网信贷黑名单网站截图:
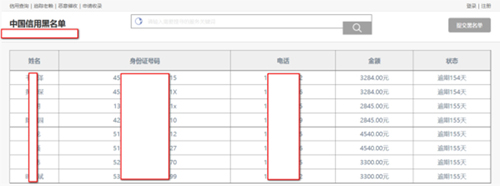
真实数据截图:
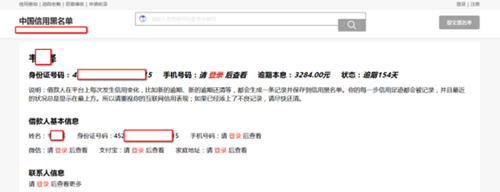
我这里想爬取这些个人的信息,但是有些内容是需要登陆才可以查看的,所以先去注册了一个账号。
登陆进来后得到的内容是完整的:

(PS:这里就不激活邮箱了)
– 结构分析&代码编写
这些被黑名单的人信息是首页点入进去的,对比下:
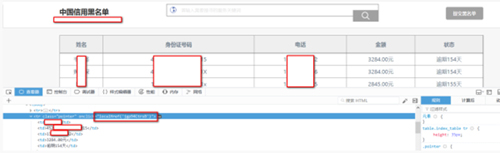
- <tr onclick="localHref('jgp94CtrsB')" class="pointer">
点开后的链接是:
acklist-jgp94CtrsB.html
相信大家一眼就看出来了规律吧,显示的HTML代码中有链接特征。
根据链接的规则我们可以写出这样一段python代码:
- target_url = 'https://*.cc' #设置url
- r = requests.get(target_url) #访问url
- html = r.text#获取html代码
- h = r"localHref(\'(.*?)\')" #正则代码
- h_re = re.compile(h) #生成正则
- href_all = h_re.findall(html) #正则匹配出链接特征
- for i in href_all: #匹配出来的链接特征需要用for遍历
- url = 'https://*.cc/blacklist-' + i + '.html' #遍历出来组合成url
现在我要获取的是“姓名、身份证、手机号、微信、支付宝”,这里我使用的是XPATH来获取这些数据,因为这样更简单一些。
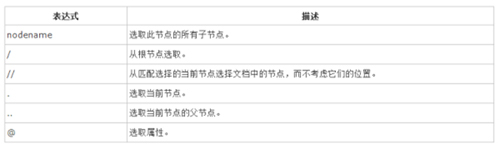
大概的来了解下XPATH的语法吧:
这里完全可以使用更快速的方法:
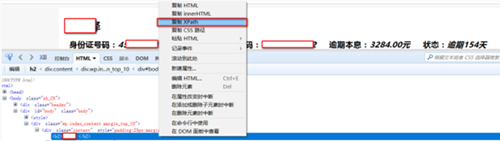
直接使用Firebug或者其它浏览器的Copy XPath:
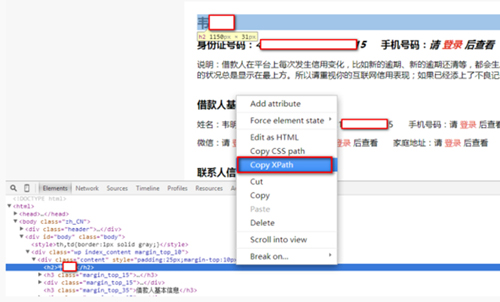
得到的XPath语法:
- /html/body/div[2]/div/div/h2
我们要获取的名字是h2标签内的所以直接修改成:
- /html/body/div[2]/div/div/h2/text()
直接上Python代码:
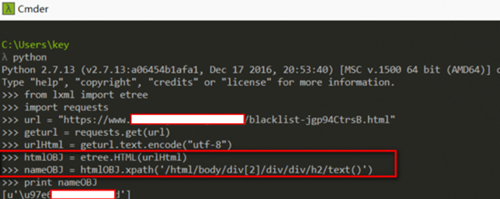
(注:from lxml import etree 是支持XPath语法的库)
可以看到输出的结果是unicode编码 ,直接解码就显示了:
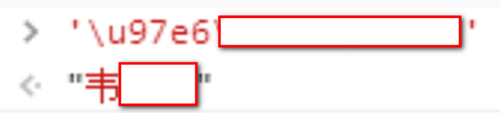
其他的XPath代码:
- sfzOBJ = htmlOBJ.xpath('//h3[@class="margin_top_15"]/span[@class="inline"]/i[1]/text()') #身份证
- phoneOBJ = htmlOBJ.xpath('//*[@id="body"]/div/div/h3[1]/span[2]/i/text()') #手机号
- wechatOBJ = htmlOBJ.xpath('//*[@id="body"]/div/div/div[3]/span[1]/text()') #微信
- alipayOBJ = htmlOBJ.xpath('//*[@id="body"]/div/div/div[3]/span[2]/text()') #支付宝
这里要记得加上登陆的Cookie去访问哦:
1.在控制台输入document.cookie获取Cookie
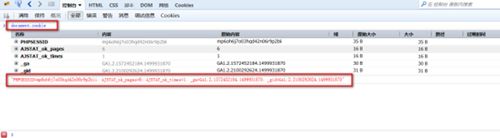
2.带上Cookie请求访问
- geturl = requests.get(url,headers={'Cookie':'__cfduid=d8b7bef3c3b678161d9fe747ccb651cea1499931877; PHPSESSID=mp6oh6j7o03hqd42n06r9p2bii;
- AJSTAT_ok_pages=5; AJSTAT_ok_times=1; _ga=GA1.2.1572452184.1499931870; _gid=GA1.2.2100292624.1499931870'})
– 最后
核心的代码都写好了,其他的就是结构的梳理,完善代码:
- import requests,re
- from requests.packages.urllib3.exceptions import InsecureRequestWarning
- requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
- from lxml import etree
- target_url = 'https://www.xinyongheimingdan.cc/'
- cookie = '你的cookie'
- r = requests.get(target_url,headers={
- 'Cookie':cookie
- })
- html = r.text
- h = r"localHref\(\'(.*?)\'\)"
- h_re = re.compile(h)
- href_all = h_re.findall(html)
- for i in href_all:
- url = 'https://www.xinyongheimingdan.cc/blacklist-' + i + '.html'
- geturl = requests.get(url,headers={
- 'Cookie':cookie
- })
- urlHTML = geturl.text.encode("utf-8")
- htmlOBJ = etree.HTML(urlHTML)
- nameOBJ = htmlOBJ.xpath('/html/body/div[2]/div/div/h2/text()')
- sfzOBJ = htmlOBJ.xpath('//h3[@class="margin_top_15"]/span[@class="inline"]/i[1]/text()')
- phoneOBJ = htmlOBJ.xpath('//*[@id="body"]/div/div/h3[1]/span[2]/i/text()')
- wechatOBJ = htmlOBJ.xpath('//*[@id="body"]/div/div/div[3]/span[1]/text()')
- alipayOBJ = htmlOBJ.xpath('//*[@id="body"]/div/div/div[3]/span[2]/text()')
- all_info = nameOBJ,sfzOBJ,phoneOBJ,wechatOBJ,alipayOBJ
- print all_info
成果: