本文记录了月前笔者参与阿里云中间件比赛中,实现的简要具有持久化功能的消息队列的设计与实现过程。需要声明的是,LocalMQ 借鉴了 RocketMQ 在 Broker 部分的核心设计思想,最早的源码也是基于 RocketMQ 源码改造而来。本文涉及引用以及其他消息队列相关资料参考这里,源代码放于 LocalMQ 仓库;另外笔者水平有限,后来因为毕业旅行也未继续优化,本文很多内容可能存在谬误与不足,请批评指正。
LocalMQ:从零构建类 RocketMQ 高性能消息队列
所谓消息队列,直观来看有点像蓄水池,能够在生产者与消费者之间完成解耦,并且平衡生产者与消费者之间的计算量与可计算时间之间的差异;目前主流的消息队列有著名的 Kafka、RabbitMQ、RocketMQ 等等。在笔者实现的 LocalMQ 中,从简到复依次实现了 MemoryMessageMQ、EmbeddedMessageQueue 与 LocalMessageQueue 这三个版本;需要说明的是,在三个版本的消息队列中,都是采取所谓的拉模式,即消费者主动向消息队列请求拉取消息的模式。在 wx.demo.* 包下提供了很多的内部功能与性能测试用例,
- // 首先在这里:https://parg.co/beX 下载代码
- // 然后修改 DefaultProducer 对应的继承类
- // 测试 MemoryMessageQueue,则继承 MemoryProducer;
- // 测试 EmbeddedMessageQueue,则继承 EmbeddedProducer;
- // 默认测试 LocalMessageQueue,注意,需要对 DefaultPullConsumer 进行同样修改
- public class DefaultProducer extends LocalProducer
- // 使用 mvn 运行测试用例,也可以在 Eclipse 或者 Intellij 中打开
- mvn clean package -U assembly:assembly -Dmaven.test.skip=true
- java -Xmx2048m -Xms2048m -cp open-messaging-wx.demo-1.0.jar wx.demo.benchmark.ProducerBenchmark
最简单的 MemoryMessageQueue 即是将消息数据按照选定主题存放在内存中,其主要结构如下图所示:
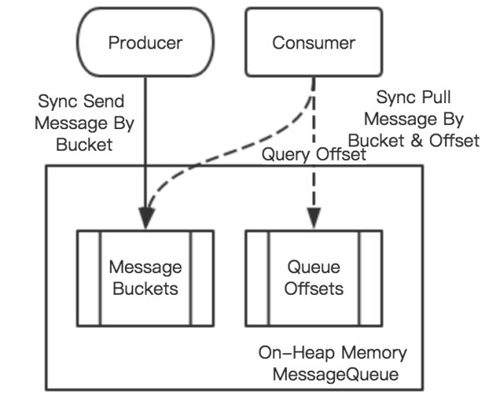
MemoryMessageQueue 提供了同步的消息提交与拉取操作,其利用 HashMap 堆上存储来缓存所有的消息;并且在内存中维护了另一个所谓的 QueueOffsets 来记录每个主题对应队列的消费偏移量。相较于 MemoryMessageQueue 实现的简单的不能进行持久化存储的消息队列,EmbeddedMessageQueue 则提供了稍微复杂点的支持磁盘持久化的消息队列。EmbeddedMessageQueue 构建了基于 Java NIO 提供的 MappedByteBuffer 的 MappedPartitionQueue。每个 MappedPartitionQueue 对应磁盘上的多个物理文件,并且为上层应用抽象提供了逻辑上的单一文件。EmbeddedMessageQueue 结构如下图所示:
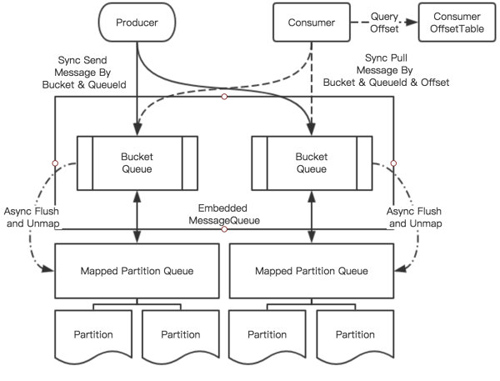
EmbeddedMessageQueue 的主要流程为生产者同步地像 Bucket Queue 中提交消息,每个 Bucket 可以视作某个主题(Topic)或者队列(Queue)。而 EmbeddedMessageQueue 还包含着负责定期将 MappedPartitionQueue 中数据持久化写入到磁盘的异步线程,该线程会定期地完成 Flush 操作。EmbeddedMessageQueue 假设某个 BucketQueue 被分配给某个 Consumer 之后就被其占用,该 Consumer 会消费其中全部的缓存消息;每个 Consumer 会包含独立地 Consumer Offset Table 来记录当前某个队列地消费情况。EmbeddedMessageQueue 的缺陷在于:
- 混合处理与标记位:EmbeddedMessageQueue 仅提供了最简单的消息序列化模型,无法记录额外的消息属性;
- 持久化存储到磁盘的时机:EmbeddedMessageQueue 仅使用了一级缓存,并且仅在某个 Partition 写满时才进行文件的持久化操作;
- 添加消息的后处理:EmbeddedMessageQueue 是将消息直接写入到 BucketQueue 包含的 MappedPartitionQueue 中,无法动态地进行索引、筛选等消息后处理,其可扩展性较差。
- 未考虑断续拉取的情况:EmbeddedMessageQueue 中是假设 Consumer 能够单次处理完某个 BucketQueue 中的单个 Partition 的全部消息,因此记录其处理值时也仅是记录了文件级别的位移,如果存在某次是仅拉取了单个 Partition 中部分内容,则下次的起始拉取点还是下个文件首。
EmbeddedMessageQueue 中我们可以在各 Producer 线程中单独将消息持久化入文件中,而在 LocalMessageQueue 中,我们是将消息统一写入 MessageStore 中,然后又 PostPutMessageService 进行二次处理。 LocalMessageQueue 的结构如下所示:
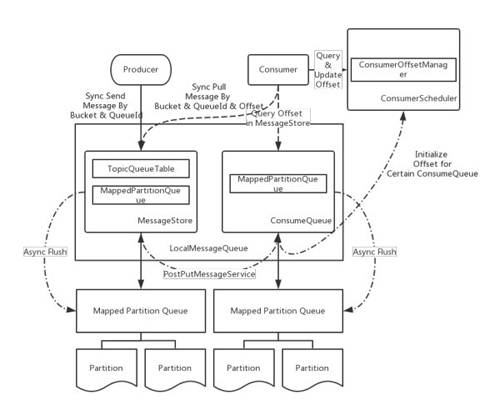
LocalMessageQueue 最大的变化在于将消息统一存储在独立地 MessageStore 中(类似于 RocketMQ 中的 CommitLog),然后针对 Topic-queueId 将消息划分到不同的 ConsumeQueue 中;这里的 queueId 是由对应的 Producer 专属编号决定的,每个 Consumer 即会被分配占用某个 ConsumeQueue(类似于 RocketMQ 中的 consumequeue),从而保证某个 Producer 生产的某个主题下的消息被专一的 Consumer 消费。LocalMessageQueue 同样使用 MappedPartitionQueue 提供底层文件系统抽象,并且构建了独立的 ConsumerOffsetManager 对消费者的消费进度进行管理,从而方便异常恢复。
设计概要
顺序消费
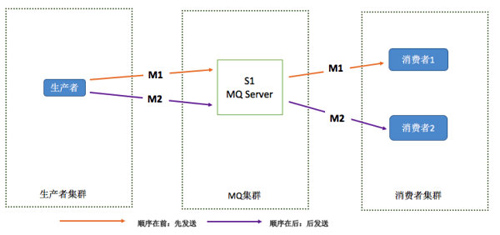
消息产品的一个重要特性是顺序保证,也就是消息消费的顺序要与发送的时间顺序保持一致;在多发送端的情况下,保证全局顺序代价比较大,只要求各个发送端的顺序有保障即可; 举个例子 P1 发送 M11, M12, M13,P2 发送 M21, M22, M23,在消费的时候,只要求保证 M11, M12, M13(M21,M22,M23)的顺序,也就是说,实际消费顺序为: M11, M21, M12, M13, M22, M23 正确; M11, M21, M22, M12, M13, M23 正确 M11, M13, M21, M22, M23, M12 错误,M12 与 M13 的顺序颠倒了;假如生产者产生了 2 条消息:M1、M2,要保证这两条消息的顺序,最直观的方式就是采取类似于 TCP 中的确认消息:
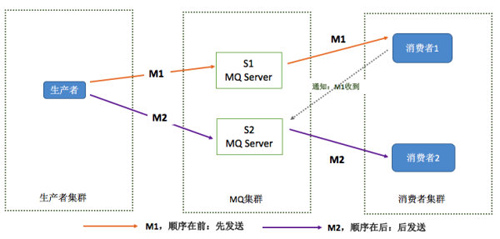
不过该模型中如果 M1 与 M2 分别被发送到了两台不同的消息服务器上,我们无法控制消息服务器发送 M1 与 M2 的先后时机;有可能 M2 已经被发送到了消费者,M1 才被发送到了消息服务器上。针对这个问题改进版的思路即是将 M1 与 M2 发送到单一消息服务器中,然后根据先到达先消费的原则发送给对应的消费者:
