译者注:本文介绍了作者和他的三位朋友参加了编程马拉松,开发出了一个根据Hacker News提交的文章进行分类的分类器,紧接着作者分享了比赛过程中的一些经验。以下为译文。
本周末,三位朋友(Chris Riederer,Nathan Gould和我的孪生兄弟Dan)和我参加了2017 TechCrunch Disrupt Hackathon。 我们以前都会去参加几个这样的编程马拉松,也喜欢挑战在短时间内开发一个可用的应用程序,同时学习一些新技术。
我们四个人中有三个是数据科学家,因此知道应该寻找一个数据驱动的项目,因为最好的编程马拉松项目往往是可用的应用程序(而不是分析或lib库),我们认为应该开发一个以机器学习为驱动的产品,想到了程序员社区Hacker News的分类器,它会根据文本自动分配每个提交的主题。
该项目需要下载数据,培训机器进行学习,并在24小时内将其变成可用的网站。 在这里我分享了我们在开发过程中学到的一些经验教训。
(请注意,我关注的是数据方面,因为这是我负责的模块,但是Nathan和Dan在开发和设计站点方面做了大量工作,同时为了使站点与Hacker News保持同步,他们也付出了很多心血。)
检索Hacker News的帖子和文章
Hacker News收集了用户提交和上传的文章,通常是程序员社区感兴趣的内容(不只是关于编程的文章)。我们的任务是检索每篇文章的文本,并将其分类为哪一种主题。
很快我们就知道了,我们需要大量的训练数据——也许是成千上万篇文章——为了能够成功地识别新文章的主题。要做到这一点,我们需要去Hacker News抓取每一篇提交的文章和对应的链接,然后查询每一篇文章来检索它的文本内容。
这里犯了一个错误,就是依赖Hacker News API从而一次只下载一个提交的文章,这样的话,想获得25,000个链接得需要好几个小时,这是一个缓慢的过程。在黑客马拉松结束后,我们了解到在Google BigQuery上有一个 Hacker News的数据集——在大约20分钟的配置之后,我就可以下载100万个链接。在比赛的压力下,我们很难做到一直去寻找类似于这种简单的解决方案,相反,为了最终实现可能会采用一些效率很低的解决方案(但这也是乐趣的一部分)。
一旦我们有了文章的链接,就需要每篇文章的文本内容。这是一种挑战,因为这些文章来自于不同的网站,格式也各不一样,但是设计python-goose正是为了这个目的。我们把其中的三台电脑专门用来抓取文章,这样每小时可以收集几千篇。你可以在这个GitHub库中找到我们的抓取代码和一些结果。
通常在这样的项目中,我们会让抓取任务在夜间运行,但对我们来说,这并不是一个可取的选择!当数据开始下载时,我们分成了两组:Nathan和Dan负责建立网站,而Chris和我负责开发收集数据的机器学习算法。
开发一个受监督的培训集
要训练一个受监督的分类器,你需要一个标签集:我们应该能够知道文章的正确分类是什么。我们没有足够的时间手工给例子贴上标签。那怎么得到一系列已经正确标记好的例子呢?
好吧,如果你浏览过几页Hacker News,你会发现有些文章通过标题几乎就已经明确地告诉你主题是什么了,或者有些是通过简单的模式匹配也可以知道。看看首页,比如Why Amazon is eating the world就是关于亚马逊的,Why do many math books have so much detail and so little enlightenment?是关于数学的,Don’t tell people to turn off Windows Update是关于微软/Windows的。因此,我们决定根据文章标题通过正则表达式创建一个训练集。
