耳闻目睹了机器学习的诸般神奇,有没有冲动打算自己尝试一下?本文我们通过一个贷款风险评估的案例,用最通俗的语言向你介绍机器学习的基础招式,一步步帮助你用Python完成自己的第一个机器学习项目。试过之后你会发现,机器学习真的不难。
任务
祝贺你,成功进入了一家金融公司实习。
第一天上班,你还处在兴奋中。这时主管把你叫过去,给你看了一个文件。文件内容是这个样子的:
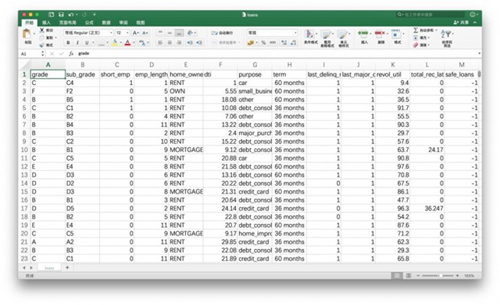
主管说这是公司宝贵的数据资产。嘱咐你认真阅读,并且从数字中找出规律,以便做出明智的贷款决策。
每一行数据,都代表了之前的一次贷款信息。你琢磨了很久,终于弄明白了每一列究竟代表什么意思:
- grade:贷款级别
- sub_grade: 贷款细分级别
- short_emp:一年以内短期雇佣
- emp_length_num:受雇年限
- home_ownership:居住状态(自有,按揭,租住)
- dti:贷款占收入比例
- purpose:贷款用途
- term:贷款周期
- last_delinq_none:贷款申请人是否有不良记录
- last_major_derog_none:贷款申请人是否有还款逾期90天以上记录
- revol_util:透支额度占信用比例
- total_rec_late_fee:逾期罚款总额
- safe_loans:贷款是否安全
最后一列,记录了这笔贷款是否按期收回。拿着以前的这些宝贵经验教训,主管希望你能够总结出贷款是否安全的规律。在面对新的贷款申请时,从容和正确应对。
主管让你找的这种规律,可以用决策树来表达。
决策
我们来说说什么是决策树。决策树长得就像这个样子:
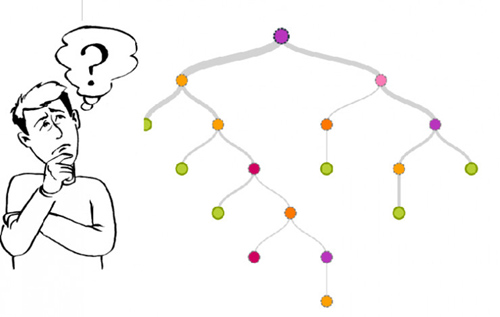
做决策的时候,你需要从最上面的节点出发。在每一个分支上,都有一个判断条件。满足条件,往左走;不满足,向右走。一旦走到了树的边缘,一项决策就完成了。
例如你走在街上,遇见邻居老张。你热情地打招呼:
“老张,吃了吗?”
好了,这里就是个分支。老张的回答,将决定你的决策走向,即后面你将说什么。
第一种情况。
老张:吃过了。
你:要不来我家再吃点儿?
第二种情况。
老张:还没吃。
你:那赶紧回家吃去吧。再见!
……
具体到贷款这个实例,你需要依次分析申请人的各项指标,然后判定这个贷款申请是否安全,以做出是否贷款给他的决策。把这个流程写下来,就是一棵决策树。
作为一名金融界新兵,你原本也是抱着积极开放的心态,希望多尝试一下的。但是当你把数据表下拉到最后一行的时候,你发现记录居然有46509条!
你估算了一下自己的阅读速度、耐心和认知负荷能力,觉得这个任务属于Mission Impossible(不可能完成),于是开始默默地收拾东西,打算找主管道个别,辞职不干了。
且慢,你不必如此沮丧。因为科技的发展,已经把一项黑魔法放在了你的手边,随时供你取用。它的名字,叫做机器学习。
学习
什么叫机器学习?