不过在实际情况下往往因为网络延迟或其他问题导致在 M1 发送耗时大于 M2 的情况下,M2 会先于 M1 被消费。因此如果我们要保证严格的顺序消息,那么必须要保证生产者、消息服务器与消费者之间的一对一对应关系。在 LocalMQ 的实现中,我们首先会将消息按照生产者划分到唯一的 Topic-queueId 队列中;并且保证同一时刻该消费队列只会被某个消费者独占。如果某个消费者在消费完该队列之前意外中断,那么在保留窗口期内不会将该队列重新分配;在窗口期之外则将该队列分配给新的消费者,并且即使原有消费者恢复工作也无法继续拉取该队列中包含的消息。
数据存储
LocalMQ 中目前是实现了基于文件系统的持久化存储,主要功能实现在 MappedPartition 与 MappedPartitionQueue 这两个类中,笔者也会在下文中详细介绍这两个类的实现。本部分我们讨论下数据存储的文件格式,对于 LocalMessageQueue 而言,其文件存储如下:
- * messageStore
- * -- MapFile1
- * -- MapFile2
- * consumeQueue
- * -- Topic1
- * ---- queueId1
- * ------ MapFile1
- * ------ MapFile2
- * ---- queueId2
- * ------ MapFile1
- * ------ MapFile2
- * -- Queue1
- * ---- queueId1
- * ------ MapFile1
- * ------ MapFile2
- * ---- queueId2
- * ------ MapFile1
- * ------ MapFile2
LocalMessageQueue 中采用了消息统一存储的方案,因此所有的消息实际内容会被存放在 messageStore 目录下。而 consumeQueue 中则存放了消息的索引,即在 messageStore 中的偏移地址。LocalMQ 中使用 MappedPartitionQueue 来管理某个逻辑上单一的文件,而根据不同的单文件大小限制会自动将其切割为多个物理上独立的 Mapped File。每个 MappedPartition 使用 offset,即该文件首地址的全局偏移量命名;而使用 pos / position 统一表示单文件中局部偏移量,使用 index 表示某个文件在其文件夹中的下标。
性能优化
在编写的过程中,笔者发现对于执行流的优化、避免重复计算与额外变量、选择使用合适的并发策略都会对结果造成极大的影响,譬如笔者从 SpinLock 切换到重入锁之后,本地测试 TPS 增加了约 5%。另外笔者也统计了消费者工作中不同阶段的时间占比,其中构建(包括消息属性的序列化)与发送操作(写入到 MappedFileQueue 中,未使用二级缓存)都是同步进行,二者的时间占比也是最多。
- [2017-06-01 12:13:21,802] INFO: 构建耗时占比:0.471270,发送耗时占比:0.428567,持久化耗时占比:0.100163
- [2017-06-01 12:25:31,275] INFO: 构建耗时占比:0.275170,发送耗时占比:0.573520,持久化耗时占比:0.151309
代码级别优化
笔者在实现 LocalMQ 的过程中感触最深的就是实现相同功能的不同代码在性能上的差异可能会很大。在实现过程中应该避免冗余变量声明与创建、避免额外空间申请与垃圾回收、避免冗余的执行过程;另外尽可能选用合适的数据结构,譬如笔者在部分实现中从 ArrayList 迁移到了 LinkedList,从 ConcurrentHashMap 迁移到了 HashMap,都带来了一定的评测指标提升。
异步 IO
异步 IO,顺序 Flush;笔者发现,如果多个线程进行并发 Flush 操作,反而不如单线程进行顺序 Flush。
并发控制
- 尽量减少锁控制的范围。
- 并发计算优化,将所有的耗时计算放到可以并发的 Producer 中。
- 使用合理的锁,重入锁相较于自旋锁有近 5 倍的 TPS 提升。
MemoryMessageQueue
源代码参考这里MemoryMessageQueue 是最简易的实现,不过其代码能够反映出某个消息队列的基本流程,首先在生产者我们需要创建消息并且发送给消息队列:
- // 创建消息
- BytesMessage message = messageFactory.createBytesMessageToTopic(topic, body);
- // 发送消息
- messageQueue.putMessage(topic, message);
在 putMessage 函数中则将消息存入内存存储中:
- // 存放所有消息
- private Map<String, ArrayList<Message>> messageBuckets = new HashMap<>();
- // 添加消息
- public synchronized PutMessageResult putMessage(String bucket, Message message) {
- if (!messageBuckets.containsKey(bucket)) {
- messageBuckets.put(bucket, new ArrayList<>(1024));
- }
- ArrayList<Message> bucketList = messageBuckets.get(bucket);
- bucketList.add(message);
- return new PutMessageResult(PutMessageStatus.PUT_OK, null);
- }
而 Consumer 则根据指定的 Bucket 与 queueId 来拉取消息,如果存在多个 Bucket 需要拉取则进行轮询:
- //use Round Robin
- int checkNum = 0;
- while (++checkNum <= bucketList.size()) {
- String bucket = bucketList.get((++lastIndex) % (bucketList.size()));
- Message message = messageQueue.pullMessage(queue, bucket);
- if (message != null) {
- return message;
- }
- }
而 MemoryMessageQueue 的 pullMessage 函数则首先判断目标 Bucket 是否存在,并且根据内置的 queueOffset 中记录的拉取偏移量来判断是否拉取完毕。若没有拉取完毕则返回消息并且更新本地偏移量;
- private Map<String, HashMap<String, Integer>> queueOffsets = new HashMap<>();
- ...
- public synchronized Message pullMessage(String queue, String bucket) {
- ...
- ArrayList<Message> bucketList = messageBuckets.get(bucket);
- if (bucketList == null) {
- return null;
- }
- HashMap<String, Integer> offsetMap = queueOffsets.get(queue);
- if (offsetMap == null) {
- offsetMap = new HashMap<>();
- queueOffsets.put(queue, offsetMap);
- }
- int offset = offsetMap.getOrDefault(bucket, 0);
- if (offset >= bucketList.size()) {
- return null;
- }
- Message message = bucketList.get(offset);
- offsetMap.put(bucket, ++offset);
