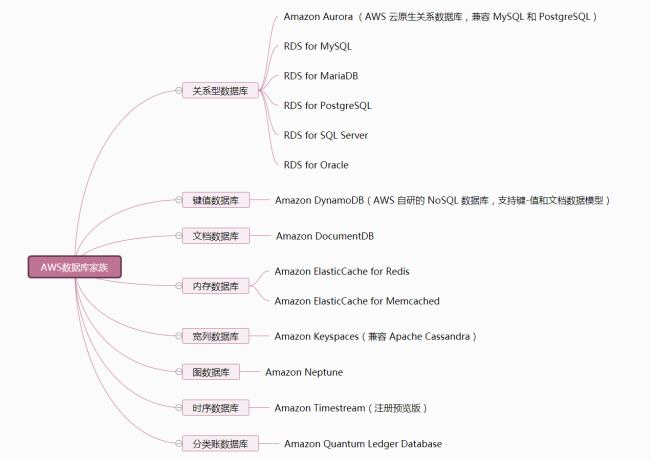
我们在上一期谈到,数据库的臃肿,也就是过多的中间表以及相关存储过程,是由于其计算封闭性造成的。如果能够实现独立的计算引擎,使计算不再依赖于数据库提供,那么就可以为数据库瘦身了。
一、
内部来源的中间数据不必再以数据表的形式落地在数据库中,而可以放到文件系统中,由外部计算引擎提供进一步的计算能力。对于只读的中间数据,使用文件存储时不需要考虑再改写,可以更为紧致并采用一定的压缩手段,而且在访问时也不必考虑事务一致性,机制大为简化,这样能获得比数据库更好多的吞吐性能。文件系统还可以采用树形组织方案,将各个应用(模块)的中间数据分类管理好,使更方便,并且可使中间数据将从属于应用模块,不会被其它模块访问到。当有模块修改或下线时,相应的中间数据可以跟随修改,而不必担心被共享而产生的耦合问题。用于生成中间数据的存储过程也可以移到数据库外部,作为应用程序的一部分,同样不会产生耦合问题。
外部来源的中间表也可以减少甚至取消。ETL过程的E、T步骤可以直接在数据库外部由计算引擎实施,在完成清洗转换之后再加载进数据库。E、T步骤中不占用数据库的计算资源,当然也不需要建立中间表来保存这些数据,数据库只要保存最终需要的结果即可。
多样性数据源的数据呈现也可以直接由计算引擎实现数据源和数据库的混合计算,这样就不必将外部数据源导入数据库,有效减少中间表。在数据呈现时由计算引擎临时向数据源发出取数指令以获得***的数据,还可以获得更好的实时性,而采用中间表方式一般只能定期把外部数据源转入,无法看到***的外部数据。而且,不将外部数据导入数据库,还能继续利用原数据源的某些优势,比如NoSQL数据库对于按键值查找有很好的性能,还能较好地解决数据结构多样性的问题。另外,专门设计的计算引擎如果再能处理好XML,json这类多层数据,在计算描述上也比传统的关系数据库更有优势。
二、
除了必须的计算能力本身之外,要用于数据库瘦身的计算引擎必须拥有较好开放性和可集成性。
开放性是指计算能力并不依赖于某种存储体系,而可以计算各种来源的数据,比如文件系统中的数据,这样就能利用适合的存储方案来组织管理中间数据。如果计算体系要求特有的数据存储体系(比如数据库),那只是把数据库的臃肿换了一个地方继续臃肿。可集成性是指计算能力可以嵌入到应用程序中,成为应用的一部分,而不能象数据库那样是个独立的进程,这样就不会被其它应用(模块)共享,避免出现应用间的耦合问题。
从这个意义上讲,Hadoop体系(包括Spark)虽然有一定的计算能力,但并不合适充当开放计算引擎的作用。Hadoop有一定的开放性,可以计算体系外的数据,但并不常用,而且性能较差;Hadoop是以独立进程方式运行的庞大体系,基本上没有可集成性,很难完全嵌入到应用程序中。
有了开放可集成的计算能力,相当于实现了计算和存储的分离,在设计应用的体系结构时就会更为得心应手。不必为了获得计算能力而部署多余的数据库或者扩容数据库,让数据库专心做它最合适做的事情,将资源效用发挥到***。