在分布式领域中存在着三种类型的消息投递语义,分别是:最多一次(at-most-once)、至少一次(at-least-once)和恰好一次(exactly-once)。本文作者介绍了一个利用Kafka和RocksDB来构建的“恰好一次”消息去重系统的实现原理。
对任何一个数据流水线的唯一要求就是不能丢失数据。数据通常可以被延迟或重新排序,但不能丢失。
为了满足这一要求,大多数的分布式系统都能够保证“至少一次”的投递消息技术。实现“至少一次”的投递技术通常就是:“重试、重试、再重试”。在你收到消费者的确认消息之前,你永远不要认为消息已经投递过去。
但“至少一次”的投递并不是用户想要的。用户希望消息被投递一次,并且仅有一次。
然而,实现“恰好一次”的投递需要***的设计。每种投递失败的情况都必须认真考虑,并设计到架构中去,因此它不能在事后“挂到”现有的实现上去。即使这样,“只有一次”的投递消息几乎是不可能的。
在过去的三个月里,我们构建了一个全新的去重系统,以便在面对各种故障时能让系统尽可能实现“恰好一次”的投递。
新系统能够跟踪旧系统100倍的消息数量,并且可靠性也得到了提高,而付出的代价却只有一点点。下面我们就开始介绍这个新系统。
问题所在
Segment内部的大部分系统都是通过重试、消息重新投递、锁定和两阶段提交来优雅地处理故障。但是,有一个特例,那就是将数据直接发送到公共API的客户端程序。
客户端(特别是移动客户端)经常会发生网络问题,有时候发送了数据,却没有收到API的响应。
想象一下,某天你乘坐公共汽车,在iPhone上使用HotelTonight软件预订房间。该应用程序将数据上传到了Segment的服务器上,但汽车突然进入了隧道并失去了网络连接。你发送的某些数据在服务器上已经被处理,但客户端却无法收到服务器的响应消息。
在这种情况下,即使服务器在技术上已经收到了这些确切的消息,但客户端也会进行重试并将相同的消息重新发送给Segment的API。
从我们服务器的统计数据来看,在四个星期的窗口时间内,大约有0.6%的消息似乎是我们已经收到过的重复消息。
这个错误率听起来可能并不是很高。但是,对于一个能创造数十亿美元效益的电子商务应用程序来说,0.6%的出入可能意味着盈利和数百万美元损失之间的差别。
对消息进行去重
现在,我们认识到问题的症结了,我们必须删除发送到API的重复消息。但是,该怎么做呢?
最简单的思路就是使用针对任何类型的去重系统的高级API。在Python中,我们可以将其表示为:
- def dedupe(stream):
- for message in stream:
- if has_seen(message.id):
- discard(message)
- else:
- publish_and_commit(message)
对于数据流中的每个消息,首先要把他的id(假设是唯一的)作为主键,检查是否曾经见过这个特定的消息。如果以前见过这个消息,则丢弃它。如果没有,则是新的,我们应重新发布这个消息并以原子的方式提交消息。
