DGA(域名生成算法)是一种利用随机字符来生成C&C域名,从而逃避域名黑名单检测的技术手段。例如,一个由Cryptolocker创建的DGA生成域xeogrhxquuubt.com,如果我们的进程尝试其它建立连接,那么我们的机器就可能感染Cryptolocker勒索病毒。域名黑名单通常用于检测和阻断这些域的连接,但对于不断更新的DGA算法并不奏效。我们的团队也一直在对DGA进行广泛的研究,并在arxiv发表了一篇关于使用深度学习预测域生成算法的文章。
本文我将为大家介绍一种,简单而有效的DGA生成域的检测技术。我们将利用神经网络(或称之为深度学习)更具体的来讲就是长短期记忆网络(LSTM),来帮助我们检测DGA生成域。首先我们会探讨深度学习的优势,然后我将进一步的通过实例来验证我的论述。
如果你之前对机器学习并不了解,那么我建议你先翻看我之前发布的三篇关于机器学习的文章再来阅读本文,这样会更有助于你的理解。
长短期记忆网络(LSTM)的好处
深度学习近年来在机器学习社区中可以说是占尽风头。深度学习是机器学习中一种基于对数据进行表征学习的方法。其好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。随着数十年的不断发展,深度学习在过去四五年间一直很受欢迎。再加上硬件的不断升级优化(如GPU的并行处理改进),也使得培训复杂网络成为了可能。LSTM是一种RNN的特殊类型,可以学习长期依赖信息,如文本和语言等。LSTM是实现循环神经网络的一个这样的技巧,意味着包含循环的神经网络。LSTM在长时间的学习模式方面非常擅长如文本和言语。在本文的例子中,我将使用它们来学习字符序列(域名)的模式,从而帮助我们识别哪些是DGA生成域哪些不是。
使用深度学习的一大好处就是我们可以省去特征工程这一繁杂的过程。而如果我们使用常规方法来生成一长串特征列表(例如长度,元音,辅音以及n-gram模型),并使用这些特征来识别DGA生成域和非DGA生成域。那么就需要安全人员实时的更新和创建新的特征库,这将是一个异常艰巨和痛苦的过程。其次,一旦攻击者掌握了其中的过滤规则,那么攻击者就可以轻松地通过更新其DGA来逃避我们的检测。而深度学习的自动表征学习能力,也让我们能够更快的适应不断变化的对手。同时,也大大减少了我们人力物力的巨大投入。我们技术的另一个优点是仅对域名进行识别而不使用任何上下文功能,如NXDomains
我们技术的另一个优点是,我们仅对域名进行分类而不使用任何上下文功能如NXDomain。上下文功能的生成往往需要额外昂贵的基础设施(如网络传感器和第三方信誉系统)。令人惊讶的是对于没有上下文信息的LSTM,执行却明显优于它们。如果你想了解更多关于LSTM的相关内容,我推荐大家可以关注:colah的博客和blogdeeplearning.net。
什么是DGA?
首先我们要搞清楚什么是DGA?以及DGA检测的重要性。攻击者常常会使用域名将恶意程序连接至C&C服务器,从而达到操控受害者机器的目的。这些域名通常会被编码在恶意程序中,这也使得攻击者具有了很大的灵活性,他们可以轻松地更改这些域名以及IP。而对于另外一种硬编码的域名,则往往不被攻击者所采用,因为其极易遭到黑名单的检测。
而有了DGA域名生成算法,攻击者就可以利用它来生成用作域名的伪随机字符串,这样就可以有效的避开黑名单列表的检测。伪随机意味着字符串序列似乎是随机的,但由于其结构可以预先确定,因此可以重复产生和复制。该算法常被运用于恶意软件以及远程控制软件上。
我们来简单了解下攻击者和受害者端都做了哪些操作。首先攻击者运行算法并随机选择少量的域(可能只有一个),然后攻击者将该域注册并指向其C2服务器。在受害者端恶意软件运行DGA并检查输出的域是否存在,如果检测为该域已注册,那么恶意软件将选择使用该域作为其命令和控制(C2)服务器。如果当前域检测为未注册,那么程序将继续检查其它域。
安全人员可以通过收集样本以及对DGA进行逆向,来预测哪些域将来会被生成和预注册并将它们列入黑名单中。但DGA可以在一天内生成成千上万的域,因此我们不可能每天都重复收集和更新我们的列表。
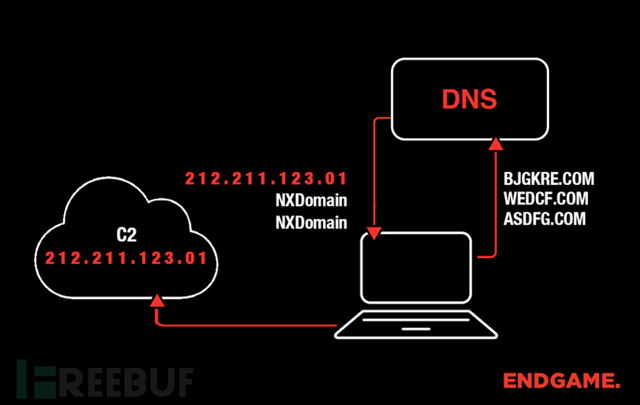