- ...
- }
EmbeddedMessageQueue
源代码参考这里
EmbeddedMessageQueue 中引入了消息持久化支持,本部分我们也主要讨论消息序列化与底层的 MappedPartitionQueue 实现。
消息序列化
EmbeddedMessageQueue 中定义的消息格式如下:
序号消息存储结构备注长度(字节数)1TOTALSIZE消息大小42MAGICCODE消息的 MAGIC CODE43BODY前 4 个字节存放消息体大小值,后 bodyLength 大小的空间存储消息体内容4 + bodyLength4headers*前 2 个字节(short)存放头部大小,后存放 headersLength 大小的头部数据2 + headersLength5properties*前 2 个字节(short)存放属性值大小,后存放 propertiesLength 大小的属性数据2 + propertiesLength
- /**
- * Description 计算某个消息的长度,注意,headersByteArray 与 propertiesByteArray 在发送消息时完成转换
- * @param message
- * @param headersByteArray
- * @param propertiesByteArray
- * @return
- */
- public static int calMsgLength(DefaultBytesMessage message, byte[] headersByteArray, byte[] propertiesByteArray) {
- // 消息体
- byte[] body = message.getBody();
- int bodyLength = body == null ? 0 : body.length;
- // 计算头部长度
- short headersLength = (short) headersByteArray.length;
- // 计算属性长度
- short propertiesLength = (short) propertiesByteArray.length;
- // 计算消息体总长度
- return calMsgLength(bodyLength, headersLength, propertiesLength);
- }
而 EmbeddedMessageEncoder 的 encode 函数负责具体的消息序列化操作:
- /**
- * Description 执行消息的编码操作
- * @param message 消息对象
- * @param msgStoreItemMemory 内部缓存句柄
- * @param msgLen 计算的消息长度
- * @param headersByteArray 消息头字节序列
- * @param propertiesByteArray 消息属性字节序列
- */
- public static final void encode(
- DefaultBytesMessage message,
- final ByteBuffer msgStoreItemMemory,
- int msgLen,
- byte[] headersByteArray,
- byte[] propertiesByteArray
- ) {
- // 消息体
- byte[] body = message.getBody();
- int bodyLength = body == null ? 0 : body.length;
- // 计算头部长度
- short headersLength = (short) headersByteArray.length;
- // 计算属性长度
- short propertiesLength = (short) propertiesByteArray.length;
- // 初始化存储空间
- resetByteBuffer(msgStoreItemMemory, msgLen);
- // 1 TOTALSIZE
- msgStoreItemMemory.putInt(msgLen);
- // 2 MAGICCODE
- msgStoreItemMemory.putInt(MESSAGE_MAGIC_CODE);
- // 3 BODY
- msgStoreItemMemory.putInt(bodyLength);
- if (bodyLength > 0)
- msgStoreItemMemory.put(message.getBody());
- // 4 HEADERS
- msgStoreItemMemory.putShort((short) headersLength);
- if (headersLength > 0)
- msgStoreItemMemory.put(headersByteArray);
- // 5 PROPERTIES
- msgStoreItemMemory.putShort((short) propertiesLength);
- if (propertiesLength > 0)
- msgStoreItemMemory.put(propertiesByteArray);
- }
对应的反序列化操作则是由 EmbeddedMessageDecoder 完成,其主要从某个 ByteBuffer 中读取数据:
- /**
- * Description 从输入的 ByteBuffer 中反序列化消息对象
- *
- * @return 0 Come the end of the file // >0 Normal messages // -1 Message checksum failure
- */
- public static DefaultBytesMessage readMessageFromByteBuffer(ByteBuffer byteBuffer) {
- // 1 TOTAL SIZE
- int totalSize = byteBuffer.getInt();
- // 2 MAGIC CODE
- int magicCode = byteBuffer.getInt();
- switch (magicCode) {
- case MESSAGE_MAGIC_CODE:
- break;
- case BLANK_MAGIC_CODE:
- return null;
- default:
- // log.warning("found a illegal magic code 0x" + Integer.toHexString(magicCode));
- return null;
- }
- byte[] bytesContent = new byte[totalSize];
- // 3 BODY
- int bodyLen = byteBuffer.getInt();
- byte[] body = new byte[bodyLen];
- if (bodyLen > 0) {
- // 读取并且校验消息体内容
- byteBuffer.get(body, 0, bodyLen);
- }
- // 4 HEADERS
- short headersLength = byteBuffer.getShort();
- KeyValue headers = null;
- if (headersLength > 0) {
- byteBuffer.get(bytesContent, 0, headersLength);
- String headersStr = new String(bytesContent, 0, headersLength, EmbeddedMessageDecoder.CHARSET_UTF8);
- headers = string2KeyValue(headersStr);
- }
- // 5 PROPERTIES
- // 获取 properties 尺寸
