设计思想
为了解决分布式数据库下,复杂的 SQL(如全局性的排序、分组、join、子查询,特别是非均衡字段的这些逻辑操作)难以实现的问题;在有了一些分布式数据库和 Hadoop 实际应用经验的基础上,对比两者的优点和不足,加上自己的一些提炼和思考, 设计了一套综合两者的系统,利用两者的优点, 补充两者的不足。具体的说, 使用数据库水平分割的思想实现数据存储,使用 MapReduce的思想实现 SQL 计算。
这里的数据库水平分割的意思是只分库不分表,对于不同数量级别的表,分库的数量可以不一样,例如 1 亿的数据量分 10 个分库,10 亿的分 50 个分库。对于使用 MapReduce的思想实现计算 ; 对于一个需求,转换成一个或多个有依赖关系的SQL,其中的每个SQL分解成一个或多个 MapReduce任务,每个 MapReduce任务又包含 mapsql、洗牌(shuffle)、reducesql,这个过程可以理解为类似 hive,区别是连 MapReduce任务中的 map 和 reduce 操作也是通过 SQL 实现, 而非 Hadoop 中的 map 和 reduce 操作.
这是基本的 MapReduce的思想,但是在 Hadoop 的生态圈中, ***代的 MapReduce将结果存储于磁盘,第二代的 MapReduce根据内存使用情况将结果存储于内存或磁盘,类比一下用数据库来存储,那么 MapReduce 的结果就是存储在表中,而数据库的缓存机制天然支持根据内存情况决定存储在内存还是磁盘 ; 另外,Hadoop 生态圈中, 计算模型也并非一种,这里的 MapReduce的计算思想,可以用类似 spark 的 RDD 迭代计算方式来替代 ; 本系统还是基于 MapReduce来说明的。
架构
根据以上的思想, 系统的架构如下:
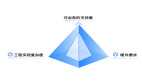
没有代理节点
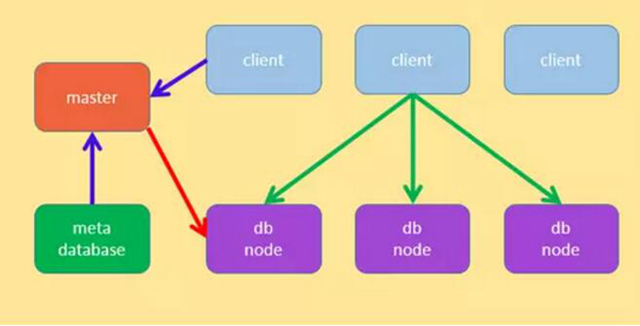
有代理节点
模块说明
关于系统中的模块,由于和绝大部分的分布式系统类似,这里仅做简要说明:
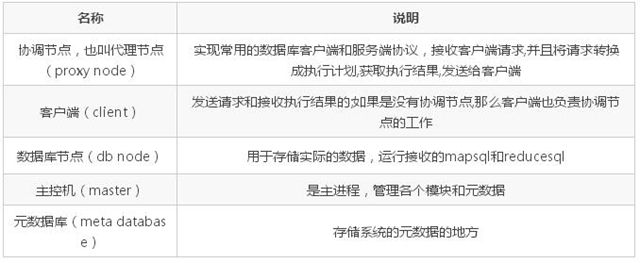
两种架构的区别
无代理节点的时候,客户端担负着比较大的工作,包括:发送请求、解析 SQL、生成执行计划、申请资源、安排执行、获取结果等;有代理节点的时候,代理节点担负着接受请求、解析 SQL、生成执行计划、申请资源、安排执行、返回结果给客户端等大部分责任,另外代理节点提供支持外部协议的接口,如 mysql 的 c/s 协议,使用 mysql 的命令行可以直接连接进来执行 SQL,整个系统就像普通的 mysql server 一样。
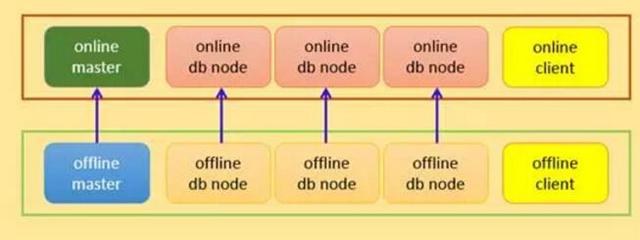
应用架构
实际应用环境可能是正式环境一套, 正式备份环境一套, 线下环境一套, 可以按照如下的架构进行部署。