图1展示了许多类型的恶意软件的工作流程。如图所示恶意软件会尝试连接三个域:asdfg.com,wedcf.com和bjgkre.com。前两个域未被注册,并从DNS服务器接收到NXDomain响应。第三个域已被注册,因此恶意软件会使用该域名来建立连接。
创建LSTM
训练数据
任何机器学习模型都需要训练数据。这里我们将使用Alexa前100万个网站作为我们的原始数据。我们还在Python中组合了几个DGA算法,你可以在我们的github上获取到,同时我们将使用这些算法来生成恶意数据。
工具和框架
Keras toolbox是一个Python库,借用该库可以大大方便我们编写神经网络。当然除了Keras还有许多其它类似的工具,这里我们首选Keras因为它更易于演示和理解。Keras的底层库使用Theano或TensorFlow,这两个库也称为Keras的后端。无论是Theano还是TensorFlow;都是一个”符号主义”的库,这里我们可以根据自身偏好选择使用。
模型代码
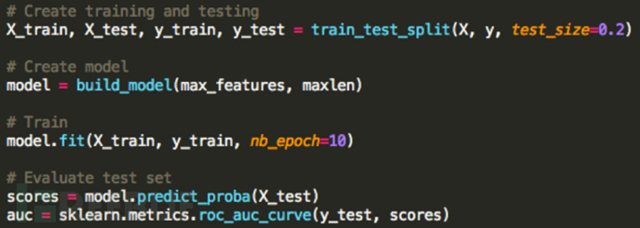
以下是我们用Python代码构建的模型:
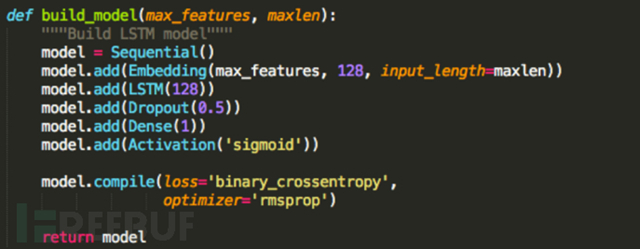
下面我对以上代码做个简单的解释:
在第一行我们定义了一个基本的神经网络模型。下一行我们添加了一个嵌入层。此图层将每个字符转换为128个浮点数的向量(128不是幻数)。一旦这个层被训练(输入字符和输出128个浮点数),每个字符基本上都经过一次查找。max_features定义有效字符数。input_length是我们将要传递给神经网络的最大长度字符串。
下一行添加了一个LSTM层,这是非常重要的一步。128表示我们内部状态的维度(这恰好与我们之前嵌入层的大小相同)。维度越大对模型的描述也就更具体,在这里128刚好适合我们的需求。
Dropout层是为了防止模型过拟合的。如果你觉得没必要使用你可以删除它,但还是建议大家最好能用上。
Dropout层位于大小为1的Dense层(全连接层)之前。
我们添加了一个激活函数sigmoid,它能够把输入的连续实值“压缩”到0和1之间。如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
我们使用优化器对交叉熵损失函数进行优化。RMSProp是随机梯度下降的变体,并且往往对循环神经网络非常有效。
预处理代码
在正式开始训练数据之前,我们必须做一些基本的数据预处理。应将每个字符串转换为表示每个可能字符的int数组。这种编码是任意的,但是应该从1开始(我们为结束序列token保留0)并且是连续的。下面的这串代码可以帮助我们实现这个过程。
![]()
接下来,我们将每个int数组填充至相同的长度。填充能让我们的toolbox更好地优化计算(理论上,LSTM不需要填充)。这里Keras为我们提供了一个非常好用的函数:
![]()
maxlen表示每个数组的长度。当阵列太长时,此函数将填充0和crop。之前我们整数的编码是从1开始的这一点非常重要,因为LSTM应该学习填充和字符之间的区别。
这里,我们可以使用ROC曲线分割我们的测试和训练集,以及评估我们的表现。
比较
在我们发布在arxiv的文章中,我们将我们简单的LSTM技术和其他三种技术做了对比。为了使本文更加通俗易懂,我们只将结果与使用逻辑回归分布的单一方法进行比较。这种技术也比目前现有的技术更好(但仍不如LSTM)。这是一种更传统的基于特征的方法,其中特征是域名中包含的所有双字节的直方图(或原始计数)。你可以在我们的github上获取到,关于 使用LSTM预测域生成算法的实现代码。
结果
现在让我们来看看分类器性能指标ROC曲线、AUC值:
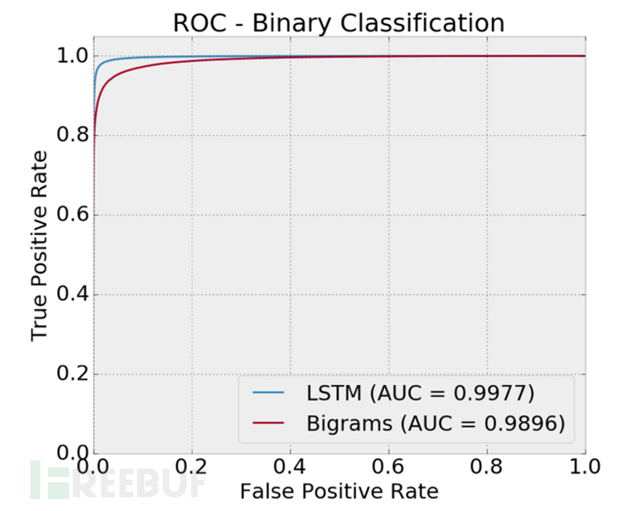
可以看到一个AUC的值为0.9977,说明我们的分类效果非常的好,而达到这个效果我们仅仅只用了几行代码。实际上我们完成了对一个数量庞大而多样化的数据集的深入分析,并以1/10,000的假阳性率观察了90%的检测。
总结
我们提出了使用神经网络来检测DGA的简单技术。该技术不需要使用任何上下文信息(如NXDomains和第三方信誉系统),并且检测效果也远远优于现有的一些技术。本文只是我们关于DGA研究的部分摘要,你可以点击阅读我们在arxiv的完整文章。同时,你也可以对我们发布在github上的代码做进一步的研究学习。