- short propertiesLength = byteBuffer.getShort();
- KeyValue properties = null;
- if (propertiesLength > 0) {
- byteBuffer.get(bytesContent, 0, propertiesLength);
- String propertiesStr = new String(bytesContent, 0, propertiesLength, EmbeddedMessageDecoder.CHARSET_UTF8);
- properties = string2KeyValue(propertiesStr);
- }
- // 返回读取到的消息
- return new DefaultBytesMessage(
- totalSize,
- headers,
- properties,
- body
- );
- }
消息写入
EmbeddedMessageQueue 中消息的写入实际上是由 BucketQueue 的 putMessage/putMessages 函数完成的,这里的某个 BucketQueue 就对应着 Topic-queueId 这个唯一的标识。这里以批量写入消息为例,首先我们从 BucketQueue 包含的 MappedPartitionQueue 中获取到最新可用的某个 MappedPartition:
- mappedPartition = this.mappedPartitionQueue.getLastMappedFileOrCreate(0);
然后调用 MappedPartition 的 appendMessages 方法,该方法会在下文介绍;这里则是要讨论添加消息的几种结果对应的处理。如果添加成功,则直接返回成功;如果该 MappedPartition 剩余空间不足以写入消息队列中的某条消息,则需要调用 MappedPartitionQueue 创建新的 MappedPartition,并且重新计算待写入的消息序列:
- ...
- // 调用对应的 MappedPartition 追加消息
- // 注意,这里经过填充之后,会逆向地将消息在 MessageStore 中的偏移与 QueueOffset 中偏移添加进去
- result = mappedPartition.appendMessages(messages, this.appendMessageCallback);
- // 根据追加结果进行不同的操作
- switch (result.getStatus()) {
- case PUT_OK:
- break;
- case END_OF_FILE:
- this.messageQueue.getFlushAndUnmapPartitionService().putPartition(mappedPartition);
- // 如果已经到了文件最后,则创建新文件
- mappedPartition = this.mappedPartitionQueue.getLastMappedFileOrCreate(0);
- if (null == mappedPartition) {
- // XXX: warn and notify me
- log.warning("创建 MappedPartition 错误, topic: " + messages.get(0).getTopicOrQueueName());
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, result);
- }
- // 否则重新进行添加操作
- // 从结果中获取处理完毕的消息数
- int appendedMessageNum = result.getAppendedMessageNum();
- // 创建临时的 LeftMessages
- ArrayList<DefaultBytesMessage> leftMessages = new ArrayList<>();
- // 添加所有未消费的消息
- for (int i = appendedMessageNum; i < messages.size(); i++) {
- leftMessages.add(messages.get(i));
- }
- result = mappedPartition.appendMessages(leftMessages, this.appendMessageCallback);
- break;
- case MESSAGE_SIZE_EXCEEDED:
- case PROPERTIES_SIZE_EXCEEDED:
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, result);
- case UNKNOWN_ERROR:
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
- default:
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
- }
- ...
逻辑文件存储
Mapped Partition
某个 MappedPartition 映射物理上的单个文件,其初始化时如下传入文件名与文件尺寸属性:
- /**
- * Description 初始化某个内存映射文件
- *
- * @param fileName 文件名
- * @param fileSize 文件尺寸
- * @throws IOException 打开文件出现异常
- */
- private void init(final String fileName, final int fileSize) throws IOException {
- ...
- // 从文件名中获取到当前文件的全局偏移量
- this.fileFromOffset = Long.parseLong(this.file.getName());
- ...
- // 尝试打开文件
- this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
- // 将文件映射到内存中
- this.mappedByteBuffer = this.fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize);
- }
初始化阶段即打开文件映射,而后在写入消息或者其他内容时,其会调用传入的消息编码回调(即是我们上文中介绍的消息序列化的包裹对象)将对象编码为字节流并且写入:
- public AppendMessageResult appendMessage(final DefaultBytesMessage message, final AppendMessageCallback cb) {
- ...
- // 获取当前的写入位置
- int currentPos = this.wrotePosition.get();
- // 如果当前还是可写的
- if (currentPos < this.fileSize) {
- // 获取到实际的写入句柄
- ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
- // 调整当前写入位置
- byteBuffer.position(currentPos);
- // 记录信息
- AppendMessageResult result = null;
- // 调用回调函数中的实际写入操作
- result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, message);
- this.wrotePosition.addAndGet(result.getWroteBytes());
- this.storeTimestamp = result.getStoreTimestamp();
- return result;
- }
- ...
