引言:
在R和Python之间如何进行选择一直是一个热议的话题。机器学习世界也被不同语言偏好所划分。但是随着深度学习的盛行,天平逐渐向Python倾斜,因为截至目前为止Python具有大量R所没有的深度学习的资源库和框架。
我个人从R转到Python是因为我想更加深入机器学习的领域,而仅仅使用R的话,这(在之前)是几乎不可能实现的事情。不过也仅此而已!
随着Keras在R中的实现,语言选择的斗争又重新回到舞台中央。Python几乎已经慢慢变成深度学习建模的默认语言,但是随着在R中以TensorFlow(CPU和GPU均兼容)为后端的Keras框架的发行, 即便是在深度学习领域,R与Python抢占舞台的战争也再一次打响。
下面我们将会看到怎样在R中安装以TensorFlow为基础的Keras框架,然后在RStudio中构建我们基于经典MNIST数据集的***个神经网络模型。
内容列表:
- 以TensorFlow为后端的Keras框架安装
- 在R中可以使用Keras来构建模型的不同类型
- 在R中使用MLP将MNIST手写数字进行归类
- 将MNIST结果与Python中同等代码结果进行比较
- 结语
一、以TensorFlow为后端的Keras框架安装
在RStudio中安装Keras的步骤非常简单。只要跟着以下步骤,你就可以在R中构建你的***个神经网络模型。
- install.packages("devtools")
- devtools::install_github("rstudio/keras")
以上步骤会从Github资源库下载Keras。现在是时候把keras加载进R,然后安装TensorFlow。
- library(keras)
在默认情况下,RStudio会加载CPU版本的TensorFlow。如果没有成功加载CPU版本的TensorFlow, 使用以下指令来下载。
- install_tensorflow()
如要为单独用户或桌面系统安装GPU支持的TensorFlow,使用以下指令。
- install_tensorflow(gpu=TRUE)
为多重用户安装,请参考这个指南:https://tensorflow.rstudio.com/installation_gpu.html。
现在在我们的RStudio里,keras和TensorFlow都安装完毕了。让我们开始构建***个在R中的神经网络来处理MNIST数据集吧。
二、在R中可以使用keras来构建模型的不同类型
以下是可以在R中使用Keras构建的模型列表
- 多层感知器(Multi-Layer Perceptrons)
- 卷积神经网络(Convoluted Neural Networks)
- 递归神经网络(Recurrent Neural Networks)
- Skip-Gram模型
- 使用预训练的模型(比如VGG16、RESNET等)
- 微调预训练的模型
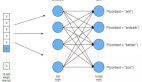
让我们从构建仅有一个隐藏层的简单MLP模型开始,来试着对手写数字进行归类。
三、在R中使用MLP将MNIST手写数字进行归类
- #loading keras library
- library(keras)
- #loading the keras inbuilt mnist dataset
- data<-dataset_mnist()
- #separating train and test file
- train_x<-data$train$x
- train_y<-data$train$y
- test_x<-data$test$x
- test_y<-data$test$y
- rm(data)
- # converting a 2D array into a 1D array for feeding into the MLP and normalising the matrix
- train_x <- array(train_x, dim = c(dim(train_x)[1], prod(dim(train_x)[-1]))) / 255
- test_x <- array(test_x, dim = c(dim(test_x)[1], prod(dim(test_x)[-1]))) / 255
- #converting the target variable to once hot encoded vectors using keras inbuilt function
- train_y<-to_categorical(train_y,10)
- test_y<-to_categorical(test_y,10)
- #defining a keras sequential model
- model <- keras_model_sequential()
- #defining the model with 1 input layer[784 neurons], 1 hidden layer[784 neurons] with dropout rate 0.4 and 1 output layer[10 neurons]
- #i.e number of digits from 0 to 9
- model %>%
- layer_dense(units = 784, input_shape = 784) %>%
- layer_dropout(rate=0.4)%>%
- layer_activation(activation = 'relu') %>%
- layer_dense(units = 10) %>%
- layer_activation(activation = 'softmax')
- #compiling the defined model with metric = accuracy and optimiser as adam.
- model %>% compile(
- loss = 'categorical_crossentropy',
- optimizer = 'adam',
- metrics = c('accuracy')
- )
- #fitting the model on the training dataset
- model %>% fit(train_x, train_y, epochs = 100, batch_size = 128)
- #Evaluating model on the cross validation dataset
- loss_and_metrics <- model %>% evaluate(test_x, test_y, batch_size = 128)
以上的代码获得了99.14%的训练精度和96.89%的验证精度。在我的i5处理器上跑这段代码完整训练一次用时13.5秒,而在TITANx GPU上,验证精度可以达到98.44%,训练一次平均用时2秒。
四、使用keras来构建MLP模型——R Vs. Python
为了更好地比较,我同样使用Python来实现解决以上的MINIST归类问题。结果不应当有任何差别,因为R会创建一个进程(conda instance)并在其中运行keras。但你仍然可以尝试以下同等的Python代码。
- #importing the required libraries for the MLP model
- import keras
- from keras.models import Sequential
- import numpy as np
- #loading the MNIST dataset from keras
- from keras.datasets import mnist
- (x_train, y_train), (x_test, y_test) = mnist.load_data()
- #reshaping the x_train, y_train, x_test and y_test to conform to MLP input and output dimensions
- x_train=np.reshape(x_train,(x_train.shape[0],-1))/255
- x_test=np.reshape(x_test,(x_test.shape[0],-1))/255
- import pandas as pd
- y_train=pd.get_dummies(y_train)
- y_test=pd.get_dummies(y_test)
- #performing one-hot encoding on target variables for train and test
- y_train=np.array(y_train)
- y_test=np.array(y_test)
- #defining model with one input layer[784 neurons], 1 hidden layer[784 neurons] with dropout rate 0.4 and 1 output layer [10 #neurons]
- model=Sequential()
- from keras.layers import Dense
- model.add(Dense(784, input_dim=784, activation='relu'))
- keras.layers.core.Dropout(rate=0.4)
- model.add(Dense(10,input_dim=784,activation='softmax'))
- # compiling model using adam optimiser and accuracy as metric
- model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
- # fitting model and performing validation
- model.fit(x_train,y_train,epochs=50,batch_size=128,validation_data=(x_test,y_test))
以上模型在同样的GPU上达到了98.42%的验证精度。所以,就像我们在一开始猜测的那样,结果是相同的。
五、结语
如果这是你用R构建的***个深度学习模型,我希望你很享受这个过程。使用很简单的代码,你就可以对手写数值进行精确度达到98%的分类。这应该可以给你足够的动力让你在机器学习的领域探索。
如果你已经在Python中使用过keras深度学习框架,那么你会发现R中keras框架的句式和结构跟其在Python中非常相似。事实上,R中的keras安装包创造了一个conda环境而且安装了在该环境下运行keras所需要的所有东西。但是,更让我兴奋的是:看到现在数据科学家们使用R构建有关现实生活的深度学习模型。就像有句话说的一样,竞争永不停歇。