












首先细讲一下 Max pooling。
Max pooling
在卷积后还会有一个 pooling 的操作,尽管有其他的比如 average pooling 等,这里只提 max pooling。
max pooling 的操作如下图所示:整个图片被不重叠的分割成若干个同样大小的小块(pooling size)。每个小块内只取最大的数字,再舍弃其他节点后,保持原有的平面结构得出 output。

max pooling 在不同的 depth 上是分开执行的,且不需要参数控制。 那么问题就 max pooling 有什么作用?部分信息被舍弃后难道没有影响吗?

Max pooling 的主要功能是 downsampling,却不会损坏识别结果。 这意味着卷积后的 Feature Map 中有对于识别物体不必要的冗余信息。 那么我们就反过来思考,这些 “冗余” 信息是如何产生的。
直觉上,我们为了探测到某个特定形状的存在,用一个 filter 对整个图片进行逐步扫描。但只有出现了该特定形状的区域所卷积获得的输出才是真正有用的,用该 filter 卷积其他区域得出的数值就可能对该形状是否存在的判定影响较小。 比如下图中,我们还是考虑探测 “横折” 这个形状。 卷积后得到 3x3 的 Feature Map 中,真正有用的就是数字为 3 的那个节点,其余数值对于这个任务而言都是无关的。 所以用 3x3 的 Max pooling 后,并没有对 “横折” 的探测产生影响。 试想在这里例子中如果不使用 Max pooling,而让网络自己去学习。 网络也会去学习与 Max pooling 近似效果的权重。因为是近似效果,增加了更多的 parameters 的代价,却还不如直接进行 Max pooling。
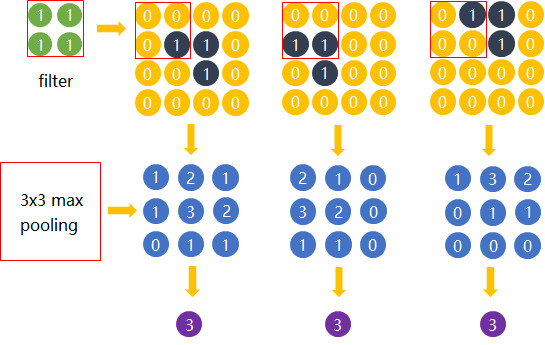
Max pooling 还有类似 “选择句” 的功能。假如有两个节点,其中第一个节点会在某些输入情况下最大,那么网络就只在这个节点上流通信息;而另一些输入又会让第二个节点的值最大,那么网络就转而走这个节点的分支。
但是 Max pooling 也有不好的地方。因为并非所有的抓取都像上图这样的极端例子。有些周边信息对某个概念是否存在的判定也有影响。 并且 Max pooling 是对所有的 Feature Maps 进行等价的操作。就好比用相同网孔的渔网打鱼,一定会有漏网之鱼。
下面对其他的 pooling 方法做一个简单的整理(前一段时间整理的个人觉得比较不错且流行的 pooling 方法)。
SUM pooling
基于 SUM pooling 的中层特征表示方法,指的是针对中间层的任意一个 channel(比如 VGGNet16, pool5 有 512 个 channel),将该 channel 的 feature map 的所有像素值求和,这样每一个 channel 得到一个实数值,N 个 channel 最终会得到一个长度为 N 的向量,该向量即为 SUM pooling 的结果。
AVE pooling
AVE pooling 就是 average pooling,本质上它跟 SUM pooling 是一样的,只不过是将像素值求和后还除以了 feature map 的尺寸。作者以为,AVE pooling 可以带来一定意义上的平滑,可以减小图像尺寸变化的干扰。设想一张 224224 的图像,将其 resize 到 448448 后,分别采用 SUM pooling 和 AVE pooling 对这两张图像提取特征,我们猜测的结果是,SUM pooling 计算出来的余弦相似度相比于 AVE pooling 算出来的应该更小,也就是 AVE pooling 应该稍微优于 SUM pooling 一些。
MAX pooling
MAX pooling 指的是对于每一个 channel(假设有 N 个 channel),将该 channel 的 feature map 的像素值选取其中最大值作为该 channel 的代表,从而得到一个 N 维向量表示。笔者在 flask-keras-cnn-image-retrieval中采用的正是 MAX pooling 的方式。