为了避免存储所有的消息,我们会设置“去重窗口”这个参数,这个参数定义了在消息过期之前key存储的时长。只要消息落在窗口时间之外,我们就认为它已过期失效。我们要保证在窗口时间内某个给定ID的消息只发送一次。
这个行为很容易描述,但有两个方面需要特别注意:读/写性能和正确性。
我们希望系统能够低延迟和低成本的对通过流水线的数十亿个事件进行去重。更重要的是,我们要确保所有的事件都能够被持久化,以便可以从崩溃中恢复出来,并且不会输出重复的消息。
架构
为了实现这一点,我们创建了一个“两阶段”架构,它读入Kafka的数据,并且在四个星期的时间窗口内对接收到的所有事件进行去重。
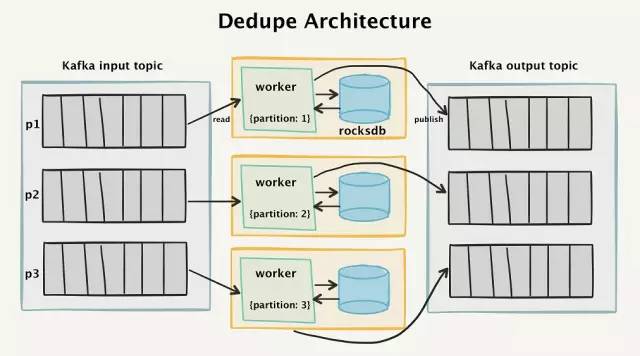
去重系统的高级架构图
Kafka的拓扑结构
要了解其工作原理,首先看一下Kafka的流拓扑结构。所有传入消息的API调用都将作为单独的消息进行分离,并读入到Kafka输入主题(input topic)中。
首先,每个传入的消息都有一个由客户端生成的具有唯一性的messageId标记。在大多数情况下,这是一个UUIDv4(我们考虑切换到ksuids)。 如果客户端不提供messageId,我们会在API层自动分配一个。
我们不使用矢量时钟或序列号,因为我们希望能降低客户端的复杂性。使用UUID可以让任何人轻松地将数据发送到我们的API上来,因为几乎所有的主要语言都支持它。
- {
- "messageId": "ajs-65707fcf61352427e8f1666f0e7f6090",
- "anonymousId": "e7bd0e18-57e9-4ef4-928a-4ccc0b189d18",
- "timestamp": "2017-06-26T14:38:23.264Z",
- "type": "page"
- }
为了能够将消息持久化,并能够重新发送,一个个的消息被保存到Kafka中。消息以messageId进行分区,这样就可以保证具有相同messageId的消息能够始终由同一个消费者处理。
这对于数据处理来说是一件很重要的事情。我们可以通过路由到正确的分区来查找键值,而不是在整个中央数据库的数百亿条消息中查找,这种方法极大地缩小了查找范围。
去重“worker”(worker:工人。译者注,这里表示的是某个进程。为防止引起歧义,下文将直接使用worker)是一个Go程序,它的功能是从Kafka输入分区中读入数据,检查消息是否有重复,如果是新的消息,则发送到Kafka输出主题中。
根据我们的经验,worker和Kafka拓扑结构都非常容易掌握。我们无需使用一组遇到故障时需要切换到副本的庞大的Memcached实例。相反,我们只需使用零协同的嵌入式RocksDB数据库,并以非常低的成本来获得持久化存储。
RocksDB的worker进程
