【51CTO.com原创稿件】2013 年,苏宁大数据团队以 Hadoop 生态系统为核心构建了整套大数据平台,为整个苏宁集团所有业务团队提供大数据的存储以及计算能力。
在苏宁中台供应链计算等应用场景下,我们基于 Apache Spark 来构建整套零售核心数据计算与分析平台,解决海量数据离线和在线计算时效和性能问题。
本文主要介绍 Apache Spark 如何实现苏宁中台商品价格信息的 TB 级别复杂业务数据处理运算,以及其中碰到的问题和解决方案。
苏宁大数据平台和整体框架结构
苏宁大数据平台的整体架构以开源的基础平台为主,辅助以自研的组件。
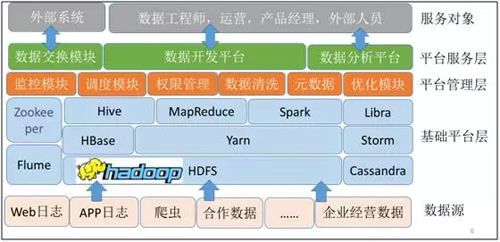
图 1:苏宁大数据平台架构
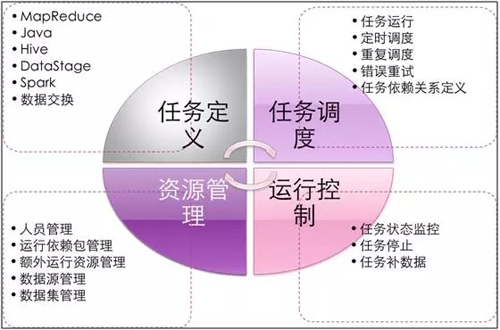
图 2:大数据开发平台
综合商品价格运算系统中 Spark 的应用
在整个综合商品价格运算系统中,我们对供应链等数据进行了整合,生成了目前全部可售商品的价格库存等数据。
该数据的整合涉及到多个外围系统的数据整合和业务的执行。在该项目中,我们运用 Spark 技术来解决海量数据抽取、海量数据运算的问题。
整体流程可以描述为:
- 使用 Spark 从上游系统的 DB2、MySQL 生产环境备库中抽取全量数据。
- 使用 Spark 进行数据的关联和聚合,将各个源头数据加工转换成计算所需要的数据维度。
- 运用 Spark 的 Map 进行全量数据的运算转换。
- 存储结果到 HDFS 中,并且在 Hive 表中建立外部表映射到 HDFS 目录。
下面讲述 Apache Spark 的四个技术应用实践。
使用 DataFrame 实现异构数据库海量数据抽取
数据处理的规划:由于上游系统的数据,尚未同步到大数据存储系统中(HDFS,Hive,HBase),项目需要独立进行数据的 ETL 工作。
这些上游系统的数据存在以下特点:
- 数据量较大:两个主要数据源头数据量在 10 亿级。
- 存储介质不同:DB2,MySQL,Hive。
- 存储的分布不同:业务库有 10 个库 1000 张表,也有 5 个库 100 张表,和不分表等存储结构,分库的规则有取表名后缀的模,有取表名后缀的区间等。
- 在系统需求上,又需要将整个运算任务压缩到 1 小时之内。我们最终采用的方案是使用 SparkSQL 的 JDBC 接口直接进行数据的抽取和计算,相当于将数据 ETL 和数据的业务处理放置在一个程序中。
- 相对于 Sqoop,这样的解决方案是轻量级的,1000 个 DataFrame 的 Load 要比 1000 个 Sqoop 任务的资源消耗要低很多,以及调度开销的消耗也少很多。
- 便于数据业务代码,业务针对动态表的切换,可以将读取当前表编号的模块直接嵌入到 Spark 的代码中进行。
对于 DataFrame 在加载数据前的数据库 Schema 性能问题,有了一个较好的优化方案,以下是优化前和优化后,DataFrame 在创建过程中的流程:
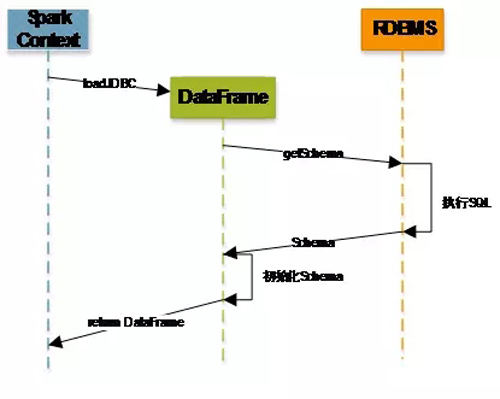
图 3 :优化前 DataFrame 创建流程
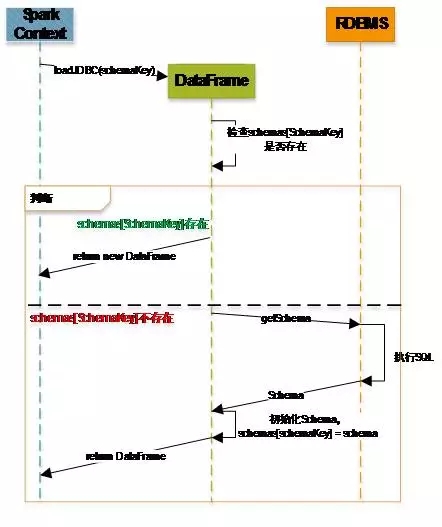
图 4 :优化后的 DataFrame 创建流程
在使用该方案后,任务 DataFrame 的 Load 数据时间从原先的接近 30 分钟缩短为 5 分钟以内。
使用 SparkSQL 结合 ZipPartition 实现多层次多维度数据关联和优化
电商和互联网的运营一般会涉及到数据维度的扩散,为了简化运营端的操作难度和提高数据提供方的性能,一般会使用维度扩散的方案,将上游运营系统的数据进行数据的扩散,放置到下游数据使用方<K,V>存储中。
在进行维度扩散时经常会有数据层次的问题,数据需要多层的关联和层次不同的数据需要关联的情况。例如,上游运营的数据为全国、地区、城市维度并且有优先级,下游数据服务方的维度统一为城市维度。
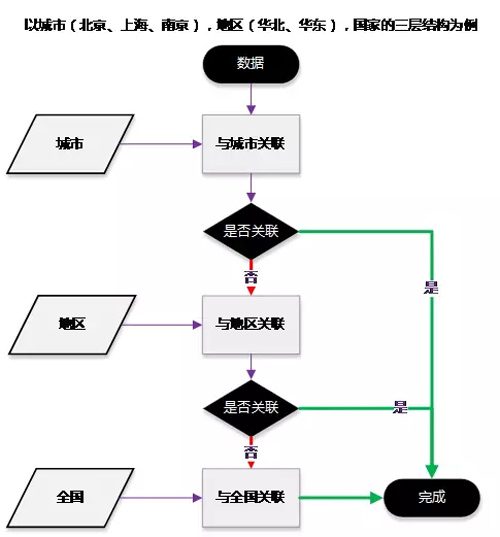
图 5:多层关联示意图
在应用系统中,一般的做法是使用点关联查询,从***优先级的维度进行关联,关联到则返回,关联不到则继续向下一个优先级进行关联,直到最终结果。
但是在 Spark 中,我们是需要运用类似于数据库关联的模式解决该问题。
使用***优先级进行左关联,然后过滤出未关联到的数据,再依次将未关联到的数据进行下面优先级的关联,直到生成结果。可以表示为:
- DataSet LeftJoin DimensionA => DataSetA
- DataSetA Filter(A.Field == NULL) => DataSetToJoinB
- DataSetA Filter(A.Field != NULL) => DataSetAFinal
- DataSetToJoinB LeftJoin DimensionB => DataSetB
- …
- DataSetFinal = DataSetAFinal UNION DataSetBFinal UNION DataSetCFinal
这里就出现一个问题:
- 同样的数据被多次使用,这里从技术上可以采用 Cache 的方法应对。
- 在使用 Cache 对数据缓存的方法上,假如***优先级的数据少,则实际上大量的数据都会需要 Cache 并且落到***一层。
针对可能缓存多次数据的问题,我们尝试了另外一种方法,全部进行左关联,并且带上优先级。最终,我们使用 Group By 的方法对优先级进行了处理,可以表示为:
- DataSet LeftJoin DimensionA with A => DataSetA
- DataSet LeftJoin DimensionB with B => DataSetB
- DataSet LeftJoin DimensionC with C => DataSetC