从前,人是“操作”计算机的。一项任务如何完成,人心里是完全有数的。人把一条条指令下达给电脑,电脑负责傻呵呵地干完,收工。
后来人们发现,对有些任务,人根本就不知道该怎么办。
前些日子的新闻里,你知道Alpha Go和柯洁下围棋。柯洁不仅输了棋,还哭了。
可是制造Alpha Go的那帮人,当真知道怎样下棋,才能赢过柯洁吗?你就是让他们放弃体育家精神,攒鸡毛凑掸子一起上,跟柯洁下棋……你估计哭的是谁?
一帮连自己下棋,都下不赢柯洁的人,又是如何制作出电脑软件,战胜了人类围棋界的“最强大脑”呢?
答案正是机器学习。
你自己都不知道如何完成的任务,自然也不可能告诉机器“第一步这么干,第二步那么办”,或者“如果出现A情况,打开第一个锦囊;如果出现B情况,打开第二个锦囊”。
机器学习的关键,不在于人类的经验和智慧,而在于数据。
本文我们接触到的,是最为基础的监督式学习(supervised learning)。监督式学习利用的数据,是机器最喜欢的。这些数据的特点,是都被打了标记。
主管给你的这个贷款记录数据集,就是打了标记的。针对每个贷款案例,后面都有“是否安全”的标记。1代表了安全,-1代表了不安全。
机器看到一条数据,又看到了数据上的标记,于是有了一个假设。
然后你再让它看一条数据,它就会强化或者修改原先的假设。
这就是学习的过程:建立假设——收到反馈——修正假设。在这个过程中,机器通过迭代,不断刷新自己的认知。
这让我想起了经典相声段子“蛤蟆鼓”里面的对话片段。
甲:那我问问你,蛤蟆你看见过吧?
乙:谁没见过蛤蟆呀。
甲:你说为什么它那么小的动物,叫唤出来的声音会那么大呢?
乙:那是因为它嘴大肚儿大脖子粗,叫唤出来的声音必然大。万物都是一个理。
甲:我家的字纸篓子也是嘴大脖子粗,为什么它不叫唤哪?
乙:字纸篓是死物,那是竹子编的,不但不叫,连响都响不了。
甲:吹的笙也是竹子的,怎么响呢?
乙:虽然竹子编的,因为它有窟窿有眼儿,有眼儿的就响。
甲:我家筛米的筛子尽是窟窿眼儿,怎么吹不响?
这里相声演员乙,就一直试图建立可以推广的假设。可惜,甲总是用新的例证摧毁乙的三观。
在四处碰壁后,可怜的机器跌跌撞撞地成长。看了许许多多的数据后,电脑逐渐有了自己对一些事情判断的想法。我们把这种想法叫做模型。
之后,你就可以用模型去辅助自己做出明智的判断了。
下面我们开始动手实践。用Python做个决策树出来,辅助我们判断贷款风险。
准备
使用Python和相关软件包,你需要先安装Anaconda套装。
主管给你展示的这份贷款数据文件,请从这里下载:
文件的扩展名是csv,你可以用Excel打开,看看是否下载正确。
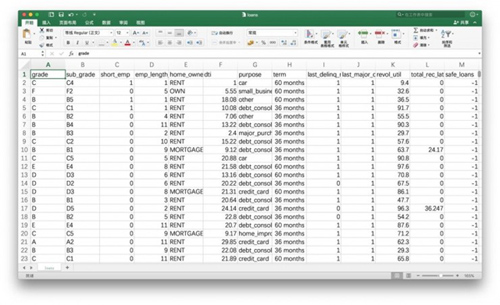
如果一切正常,请把它移动到咱们的工作目录demo里面。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
- pip install -U PIL
运行环境配置完毕。
在终端或者命令提示符下键入:
- jupyter notebook
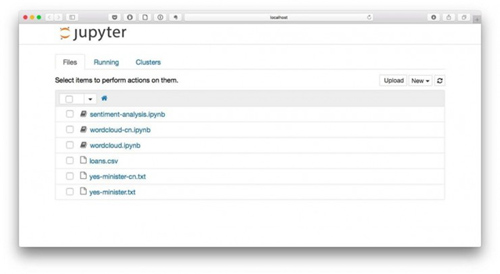
Jupyter Notebook已经正确运行。下面我们就可以正式编写代码了。
代码
首先,我们新建一个Python 2笔记本,起名叫做loans-tree。
为了让Python能够高效率处理表格数据,我们使用一个非常优秀的数据处理框架Pandas。
- import pandas as pd
然后我们把loans.csv里面的内容全部读取出来,存入到一个叫做df的变量里面。
- df = pd.read_csv('loans.csv')
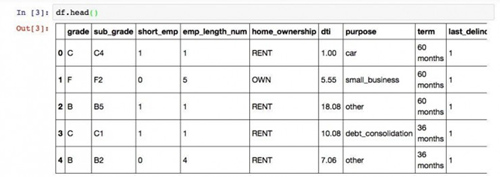
我们看看df这个数据框的前几行,以确认数据读取无误。