- }
MappedPartitionQueue
MappedPartitionQueue 用来管理多个物理上的映射文件,其构造函数如下:
- // 存放所有的映射文件
- private final CopyOnWriteArrayList<MappedPartition> mappedPartitions = new CopyOnWriteArrayList<MappedPartition>();
- ...
- /**
- * Description 默认构造函数
- *
- * @param storePath 传入的存储文件目录,有可能传入 MessageStore 目录或者 ConsumeQueue 目录
- * @param mappedFileSize
- * @param allocateMappedPartitionService
- */
- public MappedPartitionQueue(final String storePath, int mappedFileSize,
- AllocateMappedPartitionService allocateMappedPartitionService) {
- this.storePath = storePath;
- this.mappedFileSize = mappedFileSize;
- this.allocateMappedPartitionService = allocateMappedPartitionService;
- }{}
这里以 load 函数为例说明其加载过程:
- /**
- * Description 加载内存映射文件序列
- *
- * @return
- */
- public boolean load() {
- // 读取存储路径
- File dir = new File(this.storePath);
- // 列举目录下所有文件
- File[] files = dir.listFiles();
- // 如果文件不为空,则表示有必要加载
- if (files != null) {
- // 重排序
- Arrays.sort(files);
- // 遍历所有的文件
- for (File file : files) {
- // 如果碰到某个文件尚未填满,则返回加载完毕
- if (file.length() != this.mappedFileSize) {
- log.warning(file + "\t" + file.length()
- + " length not matched message store config value, ignore it");
- return true;
- }
- // 否则加载文件
- try {
- // 实际读取文件
- MappedPartition mappedPartition = new MappedPartition(file.getPath(), mappedFileSize);
- // 设置当前文件指针到文件尾
- mappedPartition.setWrotePosition(this.mappedFileSize);
- mappedPartition.setFlushedPosition(this.mappedFileSize);
- // 将文件放置到 MappedFiles 数组中
- this.mappedPartitions.add(mappedPartition);
- // log.info("load " + file.getPath() + " OK");
- } catch (IOException e) {
- log.warning("load file " + file + " error");
- return false;
- }
- }
- }
- return true;
- }
异步预创建文件
处于性能的考虑,MappedPartitionQueue 还会提前创建文件,在 getLastMappedFileOrCreate 函数中,当 allocateMappedPartitionService 存在的情况下则会调用该异步服务预创建文件:
- /**
- * Description 根据起始偏移量查找最后一个文件
- *
- * @param startOffset
- * @return
- */
- public MappedPartition getLastMappedFileOrCreate(final long startOffset) {
- ...
- // 如果有必要创建文件
- if (createOffset != -1) {
- // 获取到下一个文件的路径与文件名
- String nextFilePath = this.storePath + File.separator + FSExtra.offset2FileName(createOffset);
- // 以及下下个文件的路径与文件名
- String nextNextFilePath = this.storePath + File.separator
- + FSExtra.offset2FileName(createOffset + this.mappedFileSize);
- // 指向待创建的映射文件句柄
- MappedPartition mappedPartition = null;
- // 判断是否存在创建映射文件的服务
- if (this.allocateMappedPartitionService != null) {
- // 使用服务创建
- mappedPartition = this.allocateMappedPartitionService.putRequestAndReturnMappedFile(nextFilePath,
- nextNextFilePath, this.mappedFileSize);
- // 进行预热处理
- } else {
- // 否则直接创建
- try {
- mappedPartition = new MappedPartition(nextFilePath, this.mappedFileSize);
- } catch (IOException e) {
- log.warning("create mappedPartition exception");
- }
- }
- ...
- return mappedPartition;
- }
- return mappedPartitionLast;
- }
这里的 AllocateMappedPartitionService 则会不间断地执行创建文件的请求:
- @Override
- public void run() {
- ...
- // 循环执行文件分配请求
- while (!this.isStopped() && this.mmapOperation()) {}
- ...
- }
- /**
- * Description 循环执行映射文件预分配
- *
- * @Exception Only interrupted by the external thread, will return false
- */
- private boolean mmapOperation() {
- ...
- // 执行操作
- try {
- // 取出最新的执行对象
- req = this.requestQueue.take();
- // 取得待执行对象在请求表中的实例
- AllocateRequest expectedRequest = this.requestTable.get(req.getFilePath());
- ...
- // 判断是否已经存在创建好的对象
- if (req.getMappedPartition() == null) {
- // 记录起始创建时间
- long beginTime = System.currentTimeMillis();
- // 构建内存映射文件对象
- MappedPartition mappedPartition = new MappedPartition(req.getFilePath(), req.getFileSize());
- ...
- // 进行文件预热,仅预热 MessageStore
- if (mappedPartition.getFileSize() >= mapedFileSizeCommitLog && isWarmMappedFileEnable) {
- mappedPartition.warmMappedFile();
- }
- // 将创建好的对象回写到请求中
- req.setMappedPartition(mappedPartition);
- // 异常设置为 false
- this.hasException = false;
- // 成功设置为 true
- isSuccess = true;
- }
- ...
- }
异步 Flush
EmbeddedMessageQueue 中还包含了某个 flushAndUnmapPartitionServices 用于异步 Flush 文件并且完成不用映射文件的关闭操作。该服务的核心代码如下:
- private final ConcurrentLinkedQueue<MappedPartition> mappedPartitions = new ConcurrentLinkedQueue<>();
- ...
