【51CTO.com原创稿件】淘宝、天猫每天有上亿个不同的买卖家进行对话,产生百亿条聊天记录。对客服聊天记录的实时分析是实现智能客服的基础。本文主要分享云客服的整体架构,包括实时分析的场景、架构、技术难点,以及为何要从 NoSQL 迁移时序数据库和使用心得。
网购催生客服职能转型
如下图,是国内客服体系发展历程。
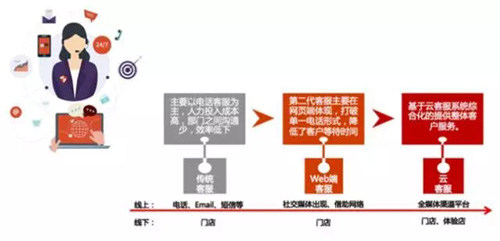
国内客服体系经历了传统客服、Web 端客户和云客服三个发展阶段。
传统客服以呼叫中心为主,主要以电话客服为主,人力投入成本高,部门之间沟通少,效率低下。
随着互联网发展,出现了 Web 端客服,它打破单一的电话形式,客服可同时接待多个用户,降低了客户等待时间和客服成本。
到了移动互联网时代,用户触达渠道越来越多,比较碎片化。聚合各渠道的反馈,并且保证各渠道一致的用户体验是提升企业服务质量的重要手段,因此出现了云客服。
多渠道和智能化是云客服最明显的两大特征。客服可以借助云客服平台,统一处理来自企业官网、APP、公众号等所有渠道的用户咨询,从而保证服务质量的统一。
同时通过机器人、智能提示、营销提示等智能插件,提升客服的工作效率,让客服具备销售的属性。
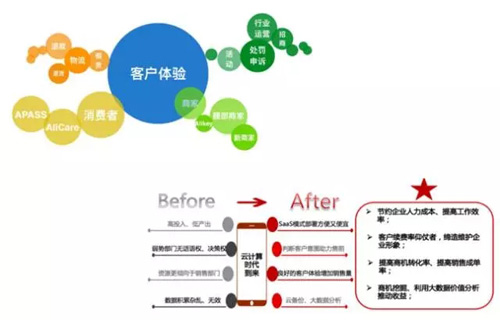
如下图,是客服职能转型前后对比图。
云客服的整体架构
如下图,是云客服的整体架构。
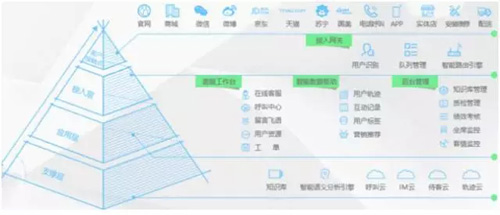
云客服架构自上而下可分为客户接触点、接入层、应用层和支撑层。
客户接触点。官网、商城、微信、微博等客服接触点会通过统一的接入网关接入到客服工作台。
接入层。接入层首先会识别用户身份,例如:VIP 还是普通用户,新用户还是老客户。不同的用户会自动路由到不同客服组进行服务。这些客服组在应答技巧、推荐内容等方面都有所差别。
应用层。应用层是整个云客服的核心,包括客服工作台、智能插件和客服管理三部分。客服通过客服工作台统一接待各种渠道的在线和电话咨询,并根据用户反馈形成各种工单分发给其他部门处理。
智能插件以给客服提能为主,例如:自动催单,物流、订单查询等,能大大减少客服的重复工作。以及智能的组合销售、营销活动提示,能大大提高客服的引导销售额。
客服管理包括知识库、质检、绩效考核、坐席、客情等,是客服主管或企业老板经常使用的功能。
支撑层。这层包括知识库、智能语义分析引擎、呼叫云、IM云、待客云和轨迹云等基础设施。
云客服的智能插件、客服管理等核心功能都依赖于聊天记录的实时分析能力,下面介绍下实时分析的场景、架构和关键技术问题。
实时分析场景
如下图,是云客服实时分析的几个场景。

热点问题分析。及时分析出用户反馈最多的问题,优先解决。特别在新品上线或大促时,作用很大。
实时接待。实时展示接待情况,哪个客服没按时上线,哪个店铺接待不过来,都一目了然。
实时质检。及时发现客服是否按规定交流,如是否用尊称,话术上是否达到要求等。还可分析客户情绪、满意度,及时介入客服与客户的争执。对于客服人员变化频繁、新客服多等情况很有用。
