组件提供的服务,那么主项目(Host)与组件、组件与组件之间如何传递数据?
- UI 跳转。UI 跳转可以认为是一种特殊的数据传递,在实现思路上有啥不同?
- 组件的生命周期。我们的目标是可以做到对组件可以按需、动态的使用,因此就会涉及到组件加载、卸载和降维的生命周期。
- 集成调试。在开发阶段如何做到按需的编译组件?一次调试中可能只有一两个组件参与集成,这样编译的时间就会大大降低,提高开发效率。
- 代码隔离。组件之间的交互如果还是直接引用的话,那么组件之间根本没有做到解耦,如何从根本上避免组件之间的直接引用呢?也就是如何从根本上杜绝耦合的产生呢?只有做到这一点才是彻底的组件化。
2.1 代码解耦
把庞大的代码进行拆分,Androidstudio 能够提供很好的支持,使用 IDE 中的 multiple module 这个功能,我们很容易把代码进行初步的拆分。在这里我们对两种 module 进行区分:
- 一种是基础库 library,这些代码被其他组件直接引用。比如网络库 module 可以认为是一个 library。
- 另一种我们称之为 Component,这种 module 是一个完整的功能模块。比如读书或者分享 module 就是一个 Component。
为了方便,我们统一把 library 称之为依赖库,而把 Component 称之为组件,我们所讲的组件化也主要是针对 Component 这种类型。而负责拼装这些组件以形成一个完成 app 的 module,一般我们称之为主项目、主 module 或者 Host,方便起见我们也统一称为主项目。
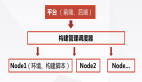
经过简单的思考,我们可能就可以把代码拆分成下面的结构:
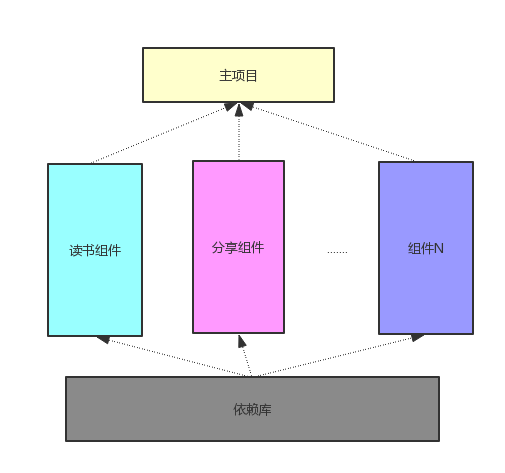
组件化简单拆分
这种拆分都是比较容易做到的,从图上看,读书、分享等都已经拆分组件,并共同依赖于公共的依赖库(简单起见只画了一个),然后这些组件都被主项目所引用。读书、分享等组件之间没有直接的联系,我们可以认为已经做到了组件之间的解耦。但是这个图有几个问题需要指出:
- 从上面的图中,我们似乎可以认为组件只有集成到主项目才可以使用,而实际上我们的希望是每个组件是个整体,可以独立运行和调试,那么如何做到单独的调试呢?
- 主项目可以直接引用组件吗?也就是说我们可以直接使用 compile project(:reader) 这种方式来引用组件吗?如果是这样的话,那么主项目和组件之间的耦合就没有消除啊。我们上面讲,组件是可以动态管理的,如果我们删掉 reader(读书)这个组件,那么主项目就不能编译了啊,谈何动态管理呢?所以主项目对组件的直接引用是不可以的,但是我们的读书组件最终是要打到 apk 里面,不仅代码要和并到 claases.dex 里面,资源也要经过 meage 操作合并到 apk 的资源里面,怎么避免这个矛盾呢?
- 组件与组件之间真的没有相互引用或者交互吗?读书组件也会调用分享模块啊,而这在图中根本没有体现出来啊,那么组件与组件之间怎么交互呢?
这些问题我们后面一个个来解决,首先我们先看代码解耦要做到什么效果,像上面的直接引用并使用其中的类肯定是不行的了。所以我们认为代码解耦的首要目标就是组件之间的完全隔离,我们不仅不能直接使用其他组件中的类,***能根本不了解其中的实现细节。只有这种程度的解耦才是我们需要的。
2.2 组件的单独调试
其实单独调试比较简单,只需要把 apply plugin: 'com.android.library'切换成 apply plugin: 'com.android.application'就可以,但是我们还需要修改一下 AndroidManifest 文件,因为一个单独调试需要有一个入口的 actiivity。
我们可以设置一个变量 isRunAlone,标记当前是否需要单独调试,根据 isRunAlone 的取值,使用不同的 gradle 插件和 AndroidManifest 文件,甚至可以添加 Application 等 Java 文件,以便可以做一下初始化的操作。
为了避免不同组件之间资源名重复,在每个组件的 build.gradle 中增加 resourcePrefix "xxx_",从而固定每个组件的资源前缀。下面是读书组件的 build.gradle 的示例:
- if(isRunAlone.toBoolean()){
- apply plugin: 'com.android.application'
- }else{
- apply plugin: 'com.android.library'
- }
- .....