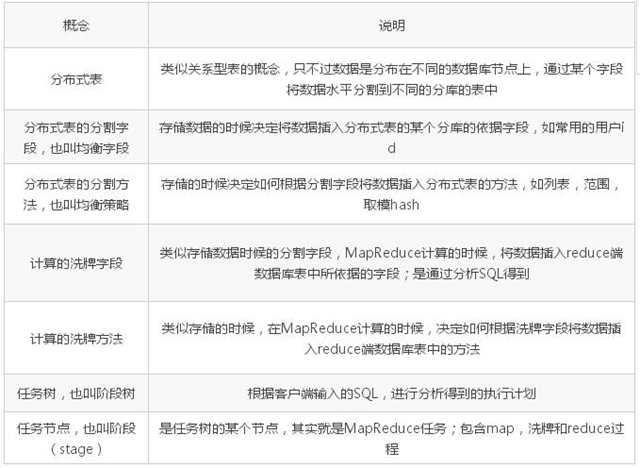
基本概念 说明
下面针对架构中的一些概念做些说明
增删改操作
当插入数据的时候,根据均衡字段和均衡策略将记录插入到对应的数据库节点中。
当更新数据的时候,需要根据均衡策略判断数据更新前的和更新后的数据库节点是否变化:如果没有变化,直接更新;如果有变化,在更新前的数据库节点中删除老数据,在更新后的数据库节点中插入新数据。
当删除数据的时候,根据均衡策略在相应的数据库节点中删除。
这三种变更数据的操作,只要涉及到多个节点的数据变更,都需要使用分布式事务保证一致性、原子性等事务特性。
查询操作
查询操作的原理类似 hive,大家可以对比来理解 ; 为了方便解释查询操作, 首先来说明阶段树和阶段的结构,如下图所示:
阶段树
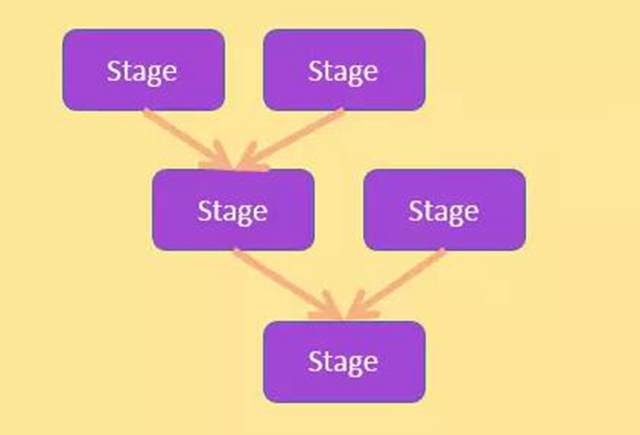
阶段
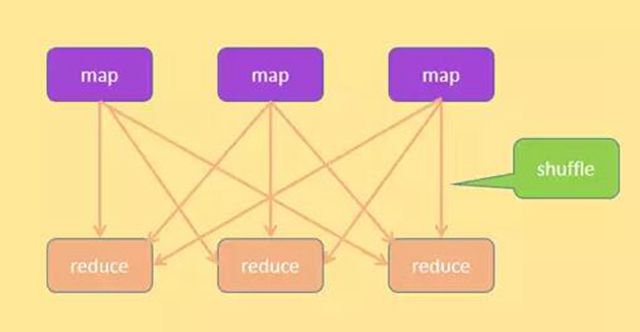
查询步骤
结合上面的图, 查询操作的具体过程如下:
- 将输入 SQL 经过词法、语法、语义分析,集合表结构信息和数据分布信息,生成包含多个阶段(简称 stage)的执行计划,这些阶段具有一定的依赖关系,形成多输入单输出的任务树。
- 每个阶段包括两种 SQL,称为 mapsql 和 reducesql,另外每个阶段包括三个操作,map、数据洗牌和 reduce;map 和 reduce 分别执行 mapsql 和 reducesql。
- 先在不同的数据库节点中执行 map 操作,map 操作执行 mapsql,它的输入是每个数据库节点上的表内部的数据,输出根据某个字段按照一定的规则进行分割,放到不同的结果集中,结果集作为数据洗牌的输入。
- 然后执行数据洗牌的过程,将不同结果集拷贝到不同的将要执行 reduce 的数据库节点上。
- 在不同的数据库节点中执行 reduce 操作,reduce 操作执行 reducesql;
- ***返回结果。
例子
由于系统核心在于存储和计算, 下面对存储和计算相关的概念举例说明
均衡策略
举例说明均衡策略,基本信息如下:表名字:tab_user_login表描述:用于存储用户登录信息节点数:4,分为 0、1、2、3
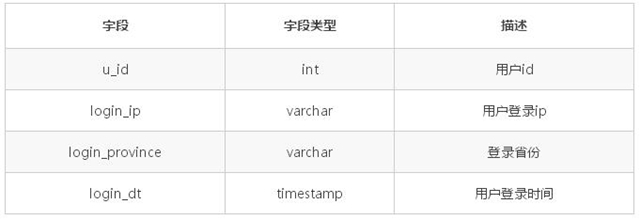
举例说下如下的几种策略:
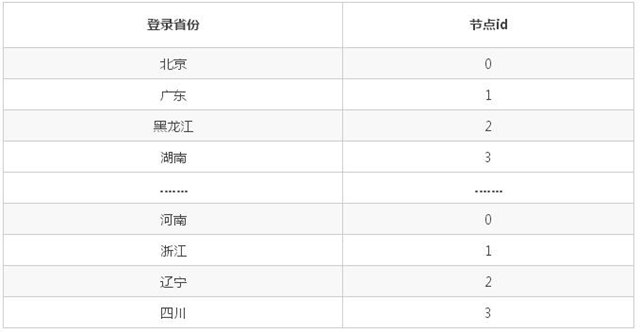
列表:以登录省份作为均衡字段为例
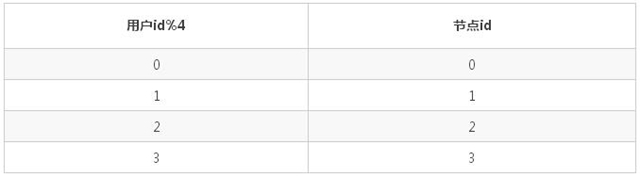
取模 hash:按 4 取模, 以用户 id 作为均衡字段
范围: 从 0 到一亿,以用户 id 作为均衡字段

取模 hash 和范围结合:先范围,再取模, 以用户 id 作为均衡字段

查询
举例说明查询操作,基本信息如下:
用户表 tab_user_info 如下:
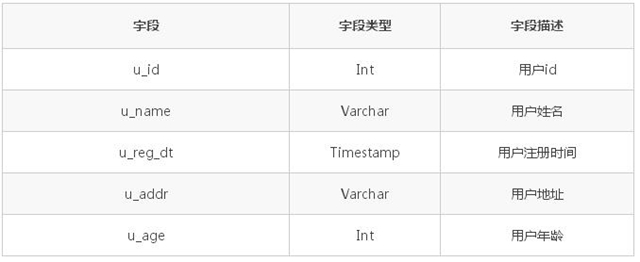
用户登录表 tab_login_info 的结构如下:
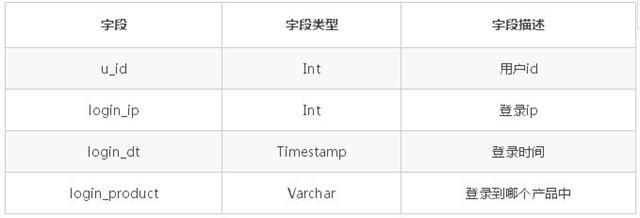
排序
排序的关键点是节点之间存在大小关系,大的 key 或者 key 范围放到节点 id 大的节点上,然后在节点上排序,获取数据的时候根据节点 id 大小依次获取。
以如下 sql 为例,某一注册时间范围内的用户信息,按照年龄和 id 排序:
- select * from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? order by u_id
执行计划可能为:
Map:
- select * from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? order by u_id
Shuffle:
执行完成之后,这种情况下由于需要按照 u_id 进行数据洗牌,所以各个存储节点上需要按照 u_id 进行划分。例如有 N 个计算节点,那么按照(*** u_id- 最小 u_id)/N 平均划分,将不同存储节点上的同一范围的 u_id,划分到同一个计算节点上即可(这里的计算节点存在大小关系)。
Reduce:
- select * from tab_user_info t order by u_id
分组聚合
关键点和排序类似,节点之间存在大小关系,大的 key 或者 key 范围放到节点 id 大的节点上,然后在节点上分组聚合,获取数据的时候根据节点 id 大小依次获取。
以如下 sql 为例,某一注册时间范围内的用户,按照年龄分组,计算每个分组内的用户数:
- select age,count(u_id) v from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? group by age
执行计划可能为:
Map:
- select age,count(u_id) v from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? group by age
Shuffle:
执行完成之后,这种情况下由于需要按照 age 进行数据洗牌,考虑到 age 的唯一值比较少,所以数据洗牌可以将所有的记录拷贝到同一个计算节点上。
Reduce:
- select age,sum(v) from t where group by age
连接
首先明确 join 的字段类型为数字类型和字符串类型,其他类型如日期可以转换为这两种。数字类型的排序很简单,字符串类型的数据排序需要确定规则,类似 mysql 中的 collation,比较常用的是按照 unicode 编码顺序,按照实际存储节点的大小等;其次 join 的方式有等值 join 和非等值 join;以如下常用且比较简单的情况为例。