- @Override
- public void run() {
- while (!this.isStopped()) {
- int interval = 100;
- try {
- if (this.mappedPartitions.size() > 0) {
- long startTime = now();
- // 取出待处理的 MappedPartition
- MappedPartition mappedPartition = this.mappedPartitions.poll();
- // 将当前内容写入到磁盘
- mappedPartition.flush(0);
- // 释放当前不需要使用的空间
- mappedPartition.cleanup();
- long past = now() - startTime;
- // EmbeddedProducer.flushEclipseTime.addAndGet(past);
- if (past > 500) {
- log.info("Flush data to disk and unmap MappedPartition costs " + past + " ms:" + mappedPartition.getFileName());
- }
- } else {
- // 定时进行 Flush 操作
- this.waitForRunning(interval);
- }
- } catch (Throwable e) {
- log.warning(this.getServiceName() + " service has exception. ");
- }
- }
- }
这里的 mappedPartitions 即是在上文介绍的当添加消息且返回为 END_OF_FILE 时候添加进来的。
LocalMessageQueue
源代码参考这里
消息存储
LocalMessageQueue 中采用了中心化的消息存储方案,其提供的 putMessage / putMessages 函数实际上会调用内置 MessageStore 对象的消息写入函数:
- // 使用 MessageStore 进行提交
- PutMessageResult result = this.messageStore.putMessage(message);
而 MessageStore 即是存放所有真实消息的中心存储,LocalMessageQueue 中支持更为复杂的消息属性:
序号消息存储结构备注长度(字节数)1TOTALSIZE消息大小42MAGICCODE消息的 MAGIC CODE43BODYCRC消息体 BODY CRC,用于重启时校验44QUEUEID队列编号,queueID45QUEUEOFFSET自增值,不是真正的 consume queue 的偏移量,可以代表这个队列中消息的个数,要通过这个值查找到 consume queue 中数据,QUEUEOFFSET * 12 才是偏移地址86PHYSICALOFFSET消息在 commitLog 中的物理起始地址偏移量87STORETIMESTAMP存储时间戳88BODY前 4 个字节存放消息体大小值,后 bodyLength 大小的空间存储消息体内容4 + bodyLength9TOPICORQUEUENAME前 1 个字节存放 Topic 大小,后存放 topicOrQueueNameLength 大小的主题名1 + topicOrQueueNameLength10headers*前 2 个字节(short)存放头部大小,后存放 headersLength 大小的头部数据2 + headersLength11properties*前 2 个字节(short)存放属性值大小,后存放 propertiesLength 大小的属性数据2 + propertiesLength
其构造函数中初始化创建的 MappedPartitionQueue 是按照固定大小(默认单文件 1G)的映射文件组:
- // 构造映射文件类
- this.mappedPartitionQueue = new MappedPartitionQueue(
- ((LocalMessageQueueConfig) this.messageStore.getMessageQueueConfig()).getStorePathCommitLog(),
- mapedFileSizeCommitLog,
- messageStore.getAllocateMappedPartitionService(),
- this.flushMessageStoreService
- );
构建 ConsumeQueue
不同于 EmbeddedMessageQueue,LocalMessageQueue 并没有在初次提交消息时就直接写入按照 Topic-queueId 划分的存储内;而是依赖于内置的 PostPutMessageService :
- /**
- * Description 执行消息后操作
- */
- private void doReput() {
- for (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) {
- ...
- // 读取当前的消息
- SelectMappedBufferResult result = this.messageStore.getMessageStore().getData(reputFromOffset);
- // 如果消息不存在,则停止当前操作
- if (result == null) {
- doNext = false;
- continue;
- }
- try {
- // 获取当前消息的起始位置
- this.reputFromOffset = result.getStartOffset();
- // 顺序读取所有消息
- for (int readSize = 0; readSize < result.getSize() && doNext; ) {
- // 读取当前位置的消息
- PostPutMessageRequest postPutMessageRequest =
- checkMessageAndReturnSize(result.getByteBuffer());
- int size = postPutMessageRequest.getMsgSize();
- readSpendTime.addAndGet(now() - startTime);
- startTime = now();
- // 如果处理成功
- if (postPutMessageRequest.isSuccess()) {
- if (size > 0) {
- // 执行消息写入到 ConsumeQueue 的操作
- this.messageStore.putMessagePositionInfo(postPutMessageRequest);
- // 修正当前读取的位置
- this.reputFromOffset += size;
- readSize += size;
- } else if (size == 0) {
- this.reputFromOffset = this.messageStore.getMessageStore().rollNextFile(this.reputFromOffset);
- readSize = result.getSize();
- }
- putSpendTime.addAndGet(now() - startTime);
- } else if (!postPutMessageRequest.isSuccess()) {
- ...
- }
- }
- } finally {
- result.release();
- }
- }
- }
而在 putMessagePositionInfo 函数中即进行实际的 ConsumeQueue 创建:
- /**
- * Description 将消息的位置放置到 ConsumeQueue 中
- *
- * @param postPutMessageRequest
- */
- public void putMessagePositionInfo(PostPutMessageRequest postPutMessageRequest) {
- // 寻找或者创建 ConsumeQueue
- ConsumeQueue cq = this.findConsumeQueue(postPutMessageRequest.getTopic(), postPutMessageRequest.getQueueId());
- // 将消息放置到 ConsumeQueue 中合适的位置
- cq.putMessagePositionInfoWrapper(postPutMessageRequest.getCommitLogOffset(), postPutMessageRequest.getMsgSize(), postPutMessageRequest.getConsumeQueueOffset());
- }
- /**
- * Description 根据主题与 QueueId 查找 ConsumeQueue,如果不存在则创建
- *
- * @param topic
- * @param queueId
- * @return
- */
- public ConsumeQueue findConsumeQueue(String topic, int queueId) {
- ConcurrentHashMap<Integer, ConsumeQueue> map = consumeQueueTable.get(topic);
- ...
- // 判断该主题下是否存在 queueId,不存在则创建
- ConsumeQueue logic = map.get(queueId);
- // 如果获取为空,则创建新的 ConsumeQueue
- if (null == logic) {
- ConsumeQueue newLogic = new ConsumeQueue(//
- topic, // 主题
- queueId, // queueId
- LocalMessageQueueConfig.mapedFileSizeConsumeQueue, // 映射文件尺寸
- this);
- ConsumeQueue oldLogic = map.putIfAbsent(queueId, newLogic);
- ...