每一个worker都会在本地EBS硬盘上存放了一个RocksDB数据库。RocksDB是由Facebook开发的嵌入式键值存储系统,它的性能非常高。
每当从输入主题中过来的消息被消费时,消费者通过查询RocksDB来确定我们之前是否见过该事件的messageId。
如果RocksDB中不存在该消息,我们就将其添加到RocksDB中,然后将消息发布到Kafka输出主题。
如果消息已存在于RocksDB,则worker不会将其发布到输出主题,而是更新输入分区的偏移,确认已处理过该消息。
性能
为了让我们的数据库获得高性能,我们必须对过来的每个事件满足三种查询模式:
- 检测随机key的存在性,这可能不存在于我们的数据库中,但会在key空间中的任何地方找到。
- 高速写入新的key
- 老化那些超出了“去重窗口”的旧的key
实际上,我们必须不断地检索整个数据库,追加新的key,老化旧的key。在理想情况下,这些发生在同一数据模型中。
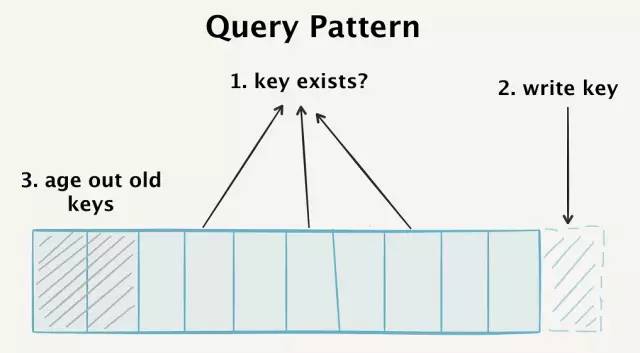
我们的数据库必须满足三种独立的查询模式
一般来说,这些性能大部分取决于我们数据库的性能,所以应该了解一下RocksDB的内部机制来提高它的性能。
RocksDB是一个日志结构合并树(log-structured-merge-tree, 简称LSM)数据库,这意味着它会不断地将新的key附加到磁盘上的预写日志(write-ahead-log)中,并把排序过的key存放在内存中作为memtable的一部分。
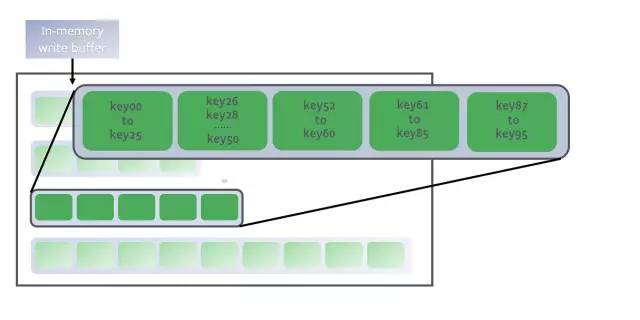
key存放在内存中作为memtable的一部分
写入key是一个非常快速的过程。新的消息以追加的方式直接保存到磁盘上,并且数据条目在内存中进行排序,以提供快速的搜索和批量写入。
每当写入到memtable的条目达到一定数量时,这些条目就会被作为SSTable(排序的字符串表)持久化到磁盘上。由于字符串已经在内存中排过序了,所以可以将它们直接写入磁盘。
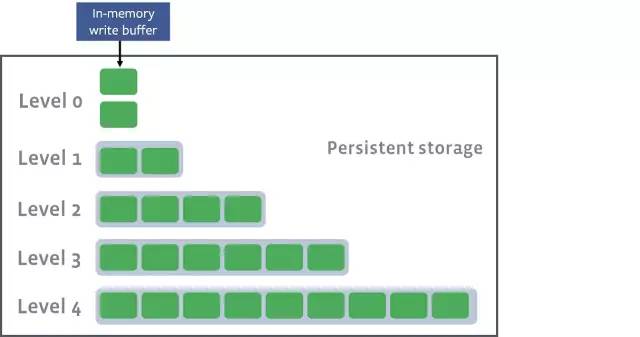
当前的memtable零级写入磁盘
以下是在我们的生产日志中写入的示例:
- [JOB 40] Syncing log #655020
- [default] [JOB 40] Flushing memtable with next log file: 655022
- [default] [JOB 40] Level-0 flush table #655023: started
- [default] [JOB 40] Level-0 flush table #655023: 15153564 bytes OK
- [JOB 40] Try to delete WAL files size 12238598, prev total WAL file size 24346413, number of live WAL files 3.