- resourcePrefix "readerbook_"
- sourceSets {
- main {
- if (isRunAlone.toBoolean()) {
- manifest.srcFile 'src/main/runalone/AndroidManifest.xml'
- java.srcDirs = ['src/main/java','src/main/runalone/java']
- res.srcDirs = ['src/main/res','src/main/runalone/res']
- } else {
- manifest.srcFile 'src/main/AndroidManifest.xml'
- }
- }
- }
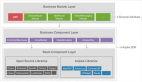
通过这些额外的代码,我们给组件搭建了一个测试 Host,从而让组件的代码运行在其中,所以我们可以再优化一下我们上面的框架图。
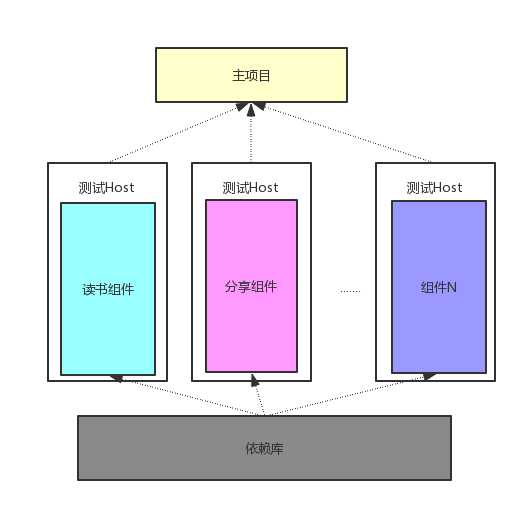
支持单独调试的组件化
2.3 组件的数据传输
上面我们讲到,主项目和组件、组件与组件之间不能直接使用类的相互引用来进行数据交互。那么如何做到这个隔离呢?在这里我们采用接口 + 实现的结构。每个组件声明自己提供的服务 Service,这些 Service 都是一些抽象类或者接口,组件负责将这些 Service 实现并注册到一个统一的路由 Router 中去。如果要使用某个组件的功能,只需要向 Router 请求这个 Service 的实现,具体的实现细节我们全然不关心,只要能返回我们需要的结果就可以了。这与 Binder 的 C/S 架构很相像。
因为我们组件之间的数据传递都是基于接口编程的,接口和实现是完全分离的,所以组件之间就可以做到解耦,我们可以对组件进行替换、删除等动态管理。这里面有几个小问题需要明确:
组件怎么暴露自己提供的服务呢?在项目中我们简单起见,专门建立了一个 componentservice 的依赖库,里面定义了每个组件向外提供的 service 和一些公共 model。将所有组件的 service 整合在一起,是为了在拆分初期操作更为简单,后面需要改为自动化的方式来生成。这个依赖库需要严格遵循开闭原则,以避免出现版本兼容等问题。
service 的具体实现是由所属组件注册到 Router 中的,那么是在什么时间注册的呢?这个就涉及到组件的加载等生命周期,我们在后面专门介绍。
一个很容易犯的小错误就是通过持久化的方式来传递数据,例如 file、sharedpreference 等方式,这个是需要避免的。
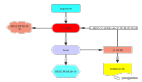
下面就是加上数据传输功能之后的架构图:
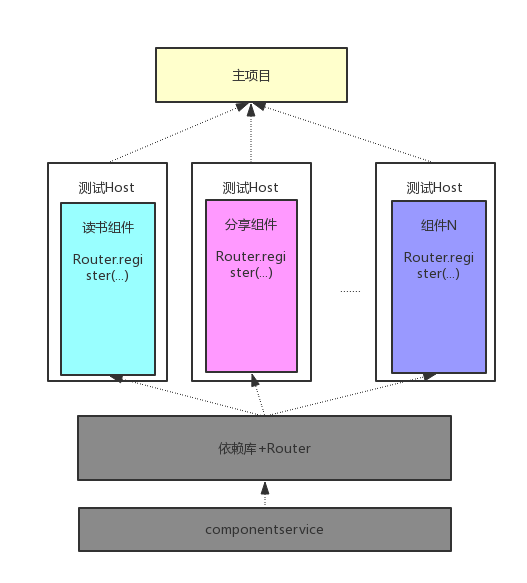
组件之间的数据传输
2.4 组件之间的 UI 跳转
可以说 UI 的跳转也是组件提供的一种特殊的服务,可以归属到上面的数据传递中去。不过一般 UI 的跳转我们会单独处理,一般通过短链的方式来跳转到具体的 Activity。每个组件可以注册自己所能处理的短链的 schme 和 host,并定义传输数据的格式。然后注册到统一的 UIRouter 中,UIRouter 通过 schme 和 host 的匹配关系负责分发路由。