- }
- return logic;
- }
而在 ConsumeQueue 的构造函数中完成实际的文件映射与读取:
- /**
- * Description 主要构造函数
- *
- * @param topic
- * @param queueId
- * @param mappedFileSize
- * @param localMessageStore
- */
- public ConsumeQueue(
- final String topic,
- final int queueId,
- final int mappedFileSize,
- final LocalMessageQueue localMessageStore) {
- ...
- // 当前队列的路径
- String queueDir = this.storePath
- + File.separator + topic
- + File.separator + queueId;
- // 初始化内存映射队列
- this.mappedPartitionQueue = new MappedPartitionQueue(queueDir, mappedFileSize, null);
- this.byteBufferIndex = ByteBuffer.allocate(CQ_STORE_UNIT_SIZE);
- }
ConsumeQueue 的文件格式则相对简单:
- // ConsumeQueue 文件内存放的单条 Message 尺寸
- // 1 | MessageStore Offset | int 8 Byte
- // 2 | Size | short 8 Byte
消息拉取
在 LocalPullConsumer 拉取消息时,设置的批量拉取机制;即一次性从 LocalMessageQueue 拉取多条消息到本地,然后再批次返回给本地进行处理(假设处理也有一定耗时)。在批次拉取的函数中,我们首先需要获取当前 Consumer 处理的主题与队列编号对应的 ConsumeQueue 是否包含数据,然后再申请具体的读取句柄并且占用该队列:
- /**
- * Description 批量抓取消息,注意,这里只进行预抓取,仅当消费者真正获取后才会修正读取偏移量
- */
- private void batchPoll() {
- // 如果是 LocalMessageQueue
- // 执行预抓取
- LocalMessageQueue localMessageStore = (LocalMessageQueue) this.messageQueue;
- // 获取当前待抓取的桶名
- String bucket = bucketList.get((lastIndex) % (bucketList.size()));
- // 首先获取待抓取的队列和偏移
- long offsetInQueue = localMessageStore.getConsumerScheduler().queryOffsetAndLock("127.0.0.1:" + this.refId, bucket, this.getQueueId());
- // 如果当前待抓取的 queueId 已经被占用,则直接切换到下一个主题
- if (offsetInQueue == -2) {
- // 将当前主题设置为 true
- this.isFinishedTable.put(bucket, true);
- // 重置当前的 LastIndex 或者 RefOffset,即 queueId
- this.resetLastIndexOrRefOffsetWhenNotFound();
- } else {
- // 获取到了有效的队列偏移量之后,开始尝试获取消息
- consumerOffsetTable.put(bucket, new AtomicLong(offsetInQueue));
- // 设置每次最多抓一个文件内包含的消息数,等价于变相的一次性读完,注意,这里的数目还受到单个文件尺寸的限制
- GetMessageResult getMessageResult = localMessageStore.getMessage(bucket, this.getQueueId(), this.consumerOffsetTable.get(bucket).get() + 1, mapedFileSizeConsumeQueue / ConsumeQueue.CQ_STORE_UNIT_SIZE);
- // 如果没有找到数据,则切换到下一个
- if (getMessageResult.getStatus() != GetMessageStatus.FOUND) {
- // 将当前主题设置为 true
- this.isFinishedTable.put(bucket, true);
- this.resetLastIndexOrRefOffsetWhenNotFound();
- } else {
- // 这里不考虑 Consumer 被恶意干掉的情况,因此直接更新远端的 Offset 值
- localMessageStore.getConsumerScheduler().updateOffset("127.0.0.1:" + this.refId, bucket, this.getQueueId(), consumerOffsetTable.get(bucket).addAndGet(getMessageResult.getMessageCount()));
- // 首先从文件系统中一次性读出所有的消息
- ArrayList<DefaultBytesMessage> messages = readMessagesFromGetMessageResult(getMessageResult);
- // 将消息添加到队列中
- this.messages.addAll(messages);
- // 本次抓取成功后才开始抓取下一个
- lastIndex++;
- }
- }
- }
消费者调度
ConsumerScheduler 为我们提供了核心的消费者调度功能,其内置的 ConsumerOffsetManager 包含了两个核心存储:
- // 存放映射到内存中
- private ConcurrentHashMap<String/* topic */, ConcurrentHashMap<Integer/*queueId*/, Long>> offsetTable =
- new ConcurrentHashMap<String, ConcurrentHashMap<Integer, Long>>(512);
- // 存放某个 Topic 下面的某个 Queue 被某个 Consumer 占用的信息
- private ConcurrentHashMap<String/* topic */, ConcurrentHashMap<Integer/*queueId*/, String/*refId*/>> queueIdOccupiedByConsumerTable =
- new ConcurrentHashMap<String, ConcurrentHashMap<Integer, String>>(512);
分别对应了某个 ConsumeQueue 被消费的进度和被消费者的占用信息。同时 ConsumerOffsetManager 还提供了基于 JSON 格式的持久化功能,并且通过 ConsumerScheduler 中的定期服务 scheduledExecutorService 进行自动定期持久化。在消息提交阶段,LocalMessageQueue 会自动调用 updateOffset 函数更初始化某个 ConsumeQueue 的偏移情况(在恢复时也会使用):
- public void updateOffset(final String topic, final int queueId, final long offset) {
- this.consumerOffsetManager.commitOffset("Broker Inner", topic, queueId, offset);
- }
而某个 Consumer 在初次拉取时,会调用 queryOffsetAndLock 函数来查询某个 ConsumeQueue 的可拉取情况:
- /**
- * Description 修正某个 ConsumerOffset 队列中的值
- *
- * @param topic
- * @param queueId
- * @return
- */
- public long queryOffsetAndLock(final String clientHostAndPort, final String topic, final int queueId) {
- String key = topic;
- // 首先判断该 Topic-queueId 是否被占用
- if (this.queueIdOccupiedByConsumerTable.containsKey(topic)) {
- ...
- }
- // 如果没有被占用,则此时宣告占用
- ConcurrentHashMap<Integer, String> consumerQueueIdMap = this.queueIdOccupiedByConsumerTable.get(key);
- ...