- df.head()
因为表格列数较多,屏幕上显示不完整,我们向右拖动表格,看表格最右边几列是否也正确读取。
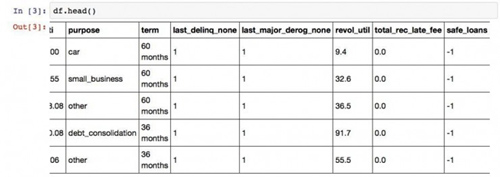
经验证,数据所有列都已读入。
统计一下总行数,看是不是所有行也都完整读取进来了。
df.shape
运行结果如下:
(46508, 13)
行列数量都正确,数据读取无误。
你应该还记得吧,每一条数据的最后一列 safe_loans 是个标记,告诉我们之前发放的这笔贷款是否安全。我们把这种标记叫做目标(target),把前面的所有列叫做“特征”(features)。这些术语你现在记不住没关系,因为以后会反复遇到。自然就会强化记忆。
下面我们就分别把特征和目标提取出来。依照机器学习领域的习惯,我们把特征叫做X,目标叫做y。
- X = df.drop('safe_loans', axis=1)
- y = df.safe_loans
我们看一下特征数据X的形状:
- X.shape
运行结果为:
- (46508, 12)
除了最后一列,其他行列都在。符合我们的预期。我们再看看“目标”列。
- y.shape
执行后显示如下结果:
- (46508,)
这里的逗号后面没有数字,指的是只有1列。
我们来看看X的前几列。
- X.head()
运行结果为:
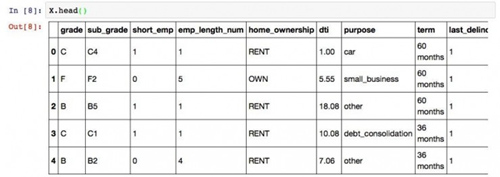
注意这里有一个问题。Python下做决策树的时候,每一个特征都应该是数值(整型或者实数)类型的。但是我们一眼就可以看出,grade, sub_grade, home_ownership等列的取值都是类别(categorical)型。所以,必须经过一步转换,把这些类别都映射成为某个数值,才能进行下面的步骤。
那我们就开始映射吧:
- from sklearn.preprocessing import LabelEncoder
- from collections import defaultdict
- d = defaultdict(LabelEncoder)
- X_trans = X.apply(lambda x: d[x.name].fit_transform(x))
- X_trans.head()
运行结果是这样的:
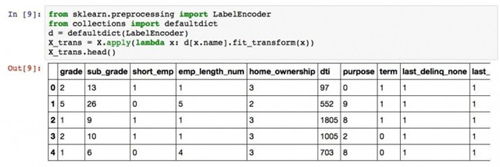
这里,我们使用了LabelEncoder函数,成功地把类别变成了数值。小测验:在grade列下面,B被映射成了什么数字?
请对比两个表格,思考10秒钟。
答案是1。你答对了吗?
下面我们需要做的事情,是把数据分成两部分,分别叫做训练集和测试集。
为什么这么折腾?
因为有道理。
想想看,如果期末考试之前,老师给你一套试题和答案,你把它背了下来。然后考试的时候,只是从那套试题里面抽取一部分考。你凭借超人的记忆力获得了100分。请问你学会了这门课的知识了吗?不知道如果给你新的题目,你会不会做呢?答案还是不知道。
所以考试题目需要和复习题目有区别。同样的道理,我们用数据生成了决策树,这棵决策树肯定对已见过的数据处理得很完美。可是它能否推广到新的数据上呢?这才是我们真正关心的。就如同在本例中,你的公司关心的,不是以前的贷款该不该贷。而是如何处理今后遇到的新贷款申请。
把数据随机拆分成训练集和测试集,在Python里只需要2条语句就够了。
- from sklearn.cross_validation import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(X_trans, y, random_state=1)
我们看看训练数据集的形状:
- X_train.shape
运行结果如下:
- (34881, 12)
测试集呢?