每个SSTable是不可变的,一旦创建,永远不会改变。这是什么写入新的键这么快的原因。无需更新文件,无需写入扩展。相反,在带外压缩阶段,同一级别的多个SSTable可以合并成一个新的文件。
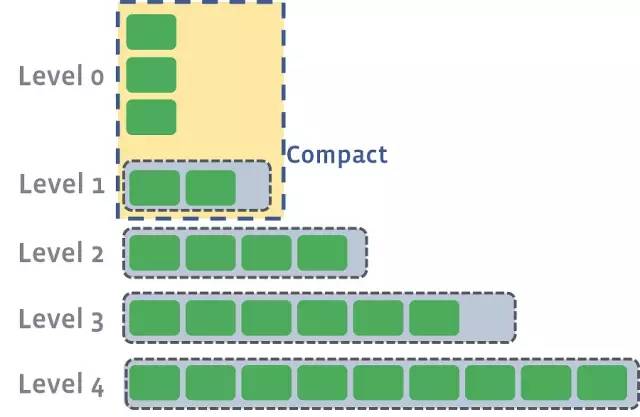
当在同一级别的SSTables压缩时,它们的key会合并在一起,然后将新的文件升级到下一个更高的级别。
看一下我们生产的日志,可以看到这些压缩作业的示例。在这种情况下,作业41正在压缩4个0级文件,并将它们合并为单个较大的1级文件。
- /data/dedupe.db$ head -1000 LOG | grep "JOB 41"
- [JOB 41] Compacting 4@0 + 4@1 files to L1, score 1.00
- [default] [JOB 41] Generated table #655024: 1550991 keys, 69310820 bytes
- [default] [JOB 41] Generated table #655025: 1556181 keys, 69315779 bytes
- [default] [JOB 41] Generated table #655026: 797409 keys, 35651472 bytes
- [default] [JOB 41] Generated table #655027: 1612608 keys, 69391908 bytes
- [default] [JOB 41] Generated table #655028: 462217 keys, 19957191 bytes
- [default] [JOB 41] Compacted 4@0 + 4@1 files to L1 => 263627170 bytes
压缩完成后,新合并的SSTables将成为最终的数据库记录集,旧的SSTables将被取消链接。
如果我们登录到生产实例,我们可以看到正在更新的预写日志以及正在写入、读取和合并的单个SSTable。
日志和最近占用I/O的SSTable
下面生产的SSTable统计数据中,可以看到一共有四个“级别”的文件,并且一个级别比一个级别的文件大。
- ** Compaction Stats [default] **
- Level Files Size(MB} Score Read(GB} Rn(GB} Rnp1(GB} Write(GB} Wnew(GB} Moved(GB} W-Amp Rd(MB/s} Wr(MB/s} Comp(sec} Comp(cnt} Avg(sec} KeyIn KeyDrop
- ----------------------------------------------------------------------------------------------------------------------------------------------------------
- L0 1/0 14.46 0.2 0.0 0.0 0.0 0.1 0.1 0.0 0.0 0.0 15.6 7 8 0.925 0 0
- L1 4/0 194.95 0.8 0.5 0.1 0.4 0.5 0.1 0.0 4.7 20.9 20.8 26 2 12.764 12M 40
- L2 48/0 2551.71 1.0 1.4 0.1 1.3 1.4 0.1 0.0 10.7 19.4 19.4 73 2 36.524 34M 14
- L3 351/0 21735.77 0.8 2.0 0.1 1.9 1.9 -0.0 0.0 14.3 18.1 16.9 112 2 56.138 52M 3378K
- Sum 404/0 24496.89 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2 18.2 18.1 218 14 15.589 98M 3378K
- Int 0/0 0.00 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2 18.2 18.1 218 14 15.589 98M 3378K
RocksDB保存了索引和存储在SSTable的特定SSTables的布隆过滤器,并将这些加载到内存中。通过查询这些过滤器和索引可以找到特定的key,然后将完整的SSTable作为LRU基础的一部分加载到内存中。
在绝大多数情况下,我们就可以看到新的消息了,这使得我们的去重系统成为教科书中的布隆过滤器案例。
布隆过滤器会告诉我们某个键“可能在集合中”,或者“绝对在集合中”。要做到这一点,布隆过滤器保存了已经见过的任何元素的多种哈希函数的设置位。如果设置了散列函数的所有位,则过滤器将返回消息“可能在集合中”。

我们的集合包含{x,y,z},在布隆过滤器中查询w,则布隆过滤器会返回“不在集合中”,因为其中有一位没有设置。