UI 跳转部分的具体实现是通过在每个 Activity 上添加注解,然后通过 apt 形成具体的逻辑代码。这个也是目前 Android 中 UI 路由的主流实现方式。
2.5 组件的生命周期
由于我们要动态的管理组件,所以给每个组件添加几个生命周期状态:加载、卸载和降维。为此我们给每个组件增加一个 ApplicationLike 类,里面定义了 onCreate 和 onStop 两个生命周期函数。
加载:上面讲了,每个组件负责将自己的服务实现注册到 Router 中,其具体的实现代码就写在 onCreate 方法中。那么主项目调用这个 onCreate 方法就称之为组件的加载,因为一旦 onCreate 方法执行完,组件就把自己的服务注册到 Router 里面去了,其他组件就可以直接使用这个服务了。
卸载:卸载与加载基本一致,所不同的就是调用 ApplicationLike 的 onStop 方法,在这个方法中每个组件将自己的服务实现从 Router 中取消注册。不过这种使用场景可能比较少,一般适用于一些只用一次的组件。
降维:降维使用的场景更为少见,比如一个组件出现了问题,我们想把这个组件从本地实现改为一个 wap 页。降维一般需要后台配置才生效,可以在 onCreate 对线上配置进行检查,如果需要降维,则把所有的 UI 跳转到配置的 wap 页上面去。
一个小的细节是,主项目负责加载组件,由于主项目和组件之间是隔离的,那么主项目如何调用组件 ApplicationLike 的生命周期方法呢,目前我们采用的是基于编译期字节码插入的方式,扫描所有的 ApplicationLike 类(其有一个共同的父类),然后通过 javassisit 在主项目的 onCreate 中插入调用 ApplicationLike.onCreate 的代码。
我们再优化一下组件化的架构图:
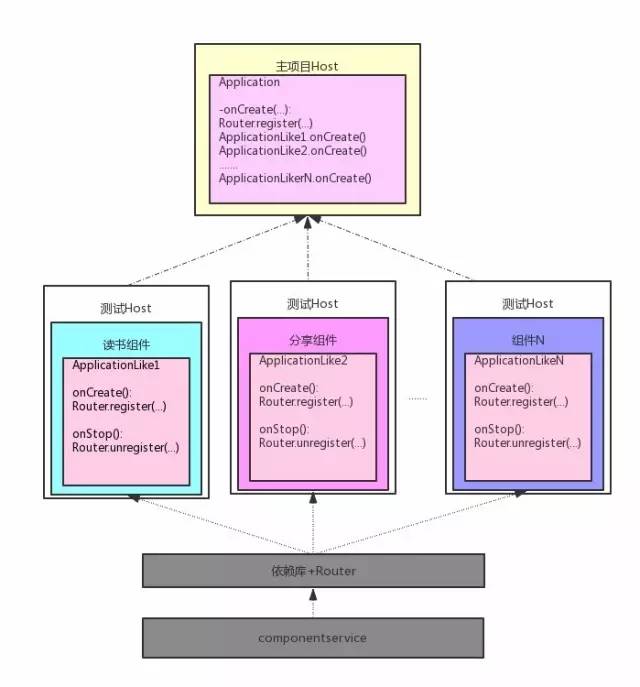
组件的生命周期
2.6 集成调试
每个组件单独调试通过并不意味着集成在一起没有问题,因此在开发后期我们需要把几个组件机集成到一个 app 里面去验证。由于我们上面的机制保证了组件之间的隔离,所以我们可以任意选择几个组件参与集成。这种按需索取的加载机制可以保证在集成调试中有很大的灵活性,并且可以加大的加快编译速度。
我们的做法是这样的,每个组件开发完成之后,发布一个 relaese 的 aar 到一个公共仓库,一般是本地的 maven 库。然后主项目通过参数配置要集成的组件就可以了。所以我们再稍微改动一下组件与主项目之间的连接线,形成的最终组件化架构图如下:
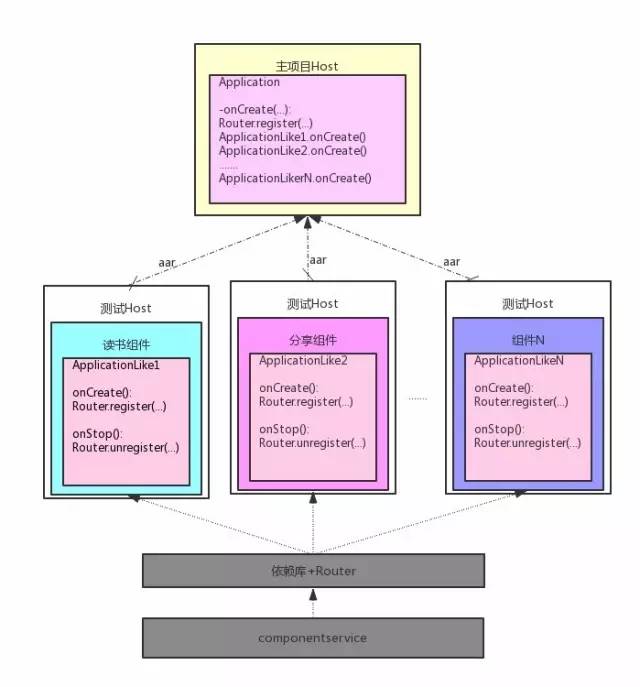
最终结构图
2.7 代码隔离
此时在回顾我们在刚开始拆分组件化是提出的三个问题,应该说都找到了解决方式,但是还有一个隐患没有解决,那就是我们可以使用 compile project(xxx:reader.aar) 来引入组件吗?虽然我们在数据传输章节使用了接口 + 实现的架构,组件之间必须针对接口编程,但是一旦我们引入了 reader.aar,那我们就完全可以直接使用到其中的实现类啊,这样我们针对接口编程的规范就成了一纸空文。千里之堤毁于蚁穴,只要有代码(不论是有意还是无意)是这么做了,我们前面的工作就白费了。