- DataSetA UNION DataSetB UINION DataSetC => DataSetToGroupBy
- DataSetFinal = (DataSetToGroupBy GroupBy Dimension).ApplyPriority()
这里方案就只需要进行一次的数据 Cache。
最终我们根据两种方案对实际测试的结果进行取舍,该部分的优化和一般的数据库优化一样,都需要考虑到实际的数据关联的情况和业务要求,获取***化的方案。已达到***的任务运行效益。
通过并行控制 DAG,优化执行时间
在进行复杂业务的处理过程中,我们发现有部分数据未进行分表分库,并且数据量相对较大(约 20 亿),这部分数据的载入效率直接影响了后面的整个效率。
例如,我们正常使用 128 核进行运算,但一旦运行到该步骤,则变成了单个核进行运行,时间长达 5 分钟。而 5 分钟对于系统运算有严格时间区间要求的业务需求是非常严峻的。
针对该问题,我们使用 Driver 端并行提交任务的方法进行解决。这是根据我们的任务模式所决定的,Driver 需要大量的时间建立数据的整个流程(4000 多张表的 DataFrame),并在最终存储结果 action 代码执行之前就进行数据的加载。
具体操作流程是:
- 将该部分数据标记为 Cache。
- 执行 countSync 直接进行数据加载。
- 在必须用到该步骤的流程进行 Get 命令阻塞 Driver 主线程,确保数据加载后进行后续的操作。
- 后续步骤直接使用已经缓存的数据进行运算。
该方案可以用下图表示:
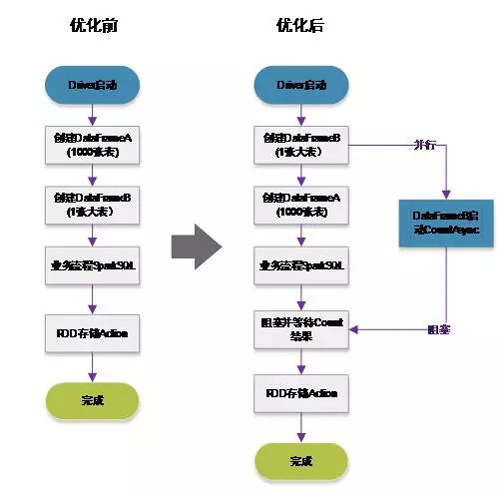
图 6:并行优化示意图
计算结果是通过并行的加载后,我们将整个的流程缩短了 5 分钟。我们也在其他对于运行时间有严格要求的项目中使用该方法对于业务流程中需要独立计算,资源占用小,但是耗时较长的模块进行了优化,都一定程度上缩短了所需要的时间。
Spark 的 ClassLoader 所带来的问题和解决方案
该问题出现的原因是公司对运维和研发的数据隔离有明确的要求,代码和研发的配置中不允许出现生产环境的数据库配置。
原先的配置都是由运维在 Websphere,Wildfly 等中间件中,通过 JNDI 的方法配置给实际的应用程序。
但是项目中又需要使用 JDBC 去直接连接生产环境的数据库,这样就带来了数据库连接的问题。
我们采用自定义的 JDBC 封装原先的 JDBC,让外层的 JDBC 以 Token 的方式获取实际的数据库连接,并且由实际的 JDBC 进行操作。
在这种需求下,我们在处理过程中考虑到目前分布式协调组件的压力,将数据库的 Token 封装到 Jar 包,使用 ClassLoader 去读取 Token 数据。
正常情况下,我们在 Spark 端使用到的 Classloader 顺序来加载 Token 文件:
ExtClassLoader-> AppClassLoader -> MutableURLClassLoader.