如果返回“可能在集合中”,则RocksDB可以从SSTables中查询到原始数据,以确定该项是否在该集合中实际存在。但在大多数情况下,我们不需查询任何SSTables,因为过滤器将返回“绝对不在集合”的响应。
在我们查询RocksDB时,我们会为所有要查询的相关的messageId发出一个MultiGet。基于性能考虑,我们会批量地发布出去,以避免太多的并发锁定操作。它还允许我们批量处理来自Kafka的数据,这是为了实现顺序写入,而不是随机写入。
以上回答了为什么读/写工作负载性能这么好的问题,但仍然存在如何老化数据这个问题。
删除:按大小来限制,而不是按时间来限制
在我们的去重过程中,我们必须要确定是否要将我们的系统限制在严格的“去重窗口”内,或者是通过磁盘上的总数据库大小来限制。
为了避免系统突然崩溃导致去重系统接收到所有客户端的消息,我们决定按照大小来限制接收到消息数量,而不是按照设定的时间窗口来限制。这允许我们为每个RocksDB实例设置***的大小,以能够处理突然的负载增加。但是其副作用是可能会将去重窗口降低到24小时以下。
我们会定期在RocksDB中老化旧的key,使其不会增长到***大小。为此,我们根据序列号保留key的第二个索引,以便我们可以先删除最早接收到的key。
我们使用每个插入的key的序列号来删除对象,而不是使用RocksDB TTL(这需要在打开数据库的时候设置一个固定的TTL值)来删除。
因为序列号是第二索引,所以我们可以快速地查询,并将其标记为已删除。下面是根据序列号进行删除的示例代码:
- func (d *DB) delete(n int) error {
- // open a connection to RocksDB
- ro := rocksdb.NewDefaultReadOptions()
- defer ro.Destroy()
- // find our offset to seek through for writing deletes
- hint, err := d.GetBytes(ro, []byte("seek_hint"))
- if err != nil {
- return err
- }
- it := d.NewIteratorCF(ro, d.seq)
- defer it.Close()
- // seek to the first key, this is a small
- // optimization to ensure we don't use `.SeekToFirst()`
- // since it has to skip through a lot of tombstones.
- if len(hint) > 0 {
- it.Seek(hint)
- } else {
- it.SeekToFirst()
- }
- seqs := make([][]byte, 0, n)
- keys := make([][]byte, 0, n)
- // look through our sequence numbers, counting up
- // append any data keys that we find to our set to be
- // deleted
- for it.Valid() && len(seqs) < n {
- k, v := it.Key(), it.Value()
- key := make([]byte, len(k.Data()))
- val := make([]byte, len(v.Data()))
- copy(key, k.Data())
- copy(val, v.Data())
- seqs = append(seqs, key)
- keys = append(keys, val)
- it.Next()
- k.Free()
- v.Free()
- }
- wb := rocksdb.NewWriteBatch()
- wo := rocksdb.NewDefaultWriteOptions()
- defer wb.Destroy()
- defer wo.Destroy()
- // preserve next sequence to be deleted.
- // this is an optimization so we can use `.Seek()`
- // instead of letting `.SeekToFirst()` skip through lots of tombstones.
- if len(seqs) > 0 {
- hint, err := strconv.ParseUint(string(seqs[len(seqs)-1]), 10, 64)
- if err != nil {
- return err
- }
- buf := []byte(strconv.FormatUint(hint+1, 10))
- wb.Put([]byte("seek_hint"), buf)
- }
- // we not only purge the keys, but the sequence numbers as well
