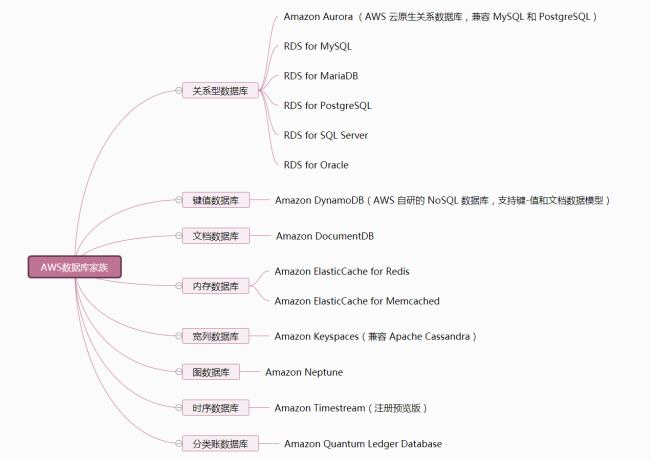
许多大型用户的数据库(仓库)在运行多年之后,都会积累出很多的数据表,严重者数以万计。这些数据表年代久远,有些已经忘记建设原因,甚至可能已不再有用,但因为很难确认而不敢删除。这给运维工作带来巨大的负担。伴随着这些表还有大量的存储过程仍在不断地向这些表更新数据,占用大量计算资源,经常要迫使数据库扩容。
这些表是真地业务需要吗需要吗?业务会复杂到需要成千上万的表才能描述吗?
有过开发经验的人都知道这不大可能,几百个表就能描述相当复杂的业务了。这些众多的表绝大多数都是所谓的中间表,并不是用来存储基础数据的。
一
那么,为什么会有中间表?中间表是用来做什么的?
一般来说,中间表会有内部和外部两种来源。
内部产生的中间表大多是为数据呈现(报表或查询)服务的。原始数据量很大时,直接基于原始数据计算汇总信息时的性能会很差,用户体验恶劣。这时,我们会先把一些汇总结果事先计算出,再基于这些中间结果产生报表,用户体验就会好很多。而这些中间数据就会以中间表的形式存储。有时候是因为计算过程很复杂,在生成报表时临时计算会使报表开发过于繁琐,也会采用中间表事先计算好。这类中间表都会伴随着存储过程去定时更新数据,不仅占用存储空间,还会消耗计算资源。而且,报表是业务稳定性比较差的业务,会经常修改和增加,随之而生的中间表也会越来越多。
那么,为什么要把中间数据以数据库表的形式存储呢?这主要是为了获得进一步的计算能力。数据呈现时,并不能简单地把计算好的中间数据直接取出来呈现,而仍然需要做一轮简单些的计算,比如根据参数进行过滤,有时还有再汇总的需求。而这些计算是数据库比较适合实现的,如果把中间数据保存成文件,则将失去计算能力,所以程序员会习惯于使用中间表。
二
来源于外部的中间表又有两种情况,一种是在ETL过程中产生的。ETL过程中常常会涉及到数据库的数据,正常的ETL过程应当是E、T、L这三个步骤逐步进行,也就是先清洗转换之后再加载进数据库,***在数据库中的只是合理的结果数据。但是,E(清洗)和T(转换)这两个步骤中会涉及到大量数据计算,而在数据库外实施这些计算很不方便,所以实际情况就会是把涉及到的所有数据都先加载进来然后再进行清洗和转换,ETL过程变成了ELT甚至LET。事先要加载的这些数据在关系数据库中也必须以表的形式存储,这就使数据库中增加了许多并非最终需要的中间表。
另一种情况是多样性数据源造成的,这也是为数据呈现(报表查询)服务的。现代应用中的数据呈现经常会涉及数据库外的数据,目前一般的做法是把库外数据定时导入到数据库中,然后就能和数据库内的数据一起运算产生报表,否则很难实现数据库内外的数据的混合运算。这当然也会让数据库中多了一些表,而且,有些互联网上取过来的数据常常是多层的json或XML格式,在关系数据库中还要建立多个关联的表来存储,会进一步加剧中间表过多的问题。
三
我们发现这几种情况的中间表都有一个共同点:就是要利用数据库的计算能力。数据库外缺乏强有力的计算能力,而数据库的计算能力又是封闭的(它不能计算数据库外的数据),这样,为了获得数据库的计算能力,我们就只能把许多数据先装入数据库,也就形成了中间表。
数据库的存储封闭性是有意义的,这样可以确保库内数据满足一条规则的约束性,保证数据的正确合理性。但计算能力的封闭性却没有什么必要,对于计算而言,本来也没有库内库外之分。但是数据库的计算模型是建立在其存储模型之上的,这就迫使其计算能力和存储能力一起封闭了,为了获得计算能力只能把数据库搞臃肿。这不仅给管理造成麻烦,而且由于数据库的存储及计算资源都相对昂贵,仅仅是为了获得计算能力就去扩容或部署新数据库,在经济上也不划算。
四
计算封闭性导致臃肿的数据库,而导致运维困难的还有数据库的另两个技术机制。
数据库是一个共享的独立进程,其计算能力在应用外部,而不从属于某个应用。各个应用共享数据库,都能访问数据库的资源。某个应用(模块)中生成的中间表或存储过程可能被另一个应用(模块)调用,这就造成了应用(模块)之间的耦合性,即使某个中间表的制造者已经下线不用,但因为可能被别的应用使用了而不能删除。
数据库的表还是一种线性组织。在条目数量不多时尚可,太多(几千上万时)就很难理解,人们一般会采用树状多层结构来组织管理众多的条目。但关系数据库并不支持这种方案(有个模式概念可理解为只能分两层),这时候就要给表较长的命名来区别其分类,这一方面使用不便,另一方面对开发管理水平要求很高,在工作较急迫时常常顾不上规范,而随便起个名字先把任务完成再说,时间长了,就会遗留大量的混乱中间表。
当然,根本问题还是在于计算封闭性。