实时分析架构
如下图,是云客服的实时分析架构。
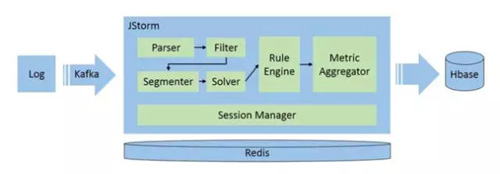
数据采集
数据采集阶段主要注意几个点:
- 尽可能采集更多的数据。“巧妇难为无米之炊”,以客服场景为例,除了聊天记录外,结合交易数据可以算出客服引导的成交量,结合浏览轨迹可以猜测用户的问题。
- 尽量降低性能消耗和实时性,这里可以用批量发送、日志不落磁盘直接发送等方式。
数据通道
数据通道主要是消息队列和 API 两种方式,消息队列传输原始数据,API 提供辅助的原数据。使用消息队列时要注意:
- 发送时注意消息体的大小,每种消息队列的***消息体大小都不一样,例如:RocketMQ 推荐 4KB。打包成***大小再发送可以***程度提高系统吞吐。
- 消费时是批量消费还是单条消费。一般数据量大,对精确度要求不高时用批量消费方式,可提高节点处理能力,但相对的,失败补偿和事务性比较难保证。
- 记录消息轨迹。有些消息队列可通过 MsgID 查询消息的生产端、消费端、消费次数等,方便丢消息或出现重复时进行排查。
- 支持消息重置。当消费端故障或发布时,往往要将消费的偏移(offset)设置到之前的某个时间点,重新消费。
实时计算引擎
常用的有 Storm、Spark 或 Flink,基本环节如下:
- 解析器(Parser)和过滤器(Filter),尽早把不需要的数据过滤掉,为后续的环节减轻压力。
- 分词器(Segmenter),分词的关键是词库的积累,不同行业、不同场景会有不同的术语,词库直接影响 Solver 的质量。
- 解答器(Solver),有三个功能。一是问题归类,如商品咨询、物流咨询、活动咨询等。二是话术检验,如:敏感词、礼貌用语等。三是情感分析,分析客户当前的情绪。
- 规则引擎(Rule Engine),根据前面分析和结合运营规则,计算业务指标。用规则引擎有两个好处,一是方便计算一些比较复杂的指标,如:复购率。
二是支持动态修改,像调整某个参数的权重这种需求,可即时修改生效,不用发布。
- 指标聚合器(Metric Aggregator),对算好的基础数据进行聚合,如按时间,一分钟、一小时把数据进行汇总、求评价或方差等。
数据存储
聚合后的数据会存储到Hbase。如下图,是基础的Hbase存储结构。

Rowkey = metric name + timestamp + tags
Rowkey 由指标名、时间戳和标识这个数据的一组键值对构成,后面会介绍如何对这种存储进行优化。
实时分析的常见问题
做海量数据的实时分析、聚合时,都会遇到一些问题,本文主要挑选数据倾斜、窗口切分和海量时间线这三个最常见的问题来解析。
问题一,数据倾斜
数据倾斜,也叫数据热点。如下图,上面是 MapReduce 过程,下面是流处理过程。
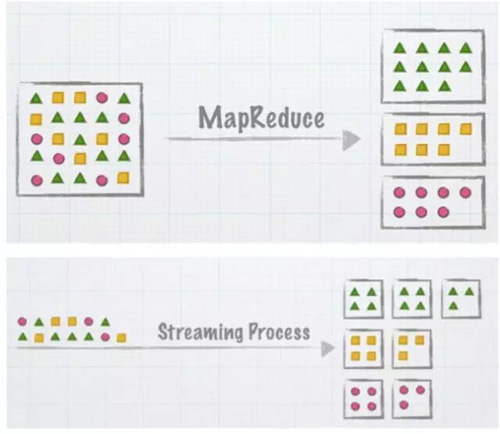