我们希望只在 assembleDebug 或者 assembleRelease 的时候把 aar 引入进来,而在开发阶段,所有组件都是看不到的,这样就从根本上杜绝了引用实现类的问题。我们把这个问题交给 gradle 来解决,我们创建一个 gradle 插件,然后每个组件都 apply 这个插件,插件的配置代码也比较简单:
- // 根据配置添加各种组件依赖,并且自动化生成组件加载代码
- if (project.android instanceof AppExtension) {
- AssembleTask assembleTask = getTaskInfo(project.gradle.startParameter.taskNames)
- if (assembleTask.isAssemble
- && (assembleTask.modules.contains("all") || assembleTask.modules.contains(module))) {
- // 添加组件依赖
- project.dependencies.add("compile","xxx:reader-release@aar")
- // 字节码插入的部分也在这里实现
- }
- }
- private AssembleTask getTaskInfo(List<String> taskNames) {
- AssembleTask assembleTask = new AssembleTask();
- for (String task : taskNames) {
- if (task.toUpperCase().contains("ASSEMBLE")) {
- assembleTask.isAssemble = true;
- String[] strs = task.split(":")
- assembleTask.modules.add(strs.length > 1 ? strs[strs.length - 2] : "all");
- }
- }
- return assembleTask
- }
三、组件化的拆分步骤和动态需求
3.1 拆分原则
组件化的拆分是个庞大的工程,特别是从几十万行代码的大工程拆分出去,所要考虑的事情千头万绪。为此我觉得可以分成三步:
从产品需求到开发阶段再到运营阶段都有清晰边界的功能开始拆分,比如读书模块、直播模块等,这些开始分批先拆分出去
在拆分中,造成组件依赖主项目的依赖的模块继续拆出去,比如账户体系等
最终主项目就是一个 Host,包含很小的功能模块(比如启动图)以及组件之间的拼接逻辑
3.2 组件化的动态需求
最开始我们讲到,理想的代码组织形式是插件化的方式,届时就具备了完备的运行时动态化。在向插件化迁徙的过程中,我们可以通过下面的集中方式来实现编译速度的提升和动态更新。
在快速编译上,采用组件级别的增量编译。在抽离组件之前可以使用代码级别的增量编译工具如 freeline(但 databinding 支持较差)、fastdex 等
动态更新方面,暂时不支持新增组件等大的功能改进。可以临时采用方法级别的热修复或者功能级别的 Tinker 等工具,Tinker 的接入成本较高。
四、总结
本文是笔者在设计“得到 app”的组件化中总结一些想法,在设计之初参考了目前已有的组件化和插件化方案,站在巨人的肩膀上又加了一点自己的想法,主要是组件化生命周期以及完全的代码隔离方面。特别是***的代码隔离,不仅要有规范上的约束(针对接口编程),更要有机制保证开发者不犯错,我觉得只有做到这一点才能认为是一个彻底的组件化方案。