然而,在集群运行时,我们在 Driver 主线程中的 ClassLoader 是 AppClassLoader,而它无法读取到 http 的 jar 包里面的 token 文件。
我们进行了简单的方案,将当期线程中的 ClassLoader 替换成为当期业务代码类的 ClassLoader。
Spark 应用的实践总结
我们在价格运算系统中使用了 SOA 模式中的 Aggregate Reporting 模式,将多个产品线的数据进行了整合,提供了一个业务聚合的数据集市。
在模块设计上,我们将数据的抽取和数据的运算集成到一起,这样在带来效率和便利的同时也必然带来模块耦合。
从目前的实践中,可以得出几个结论:
- 使用 JDBC 抽取大量数据表直接进行计算是可行的,尤其针对分表分库和可以进行并行抽取的数据库。但是有几点需要特别关注:
①DataFrame 在大量创建时,对带来的 Driver 端时间消耗需要进行优化,减少数据流转的时间。
②数据源中一旦有任何一个出现失败,整个任务就可能需要重新运算,这个是将 ETL 和运算放到一个模块带来的问题。
③DataFrame 大量并行抽取时,对数据库的 IO 压力是比较大的,Spark 难以对这部分的并行度进行控制。
需要根据实际情况考虑使用合并抽取(Union多张表),或者进行任务拆分。任务拆分可以解决抽取时并行度和计算时并行度和资源要求不一样的问题。
- ZipPartition 是数据关联的最终解决方案,通过 SparkSQL 和 RDD 的 JOIN 时维度层次不一样,或者其他难以 JOIN 的问题都可以通过这个方法解决。
但由于 ZipPartition 是 RDD 底层的操作,开发人员几乎完全控制 Worker 的关联模型,它的性能调优显得尤其重要。
而对于有层次结构的关联,使用 JOIN – FILTER –UNION 和 JOIN – UNION –GROUPBY,则需要分析实际数据的情况,再进行取舍。
- 在 Driver 端进行并行可以解决部分计算时间的问题,但需要满足几个条件:
①可以并行的时间点,必须是在集群相对空闲的时候,例如:Driver 端在进行初始化 RDD 的时候,在编排大型 DAG 的时候。
②可并行的数据必须在最终使用之前确认加载到 Cache。
③不应该对过于大的数据集进行并行加载操作。
- Spark 在 ClassLoader 层面进行了变动,将配置文件封装在 jar 包中有可能无法读取,正确的做法是将配置信息使用同一配置管理,例如基于 Zookeeper 配置。
苏宁未来的开发方向
苏宁在 IT 的系统架构方面未来会根据各种不同的应用需求使用异构化的数据存储,在数据架构层面逐渐向 DataLake+Big DataWarehousing 的模式发展。
数据服务必须具备以下能力:
- 数据治理能力:各个系统通过统一的规范进行数据的业务分类,数据输出。其他系统和分析人员可以使用统一的数据规范运用数据。
数据需要能够支持快速的输出,并且保持与业务系统实时同步。
- 数据分析能力:在统一数据治理的基础上进行数据的分析,挖掘数据对于运营系统和销售系统的价值。
我们将使用 Apache Spark 平台结合 Hadoop 生态圈的其他工具进行开发,逐步形成以 Spark,Storm 等为引擎的一体化数据处理分析平台,提升整个苏宁的数据运用能力。
话题讨论
当前大数据架构最火热的莫过于分布式计算架构 Hadoop 和流数据处理框架 Spark/Storm 这两类。
网上逐渐有一种声音说 Hadoop 的日子已经快到头了,真是这样吗?未来大数据架构究竟该走向何方呢? 欢迎大家直接在底部参与评论!
王卓伟
苏宁云商 IT 总部高级技术经理
拥有多年 IT 平台研发和管理工作经验,先后在联创,焦点,苏宁等大型互联网和 IT 企业工作,现主要承担苏宁易购价格数据分析和实时处理优化提升,负责价格搜索响应提升系统,在大数据和数据分析上有多年的实战经验,专注 Java,大数据,SOA 等技术领域。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】