- // 真实进行查找操作
- ConcurrentHashMap<Integer, Long> map = this.offsetTable.get(key);
- if (null != map) {
- Long offset = map.get(queueId);
- if (offset != null)
- return offset;
- }
- // 默认返回值为 -1
- return -1;
- }
并且在拉取完毕后调用 updateOffset 函数来更新拉取进度。
消息读取
在某个 Consumer 通过 ConsumerManager 获取可用的拉取偏移量之后,即从 LocalMessageQueue 中进行真实地消息读取操作:
- /**
- * Description Consumer 从存储中读取数据的接口
- *
- * @param topic
- * @param queueId
- * @param offset 下一个开始抓取的起始下标
- * @param maxMsgNums
- * @return
- */
- public GetMessageResult getMessage(final String topic, final int queueId, final long offset, final int maxMsgNums) {
- ...
- // 根据 Topic 与 queueId 构建消费者队列
- ConsumeQueue consumeQueue = findConsumeQueue(topic, queueId);
- // 保证当前 ConsumeQueue 存在
- if (consumeQueue != null) {
- // 获取当前 ConsumeQueue 中包含的最小的消息在 MessageStore 中的位移
- minOffset = consumeQueue.getMinOffsetInQueue();
- // 注意,最大的位移地址即是不可达地址,是当前所有消息的下一个消息的下标
- maxOffset = consumeQueue.getMaxOffsetInQueue();
- // 如果 maxOffset 为零,则表示没有可用消息
- if (maxOffset == 0) {
- status = GetMessageStatus.NO_MESSAGE_IN_QUEUE;
- nextBeginOffset = 0;
- } else if (offset < minOffset) {
- status = GetMessageStatus.OFFSET_TOO_SMALL;
- nextBeginOffset = minOffset;
- } else if (offset == maxOffset) {
- status = GetMessageStatus.OFFSET_OVERFLOW_ONE;
- nextBeginOffset = offset;
- } else if (offset > maxOffset) {
- status = GetMessageStatus.OFFSET_OVERFLOW_BADLY;
- if (0 == minOffset) {
- nextBeginOffset = minOffset;
- } else {
- nextBeginOffset = maxOffset;
- }
- } else {
- // 根据偏移量获取当前 ConsumeQueue 的缓存
- SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
- if (bufferConsumeQueue != null) {
- try {
- status = GetMessageStatus.NO_MATCHED_MESSAGE;
- long nextPhyFileStartOffset = Long.MIN_VALUE;
- long maxPhyOffsetPulling = 0;
- int i = 0;
- // 设置每次获取的最大消息数
- final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
- // 遍历所有的 Consume Queue 中的消息指针
- for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
- long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
- int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
- maxPhyOffsetPulling = offsetPy;
- if (nextPhyFileStartOffset != Long.MIN_VALUE) {
- if (offsetPy < nextPhyFileStartOffset)
- continue;
- }
- boolean isInDisk = checkInDiskByCommitOffset(offsetPy, maxOffsetPy);
- if (isTheBatchFull(sizePy, maxMsgNums, getResult.getBufferTotalSize(), getResult.getMessageCount(),
- isInDisk)) {
- break;
- }
- // 从 MessageStore 中获取消息
- SelectMappedBufferResult selectResult = this.messageStore.getMessage(offsetPy, sizePy);
- // 如果没有获取到数据,则切换到下一个文件继续
- if (null == selectResult) {
- if (getResult.getBufferTotalSize() == 0) {
- status = GetMessageStatus.MESSAGE_WAS_REMOVING;
- }
- nextPhyFileStartOffset = this.messageStore.rollNextFile(offsetPy);
- continue;
- }
- // 如果获取到了,则返回结果
- getResult.addMessage(selectResult);
- status = GetMessageStatus.FOUND;
- nextPhyFileStartOffset = Long.MIN_VALUE;
- }
- nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
- long diff = maxOffsetPy - maxPhyOffsetPulling;
- // 获取当前内存情况
- long memory = (long) (getTotalPhysicalMemorySize()
- * (LocalMessageQueueConfig.accessMessageInMemoryMaxRatio / 100.0));
- getResult.setSuggestPullingFromSlave(diff > memory);
- } finally {
- bufferConsumeQueue.release();
- }
- } else {
- status = GetMessageStatus.OFFSET_FOUND_NULL;
- nextBeginOffset = consumeQueue.rollNextFile(offset);
- log.warning("consumer request topic: " + topic + "offset: " + offset + " minOffset: " + minOffset + " maxOffset: "
- + maxOffset + ", but access logic queue failed.");
- }
- }
- } else {
- ...
- }
- ...
- }
注意,这里返回的其实只是消息在 MessageStore 中的存放地址,真实地消息读取还需要通过 readMessagesFromGetMessageResult 函数:
- /**
- * Description 从 GetMessageResult 中抓取全部的消息
- *
- * @param getMessageResult
- * @return
- */
- public static ArrayList<DefaultBytesMessage> readMessagesFromGetMessageResult(final GetMessageResult getMessageResult) {
- ArrayList<DefaultBytesMessage> messages = new ArrayList<>();
- try {
- List<ByteBuffer> messageBufferList = getMessageResult.getMessageBufferList();
- for (ByteBuffer bb : messageBufferList) {
- messages.add(readMessageFromByteBuffer(bb));
- }
- } finally {
- getMessageResult.release();
- }
- // 获取字节数组
- return messages;
- }
- /**
- * Description 从输入的 ByteBuffer 中反序列化消息对象
- *
- * @return 0 Come the end of the file // >0 Normal messages // -1 Message checksum failure
- */
- public static DefaultBytesMessage readMessageFromByteBuffer(java.nio.ByteBuffer byteBuffer) {
- // 1 TOTAL SIZE
- int totalSize = byteBuffer.getInt();
- // 2 MAGIC CODE
- int magicCode = byteBuffer.getInt();
- switch (magicCode) {
- case MESSAGE_MAGIC_CODE:
- break;
- case BLANK_MAGIC_CODE:
- return null;
- default:
- log.warning("found a illegal magic code 0x" + Integer.toHexString(magicCode));
- return null;
- }
- byte[] bytesContent = new byte[totalSize];
- ...
- }
【本文是51CTO专栏作者“张梓雄 ”的原创文章,如需转载请通过51CTO与作者联系】