这个过程进行了一些试验,包括一些在文章标题中对常见词和集群的探索性分析。我最喜欢的图形之一就是通过文字的形式创建的一个关于网络的图形(请参阅我们的图书Text Mining with R的这一章节),这是一个更好地理解数据的好机会。
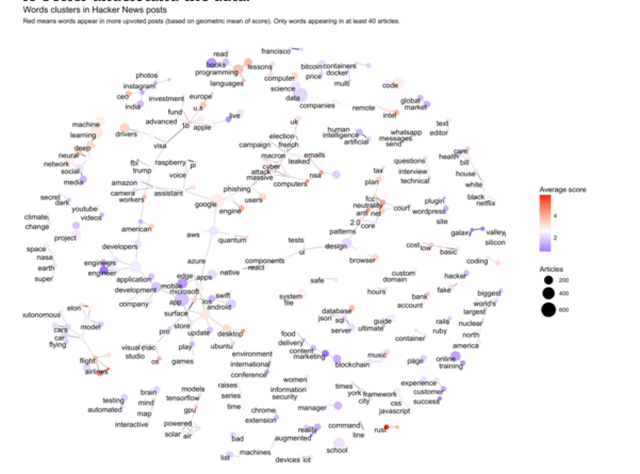
我们注意到词汇中的集群,例如一个带有“机器/深度学习”的ML集群,以及各种各样的政治集群,如“网络/中立性”和“trump/fbi”。这帮助我们把注意力集中在可用的话题上。
下面是我们用来训练模型的正则表达式。当我们研究结果的分类是否正确,移除导致清除错误的正则表达式,并添加一些我们遗漏的部分时,这都是需要进行大量的迭代和调整。
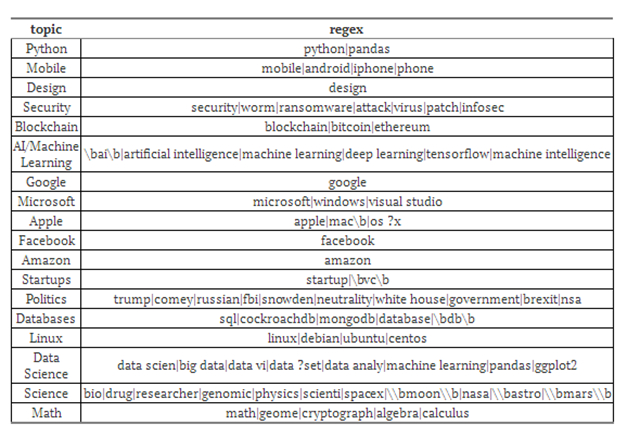
R语言中的fuzzyjoin使得匹配这些标题变得很容易。你可以在这个存储库中找到代码和一些分析程序,以及我们的机器学习工作。
最后我们得到了一个大约10,000个标记文档的训练集(注意不是所有的标题都匹配任何正则表达式,有些可以匹配多个)。与每一个正则表达式匹配的是:
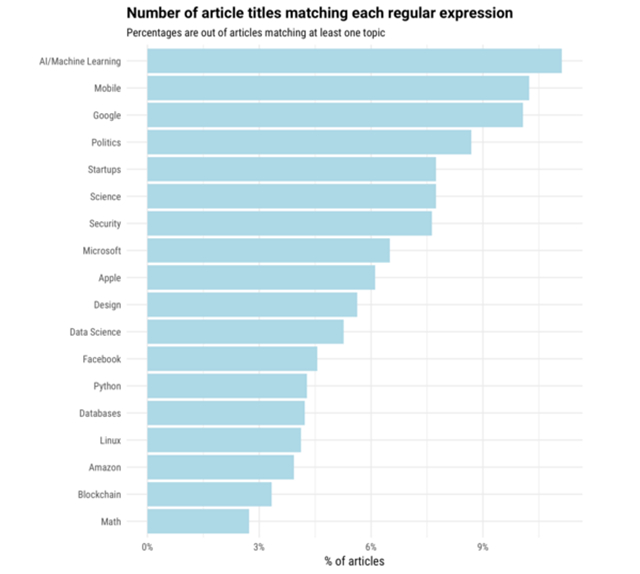
(我们起初还有一些其他的主题,比如“Web开发”和“Javascript”,但最终基于分类的结果删除了它们)。注意,这并不意味着这些就是站点上最流行的主题!它完全基于我们为每个主题决定的正则表达式——如果一些主题比其他主题更容易识别,或者如果这些正则表达式有一些疏漏,那么该文章将不会被反映出来。
在标题上使用正则表达式是一种非常粗糙的获取示例的方式,而且不会完全准确(例如,关于“调整窗口大小(resizing windows)”的标题将被标记为Microsoft)。但是,它可以是一种快速有效的方法来构建一个规模庞大的训练集,并且手工检查的结果使我们确信它是准确的。
一旦我们在这些标题上训练了算法,它就能够识别出标题中没有任何这些特征的文章。例如,在标题拒绝信( Rejection Letter)中没有提到它的主题,所以它不在我们的训练集里,但是因为标题包含了诸如“安全”、“勒索软件”、“防病毒”和“蠕虫”之类的单词,在我们的训练集里经常出现的单词——这个算法很容易把它标记为“安全”。
培训和生产ML模型
在我们用R语言来探索数据之后,我们使用Python的scikit学习包让机器进行学习。这需要三个步骤:
- 标记化:我们把每一篇文章都变成了一组单词,用一种“单词袋(bag of words)”方法(我们忽略了单词的顺序和结构)。
- 维度减少:我们使用了由(gensim Python包)实现的Latent Dirichlet分配,将单词适合于主题模型,将每个文档转换为长度为100的向量。每一主题都与数据相匹配,与特定的单词组相关联(例如,一个主题可能与“特朗普”、“科米”、“俄罗斯”有高度关联,而另一个主题则侧重于“设计”、“photoshop”、“css”)。
- 监督分类:我们使用一种监督分类器来预测。我们尝试了两种方法:正则化逻辑回归和随机森林。
我以前写过主题建模(它在我们的《Text Mining with R》书中扮演着重要的角色)。在这里,我们不是用它来做结论,而是用它将我们数以万计的特性(“这篇文章包含了“比特币”这个词,而不是“)减少到100维的数据集里。通过一些试验,我们发现添加这个主题建模步骤(而不是直接使用文字作为特性)提高了我们对模型的准确性。