不管是 MapReduce 还是流处理,总有某类数据量会多于其他数据,如上图绿色三角比其他图形多。实际生产中热点数据的量可能是其他数据的几十倍。
这种数据热点的出现,会导致消息列队堆积,处理节点内存过高,出发 Full GC 或 OOM,***是工作节点的不停 crash 和迁移,从而加剧这种现象。
那么,如何应对呢?常见方法有:
- 尽可能细粒度 hash。以聊天记录示例,如果以用户为最小粒度,一个用户的所有聊天都 hash 到一起,那有些账号的数据会很多,就容易出现热点。
如果进一步细分,以聊天为最小粒度,把 A 和 B 聊天为一类、A 和 C 为另一类,这样数据就会均匀很多。
- 特殊 key 处理。大部分应用场景都会有一些标杆用户,其数据量是其他用户的几十倍,针对这类客户可以白名单的方式,进行特殊处理。
- 二段 Merge。把一次性的 Merge 操作划分成多次。一开始不要求把最终的结果统计出来,可先做局部的 Merge,再做***的 Merge,这样可缓解数据热点的问题。但相应的工作节点会变多,成本变高。
问题二:窗口切分
流式计算本质上是把源源不断的数据,按时间区间把数据给划分开,这个动作叫窗口切分。如下图,按照 5 秒或 15 秒进行切分:
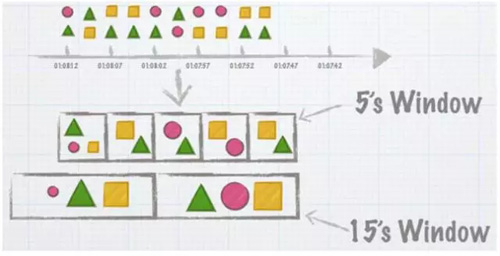
常见计算窗口有三种:固定窗口、滑动窗口和会话窗口。如下图:
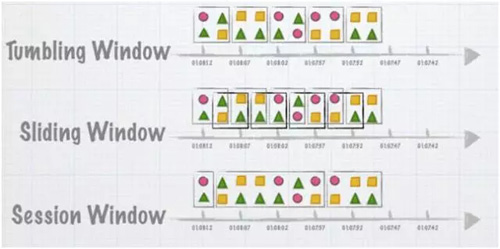
- 固定窗口。按照工作节点的系统时间,将数据按固定周期切开,之间没有重叠,这是理想状态。
事实上,由于分布式系统在系统时间、网络延时方面都会存在差异,工作节点收到数据的数据是乱序的,接收时间不能视作数据产生的时间。
- 滑动窗口。固定统计周期上加一个滑动时间,等滑动时间到了再保存结果,关闭窗口。例如:如果预估数据一般延迟 10s,那滑动时间可以设置为 15s,15s 之后才到达的数据。
可以考虑抛弃或者进行特殊的处理逻辑。滑动窗口要缓存的数据比固定窗口多,窗口关闭、状态存储、恢复也要复杂一些。
- 会话窗口。不以时间,而是以某些事件作为窗口的划分,就是会话窗口。以聊天为例,A 和 B 聊天,A 说了一句或多句话后,只有当 B 回复时,才形成一个窗口。这时可以得出响应时间、答问的次数等各类指标。
总体来说,处理难度上,Tumbling(固定) < Sliding(滑动) < Session(会话)。固定窗口只是理想的状态,用于实际场景会导致数据不精确。实际使用还是滑动窗口的多。
问题三:海量时间线
什么是时间线(Series)呢?数据按各时间区间统计出一个个的值,按时间进行展示就形成一条线,故称作时间线。如下图,三种图案形成三条时间线。

海量时间线是指当统计维度变多时,时间线个数会指数上涨!还是以聊天指标为例。

假设,每天有十万个买家和一万卖家聊天,每个聊天要统计 10 个指标,时间线的个数就是 10w *1w * 10 = 100 亿!