- for i := range seqs {
- wb.DeleteCF(d.seq, seqs[i])
- wb.Delete(keys[i])
- }
- // finally, we persist the deletions to our database
- err = d.Write(wo, wb)
- if err != nil {
- return err
- }
- return it.Err()
- }
为了保证写入速度,RocksDB不会立即返回并删除一个键(记住,这些SSTable是不可变的!)。相反,RocksDB将添加一个“墓碑”,等到压缩时再进行删除。因此,我们可以通过顺序写入来快速地老化,避免因为删除旧项而破坏内存数据。
确保正确性
我们已经讨论了如何确保数十亿条消息投递的速度、规模和低成本的搜索。***一个部分将讲述各种故障情况下我们如何确保数据的正确性。
EBS快照和附件
为了确保RocksDB实例不会因为错误的代码推送或潜在的EBS停机而损坏,我们会定期保存每个硬盘驱动器的快照。虽然EBS已经在底层进行了复制,但是这一步可以防止数据库受到某些底层机制的破坏。
如果我们想要启用一个新实例,则可以先暂停消费者,将相关联的EBS驱动器分开,然后重新附加到新的实例上去。只要我们保证分区ID相同,重新分配磁盘是一个轻松的过程,而且也能保证数据的正确性。
如果worker发生崩溃,我们依靠RocksDB内置的预写日志来确保不会丢失消息。消息不会从输入主题提交,除非RocksDB已经将消息持久化在日志中。
读取输出主题
你可能会注意到,本文直到这里都没有提到“原子”步骤,以使我们能够确保只投递一次消息。我们的worker有可能在任何时候崩溃,不如:写入RocksDB时、发布到输出主题时,或确认输入消息时。
我们需要一个原子的“提交”点,并覆盖所有这些独立系统的事务。对于输入的数据,需要某个“事实来源”:输出主题。
如果去重worker因为某些原因发生崩溃,或者遇到Kafka的某个错误,则系统在重新启动时,会首先查阅这个“事实来源”,输出主题,来判断事件是否已经发布出去。
如果在输出主题中找到消息,而不是RocksDB(反之亦然),则去重worker将进行必要的修复工作以保持数据库和RocksDB之间的同步。实际上,我们使用输出主题作为我们的预写入日志和最终的事实来源,让RocksDB进行检查和校验。
在生产环境中
我们的去重系统已经在生产运行了3个月,对其运行的结果我们感到非常满意。我们有以下这些数据:
- 在RocksDB中,有1.5TB的key存储在磁盘上
- 在老化旧的key之前,有一个四个星期的去重窗口
- RocksDB实例中存储了大约600亿个key
- 通过去重系统的消息达到2000亿条
该系统快速、高效、容错性强,也非常容易理解。
特别是我们的v2版本系统相比旧的去重系统有很多优点。
以前我们将所有的key存储在Memcached中,并使用Memcached的原子CAS(check-and-set)操作来设置key。 Memcached起到了提交点和“原子”地发布key的作用。
虽然这个功能很好,但它需要有大量的内存来支撑所有的key。此外,我们必须能够接受偶尔的Memcached故障,或者将用于高速内存故障切换的支出加倍。
Kafka/RocksDB的组合相比旧系统有如下几个优势:
- 数据存储在磁盘上:在内存中保存所有的key或完整的索引,其代价是非常昂贵的。通过将更多的数据转移到磁盘,并利用多种不同级别的文件和索引,能够大幅削减成本。对于故障切换,我们能够使用冷备(EBS),而不用运行其他的热备实例。
- 分区:为了缩小key的搜索范围,避免在内存中加载太多的索引,我们需要保证某个消息能够路由到正确的worker。在Kafka中对上游进行分区可以对这些消息进行路由,从而更有效地缓存和查询。
- 显式地进行老化处理:在使用Memcached的时候,我们在每个key上设置一个TTL来标记是否超时,然后依靠Memcached进程来对超时的key进行处理。这使得我们在面对大量数据时,可能会耗尽内存,并且在丢弃大量超时消息时,Memcached的CPU使用率会飙升。而通过让客户端来处理key的删除,使得我们可以通过缩短去重窗口来优雅地处理。
- 将Kafka作为事实来源:为了真正地避免对多个提交点进行消息去重,我们必须使用所有下游消费者都常见的事实来源。使用Kafka作为“事实来源”是最合适的。在大多数失败的情况下(除了Kafka失败之外),消息要么会被写入Kafka,要么不会。使用Kafka可以确保按顺序投递消息,并在多台计算机之间进行磁盘复制,而不需要在内存中保留大量的数据。
- 批量读写:通过Kafka和RocksDB的批量I/O调用,我们可以通过利用顺序读写来获得更好的性能。与之前在Memcached中使用的随机访问不同,我们能够依靠磁盘的性能来达到更高的吞吐量,并只在内存中保留索引。
总的来说,我们对自己构建的去重系统非常满意。使用Kafka和RocksDB作为流媒体应用的原语开始变得越来越普遍。我们很高兴能继续在这些原语之上构建新的分布式应用程序。