以如下 sql 为例,某一注册时间范围内的用户的所有登录信息:
- select t1.u_id,t1.u_name,t2.login_product
- from tab_user_info t1 join tab_login_info t2
- on (t1.u_id=t2.u_id and t1.u_reg_dt>=? and t1.u_reg_dt<=?)
执行计划可能为:
Map:
由于是 join,所有的表都要进行查询操作,并且为每张表打上自己的标签,具体实施的时候可以加个表名字字段,在所有存储节点上执行
- select u_id,u_name from tab_user_info t where u_reg_dt>=? and t1.u_reg_dt<=?
- select u_id, login_product from tab_login_info t
Shuffle:这种情况下由于需要按照 u_id 进行数据洗牌,考虑到 u_id 的唯一值比较多,所以各个存储节点上需要按照 u_id 进行划分,例如有 N 个计算节点,那么按照(*** u_id- 最小 u_id)/N 平均划分,将不同存储节点上的同一范围的 u_id,划分到同一个计算节点上。
Reduce:
- select t1.u_id,t1.u_name,t2.login_product
- from tab_user_info t1 join tab_login_info t2
- on (t1.u_id=t2.u_id)
子查询
由于子查询可以分解成具有依赖关系的不包含子查询的 SQL,所以生成的执行计划,就是多个 SQL 的执行计划按照一定的依赖关系进行依次执行。
与已有系统的区别和优点
- 相比 hdfs 来说,数据的分布是有规则的,hdfs 需要启动之后执行命令去查询文件具体在什么节点上;元数据的较小,记录规则即可,管理成本较低,在启动速度方面很快。
- 数据是放在数据库中的,可以很好的使用索引和数据库本身的缓存机制,大大提高数据查询的效率,特别是在大量数据的情况下,利用索引查询返回少量的数据。
- 数据可以进行删除和修改,这在基于 hdfs 的系统中一般比较麻烦和低效。
- 在计算方面,和 MapReduce 或者其他的分布式计算框架(如 spark)并没有本质的区别(需要进行 shuffle)。但是由于数据的分布是有规则的,在有些地方可以做的更好,在分布式全文索引体现。
- 由于线上系统一般使用数据库作为最终的存储位置,而把数据库同步到 hdfs 中是比较麻烦的,并且对于有删除和更新的情况,同步数据麻烦低效,速度较慢;相比之下,这个方案可以使用数据库本身提供的镜像复制功能来同步,基本没有额外的麻烦和低效的工作。
- 基于以上,可以把线上系统(主系统)和线下的数据分析挖掘(从系统)做成统一的方案, 参见应用架构图。
应用场景
***列举一些应用场景