时间线的增加会导致存储的结果数据大大增加,存储成本升高、查询速度下降。因此,我们选择了时序数据库代替原来的 Hbase。
从 NoSQL 到时序数据库
面对实时聚合技术复杂、成本高等情况,是否有优化方案?时序数据库(TSDB)应运而生。
什么是 TSDB?它是专门存储按时间顺序变化(即时间序列化)的数据,支持原始数据查询和实时聚合,支持数据压缩,适合海量数据处理。
以下是比较热门的开源解决方案:
- InfluxDB。短小精悍,社区很活跃。但集群方案收费,适合小规模用户。
- OpenTSDB。基于 Hbase 的成熟的 TSDB 方案,被很多大公司使用。
- Druid。基于时间的 OLAP 列存数据库,长处在于 AD-Hoc 的聚合/分析。
如下图,是基于 NoSQL 预计算方案与基于时序数据库(TSDB)的实时聚合方案优劣对比。
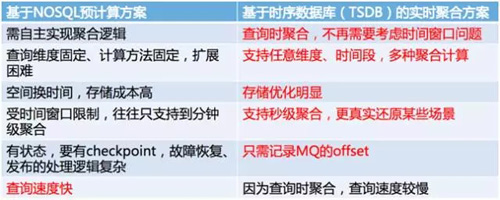
对比来看,TSDB 的方案能比较好的解决聚合逻辑复杂、存储成本高的问题,但由于聊天数据量大,查询慢的问题也比较严重。下面将以 OpenTSDB 为例,介绍其存储优化的原理和查询优化的经验。
OpenTSDB 存储优化原理
存储优化前,Rowkey = metric name + timestamp + tags 的组合。Rowkey 很长且重复很多。如下图。
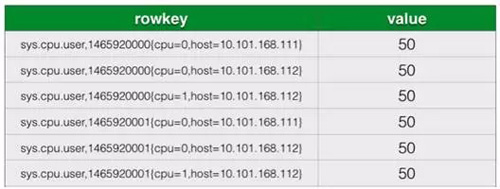
OpenTSDB 存储优化原理归纳如下:
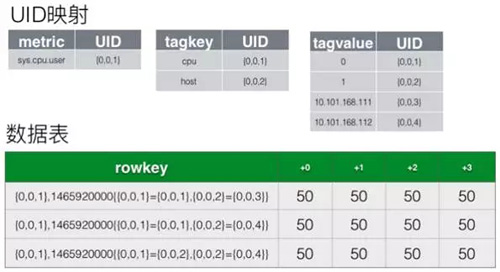
- 为每个 metric、tag key 和 tag value 都分配一个 UID,缩短 row key。
- 将同一小时的数据存储到不同的列中,减少 key-value 数。
- 使用偏移量时间戳,进一步减少列名占用空间。
优化后的存储结构如下图所示。
OpenTSDB 查询优化经验
OpenTSDB 查询优化可以从使用端和服务端两个方面着手:
使用端优化:
- 合理拆分 Metric,这类似于关系型数据库的分表,将相关性不强的属性拆开到多个 Metric 中,减少时间线个数,查询时自然会有所改进。
- 注意 Tag 顺序,要将经常指定维度往前排,最明显的就是用户 ID,查询数据时指定用户 ID 进行范围查询,Hbase Scan 的数量就会少很多。
- 并发查优化,OpenTSDB 默认是一个小时数据存一行,那么可以按小时把请求拆分,如查最近二十四小时就拆成二十四个请求进行查询,整体的响应时间就会有所改进。
服务端优化:
- 预集合,先把慢查询捞出来,提前去执行查询。查询之后,把结果存储到另一个地方。预集合可以由使用方或服务端实现。
服务端实现对使用方更友好,正如 InfluxDB 的 Continuous Queries 功能。
- 降精度,OpenTSDB 默认是每一秒存一个数据,假设只要一分钟,是不是可以每一分钟只记一个数据,那样数据量就会变成原来的六十分之一。
但是要注意降精度后,使用端要将这一分钟的数据先自行累加然后再发送到服务端,因为 Hbase 是默认覆盖而不进行累加。
- 结果缓存,这里不是指请求级别的结果缓存,而是要做到 Metric 或者时间线结果的缓存。
以上内容由编辑王雪燕根据李灼灵老师在 WOTA2017 “大数据应用创新”专场的演讲内容整理。
李灼灵 (千慕)
阿里巴巴资深研发工程师
在浙江大学计算机系本硕毕业后,加入阿里巴巴。先后在共享、商家事业部负责过 TAE、APM、客服 SAAS、千牛问答等产品的架构和研发工作,通过 Docker、流式计算、APM、SAAS 化等技术推动开放平台的架构升级。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】