我们还发现,随机森林在我们训练集上的交叉验证的AUC(ROC曲线下的区域)方面打败了正则化逻辑回归:
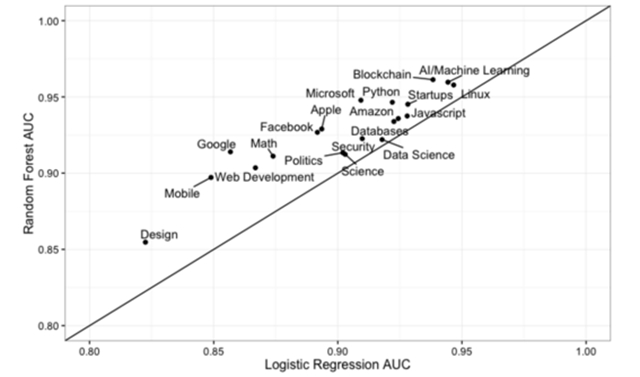
这与围绕这些模型的普遍声誉相吻合。逻辑回归更快地进行了训练,并且有了更多的解释,但是在处理许多特性交互的情况下,它并没有那么好。例如,它不会注意到“学习”这个词与“大学”或“教育”这个词的含义不同。
当然,这个训练集的“准确性”只是意味着“可以预测文章的标题是否与我们认为的正则表达式相符”,但我们希望这将转化为对新文章的现实预测。
生产模型
当Chris和我在建造这个模型时,Nathan和Dan已经使用Django开发好了网站,部署在Heroku上,并注册了一个域名。它每隔十分钟与Hacker News API同步,但作为一个占位符,它被指定为完全随机的主题。大约凌晨2点,我和Chris有了一个训练有素的模型,是时候把我们的努力结合起来了。
理论上,在Python中构建算法和网站应该是很简单的,因为我们可以将它直接插入到站点中的一个函数中。我已经习惯通过与我的团队合作将R转换为ci来生产模型,因此,用pickle将模型序列化并直接加载到应用程序的能力当然是很方便的,并且让我们能够灵活地使用我们实现的模型。
但这并不意味着部署就是十分顺利的!我们遇到的两个最大的问题是:
使用nltk Heroku。最初使用nltk库进行标记化,因为它是Python自然语言处理最强大的工具包。但是它是一个庞大而又笨重的库,开始在Heroku上运行一些关于安装和使用它的模糊错误消息。为了方便,最终切换到gensim(已经需要进行主题建模)的记号赋予器,这需要重新培训算法。
Python 2和3之间的pickle:可以在python3上安装这个模型,但是用来查询文章文本的Goose,不是Python 3兼容的,我们的生产站点必须在python2中。这就是我们在Python 2和3之间遇到了bug的时候。那时是凌晨4点,修复需要一些非常不雅的黑客攻击。
最初考虑将机器学习过程作为一个微服务(通过网站传递文本内容以及返回分类的独立的服务)。它将会使机器学习算法的切换变得更加轻松(给web团队一个API端点,而不是代码和一个软件包需求列表)。
交流和分享
而且,我们在taggernews.com网站上有一个实时网站。从那以后我们改变了网站,但是当我们在凌晨4点30分提交项目的时候它看起来是这样的:

Tagger News可以自动对Hacker News的文章进行分类和排序
# HackDisrupt pic.twitter.com/2mEbrGXIce
——TechCrunch(@TechCrunch),2017年5月14日
演讲结束后,TechCrunch采访了我们,写了一篇关于我们的项目的文章,在这些黑客马拉松活动中,我们是第一个!黑客马拉松结束后,我决定完成这个剩余部分,并将TechCrunch的文章提交给Hacker News,我们很高兴用户可以在社区看到并且喜欢:
我们在产品搜寻上也做得很好。
根据Google Analytics的数据,昨天Tagger News大概有6,000访客,而且数量还在继续增长。我们也很紧张当访问量达到更多的时候,应用程序会如何处理——我们在凌晨4:30完成的,而且没有足够的时间进行测试。但是除了一些关于设计的评论和一些无意中错误分类的文章,反馈还是非常积极的!该网站不断添加新故事,而且大部分内容都是正确分类的。它是一个概念的证明,但是是一个功能性的,它让我们尝试一个有趣的分类问题并把方法付诸实践。