- X_test.shape
这是运行结果:
- (11627, 12)
至此,一切数据准备工作都已就绪。我们开始呼唤Python中的scikit-learn软件包。决策树的模型,已经集成在内。只需要3条语句,直接调用就可以,非常方便。
- from sklearn import tree
- clf = tree.DecisionTreeClassifier(max_depth=3)
- clf = clf.fit(X_train, y_train)
好了,你要的决策树已经生成完了。
就是这么简单。任性吧?
可是,我怎么知道生成的决策树是个什么样子呢?眼见才为实!
这个……好吧,咱们把决策树画出来吧。注意这一段语句内容较多。以后有机会咱们再详细介绍。此处你把它直接抄进去执行就可以了。
- with open("safe-loans.dot", 'w') as f:
- f = tree.export_graphviz(clf,
- out_file=f,
- max_depth = 3,
- impurity = True,
- feature_names = list(X_train),
- class_names = ['not safe', 'safe'],
- rounded = True,
- filled= True )
- from subprocess import check_call
- check_call(['dot','-Tpng','safe-loans.dot','-o','safe-loans.png'])
- from IPython.display import Image as PImage
- from PIL import Image, ImageDraw, ImageFont
- img = Image.open("safe-loans.png")
- draw = ImageDraw.Draw(img)
- img.save('output.png')
- PImage("output.png")
见证奇迹的时刻到了:
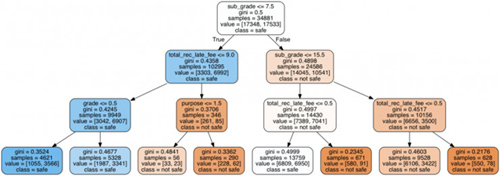
你是不是跟我第一次看到决策树的可视化结果一样,惊诧了?
我们其实只让Python生成了一棵简单的决策树(深度仅3层),但是Python已经尽职尽责地帮我们考虑到了各种变量对最终决策结果的影响。
测试
欣喜若狂的你,在悄悄背诵什么?你说想把这棵决策树的判断条件背下来,然后去做贷款风险判断?
省省吧。都什么时代了,还这么喜欢背诵?
以后的决策,电脑可以自动化帮你完成了。
你不信?
我们随便从测试集里面找一条数据出来。让电脑用决策树帮我们判断一下看看。
- test_rec = X_test.iloc[1,:]
- clf.predict([test_rec])
电脑告诉我们,它调查后风险结果是这样的:
- array([1])
之前提到过,1代表这笔贷款是安全的。实际情况如何呢?我们来验证一下。从测试集目标里面取出对应的标记:
- y_test.iloc[1]
结果是:
- 1
经验证,电脑通过决策树对这个新见到的贷款申请风险判断无误。
但是我们不能用孤证来说明问题。下面我们验证一下,根据训练得来的决策树模型,贷款风险类别判断准确率究竟有多高。
- from sklearn.metrics import accuracy_score
- accuracy_score(y_test, clf.predict(X_test))
虽然测试集有近万条数据,但是电脑立即就算完了:
- 0.61615205986066912
你可能会有些失望——忙活了半天,怎么才60%多的准确率?刚及格而已嘛。
不要灰心。因为在整个儿的机器学习过程中,你用的都是缺省值,根本就没有来得及做一个重要的工作——优化。
想想看,你买一台新手机,自己还得设置半天,不是吗?面对公司的贷款业务,你用的竟然只是没有优化的缺省模型。可即便这样,准确率也已经超过了及格线。
关于优化的问题,以后有机会咱们详细展开来聊。
你终于摆脱了实习第一天就灰溜溜逃走的厄运。我仿佛看到了一颗未来的华尔街新星正在冉冉升起。
苟富贵,无相忘哦。