上面所总结的 SUM pooling、AVE pooling 以及 MAX pooling,这三种 pooling 方式,在笔者做过的实验中,MAX pooling 要稍微优于 SUM pooling、AVE pooling。不过这三种方式的 pooling 对于 object retrieval 的提升仍然有限。
MOP pooling
MOP Pooling 源自 Multi-scale Orderless Pooling of Deep Convolutional Activation Features这篇文章,一作是 Yunchao Gong,此前在搞哈希的时候,读过他的一些论文,其中比较都代表性的论文是 ITQ,笔者还专门写过一篇笔记论文阅读:Iterative Quantization 迭代量化。MOP pooling 的基本思想是多尺度与 VLAD(VLAD 原理可以参考笔者之前写的博文图像检索:BoF、VLAD、FV 三剑客),其具体的 pooling 步骤如下:

Overview of multi-scale orderless pooling for CNN activations (MOP-CNN). Our proposed feature is a concatenation of the feature vectors from three levels: (a)Level 1, corresponding to the 4096-dimensional CNN activation for the entire 256256image; (b) Level 2, formed by extracting activations from 128128 patches and VLADpooling them with a codebook of 100 centers; (c) Level 3, formed in the same way aslevel 2 but with 64*64 patches.
具体地,在 L=1 的尺度下,也就是全图,直接 resize 到 256*256 的大小,然后送进网络,得到第七层全连接层 4096 维的特征;在 L=2 时,使用 128*128(步长为 32) 的窗口进行滑窗,由于网络的图像输入最小尺寸是 256*256,所以作者将其上采样到 256256,这样可以得到很多的局部特征,然后对其进行 VLAD 编码,其中聚类中心设置为 100,4096 维的特征降到了 500 维,这样便得到了 50000 维的特征,然后将这 50000 维的特征再降维得到 4096 维的特征;L=3 的处理过程与 L=2 的处理过程一样,只不过窗口的大小编程了 64*64 的大小。
作者通过实验论证了 MOP pooling 这种方式得到的特征一定的不变性。基于这种 MOP pooling 笔者并没有做过具体的实验,所以实验效果只能参考论文本身了。
CROW pooling
对于 Object Retrieval,在使用 CNN 提取特征的时候,我们所希望的是在有物体的区域进行特征提取,就像提取局部特征比如 SIFT 特征构 BoW、VLAD、FV 向量的时候,可以采用 MSER、Saliency 等手段将 SIFT 特征限制在有物体的区域。同样基于这样一种思路,在采用 CNN 做 Object Retrieval 的时候,我们有两种方式来更细化 Object Retrieval 的特征:一种是先做物体检测然后在检测到的物体区域里面提取 CNN 特征;另一种方式是我们通过某种权重自适应的方式,加大有物体区域的权重,而减小非物体区域的权重。CROW pooling ( Cross-dimensional Weighting for Aggregated Deep Convolutional Features ) 即是采用的后一种方法,通过构建 Spatial 权重和 Channel 权重,CROW pooling 能够在一定程度上加大感兴趣区域的权重,降低非物体区域的权重。其具体的特征表示构建过程如下图所示:
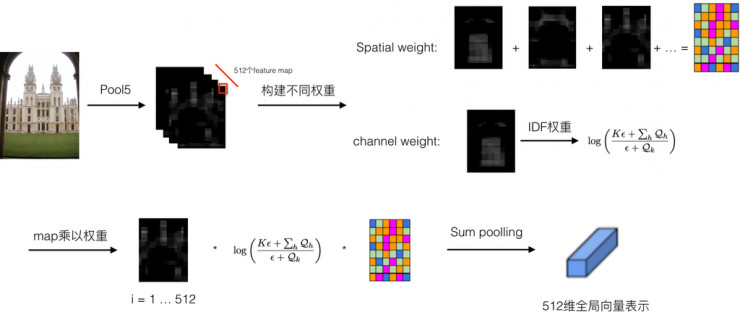
其核心的过程是 Spatial Weight 和 Channel Weight 两个权重。Spatial Weight 具体在计算的时候,是直接对每个 channel 的 feature map 求和相加,这个 Spatial Weight 其实可以理解为 saliency map。我们知道,通过卷积滤波,响应强的地方一般都是物体的边缘等,因而将多个通道相加求和后,那些非零且响应大的区域,也一般都是物体所在的区域,因而我们可以将它作为 feature map 的权重。Channel Weight 借用了 IDF 权重的思想,即对于一些高频的单词,比如 “the”,这类词出现的频率非常大,但是它对于信息的表达其实是没多大用处的,也就是它包含的信息量太少了,因此在 BoW 模型中,这类停用词需要降低它们的权重。借用到 Channel Weight 的计算过程中,我们可以想象这样一种情况,比如某一个 channel,其 feature map 每个像素值都是非零的,且都比较大,从视觉上看上去,白色区域占据了整个 feature map,我们可以想到,这个 channel 的 feature map 是不利于我们去定位物体的区域的,因此我们需要降低这个 channel 的权重,而对于白色区域占 feature map 面积很小的 channel,我们认为它对于定位物体包含有很大的信息,因此应该加大这种 channel 的权重。而这一现象跟 IDF 的思想特别吻合,所以作者采用了 IDF 这一权重定义了 Channel Weight。
总体来说,这个 Spatial Weight 和 Channel Weight 的设计还是非常巧妙的,不过这样一种 pooling 的方式只能在一定程度上契合感兴趣区域,我们可以看一下 Spatial Weight*Channel Weight 的热力图:

从上面可以看到,权重大的部分主要在塔尖部分,这一部分可以认为是 discriminate 区域,当然我们还可以看到,在图像的其他区域,还有一些比较大的权重分布,这些区域是我们不想要的。当然,从笔者可视化了一些其他的图片来看,这种 crow pooling 方式并不总是成功的,也存在着一些图片,其权重大的区域并不是图像中物体的主体。不过,从千万级图库上跑出来的结果来看,crow pooling 这种方式还是可以取得不错的效果。
RMAC pooling
RMAC pooling 的池化方式源自于 Particular object retrieval with integral max-pooling of CNN activations,三作是 Hervé Jégou(和 Matthijs Douze 是好基友)。在这篇文章中,作者提出来了一种 RMAC pooling 的池化方式,其主要的思想还是跟上面讲过的 MOP pooling 类似,采用的是一种变窗口的方式进行滑窗,只不过在滑窗的时候,不是在图像上进行滑窗,而是在 feature map 上进行的 (极大的加快了特征提取速度),此外在合并 local 特征的时候,MOP pooling 采用的是 VLAD 的方式进行合并的,而 RMAC pooling 则处理得更简单 (简单并不代表效果不好),直接将 local 特征相加得到最终的 global 特征。其具体的滑窗方式如下图所示:

图中示意的是三种窗口大小,图中‘x’代表的是窗口的中心,对于每一个窗口的 feature map,论文中采用的是 MAX pooling 的方式,在 L=3 时,也就是采用图中所示的三种窗口大小,我们可以得到 20 个 local 特征,此外,我们对整个 fature map 做一次 MAX pooling 会得到一个 global 特征,这样对于一幅图像,我们可以得到 21 个 local 特征 (如果把得到的 global 特征也视为 local 的话),这 21 个 local 特征直接相加求和,即得到最终全局的 global 特征。论文中作者对比了滑动窗口数量对 mAP 的影响,从 L=1 到 L=3,mAP 是逐步提升的,但是在 L=4 时,mAP 不再提升了。实际上 RMAC pooling 中设计的窗口的作用是定位物体位置的 (CROW pooling 通过权重图定位物体位置)。如上图所示,在窗口与窗口之间,都是一定的 overlap,而最终在构成 global 特征的时候,是采用求和相加的方式,因此可以看到,那些重叠的区域我们可以认为是给予了较大的权重。
上面说到的 20 个 local 特征和 1 个 global 特征,采用的是直接合并相加的方式,当然我们还可以把这 20 个 local 特征相加后再跟剩下的那一个 global 特征串接起来。实际实验的时候,发现串接起来的方式比前一种方式有 2%-3% 的提升。在规模 100 万的图库上测试,RMAC pooling 能够取得不错的效果,跟 Crow pooling 相比,两者差别不大。
上面总结了 6 中不同的 pooling 方式,当然还有很多的 pooling 方式没涵盖不到,在实际应用的时候,笔者比较推荐采用 RMAC pooling 和 CROW pooling 的方式,主要是这两种 pooling 方式效果比较好,计算复杂度也比较低。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。


















