背景
有一个业务需要分 1000 个库,每一个库中都有 80 个表,总共就是 80000 * 2 个文件。文件使用率还挺高,大概是 60000 * 2。
这个业务采用的高可用架构是 MMM,由于集群机器在硬件检查时发现有问题,必须要换掉。于是想了一个比较简单、影响面较小的方法去解决,就是找了另外两台机器迁移过去。同时,要求这四台机器属于同一个网段,VIP(虚拟 IP 地址)在机器之间可以漂移,这样业务就不需要修改 IP 地址即可迁移,相当于两次主从切换过程。
切换方案如图 16.1 所示。
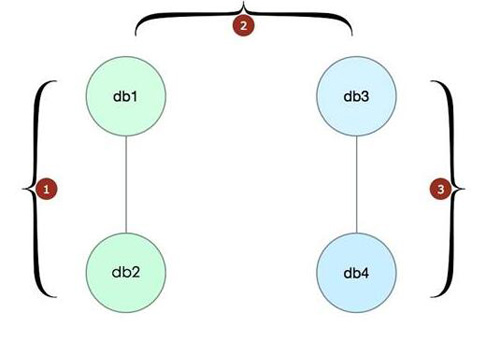
从图 16.1 中可以看到,切换过程很简单,如下三步。
- 先将原来的写节点(db1)与一个新的节点(db3)切换成一套集群,也就是把在 db2 上面的 VIP(读流量)切换到 db3 上面,此时 db1 与 db3 组成一套新集群。
- 接着将 db1 和 db3 的角色互换,让 db3 成为写节点,db1 成为读节点。
- 最后,再将 db1 读节点上面的 VIP(读流量)切换到 db4 上面,此时新的集群就是 db3 和 db4,db3 为写节点,已经切换完成。这样的变更是晚上做的。做好之后,观察了一段时间,发现没有什么问题(因为压力小),所以觉得事情完成了,睡吧。 第二天上班之后,业务反映说迁移之后,数据库比原来慢了 10 倍(10 倍啊!感觉不可思议)。询问了一番,说没有任何变更,只是做了迁移之后就成这样了。同时经过观察,只有写库的读操作变慢了,而读库的读是不慢的。最后,业务已经受不了了,要求切换回去。还好,db1 还正在从 db3 复制,做了一个回退操作,把写挂在 db1 上面,把读挂在 db3 上面。神奇的是,问题解决了!好吧,那就先这样,走出去的路不能回头,总是要迁出去的,所以先在新旧两台机器上面挂着,查明原因后再切换回去(这样少做一步)。
以上是背景。
问题分析
环境对比
- db1 写入时,db1 写不慢,读不慢,db3 也不慢。
- db3 是新的硬件,db1 是老的、有问题的硬件。
- db3 切换成写之后,在慢查询文件中明显看到很多慢查询(使用相同的语句查询,原来是 50ms,现在是 500ms),和监控是一致的。
- db1 和 db3 配置文件有差别,如图 16.2 所示(左边是 db3 的,右边是 db1 的)。
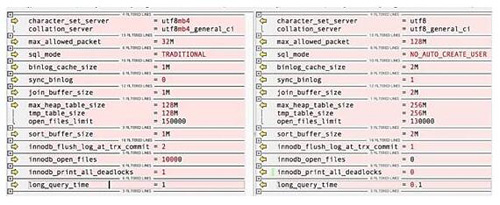
其他方面,环境完全相同,业务方面没有任何更改,重现慢的现象,只是需要切换而已。
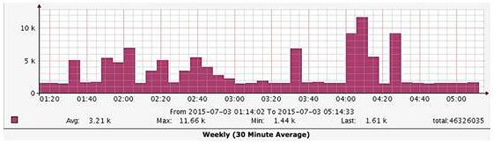
图 16.3 是切换过程中的监控图,高起来的就是把流量切换到 db3 的情况,处于低谷的就是切换到 db1 的情况,效果非常明显,慢得立竿见影,好神奇!
原因分析
- 从对比中可以得知,db1 是正常的(以前长时间在这个机器上跑,没有问题),而 db3 是不正常的。这个业务目前是读多写少,现在的现象是读慢。因为写少,没有发现慢,就不考虑了。
- 接着就是硬件的区别,二者都是 PCI-e 卡,老的、坏的概率比较大,从经验上来看新的会比较好,这是一个值得怀疑的点。但实际上,针对这个问题,找到了新卡的技术人员进行分析,将写切换到 db3 上之后观察,发现 IO 非常小,能看到的监控指数都非常正常。(他们也很纳闷。)
- 除此之外,唯一的区别就是二者的配置了,但从图 16.3 中可以看到,没有一个参数可以影响到让数据库的响应时间是原来的 10 倍。
但上面这些都只是分析,硬件测试之后,没有发现问题(也不能说就不是硬件的问题,一直吊在那里)。那只剩下配置了,所以接下来从这里入手吧,希望能成功!
那么,再找一个夜深人静的夜晚……
案例解决
首先要做的事情是,把 db3 的读流量切换到 db1,然后把配置完全换成 db1 的配置,将数据库重启,然后上线。此时,db1 是写节点,db3 是读节点,最神奇的时刻即将到来。
切换之后,经过观察,竟然没有问题了。问题已经解决,那么说明还是上面列出来的配置差别引起的问题。
那么解决之后,下面的工作就是重复一开始的工作,把 db1 下线,让 db4 上线。此刻,之前的迁移工作已经完成,线上服务没有问题。
但……开发同学,能给我半个小时,让我看看是哪个参数引起的么? 得到的回答是:“迅速点,就这一次,给你 20 分钟。”
把最有可能的参数找出来,比如字符集(实际上,上面列出的每一个,我们认为都不会有多大影响),考虑到字符集是不可动态修改的参数,所以先把这个改了。重启,然后一个一个地动态修改、业务重启重连等,都没有发现。修改的这些参数包括:sql_mode、join_buffer_size、max_heap_size、sort_buffer_size,这些都没有影响。
结果已经说好的只有这一次,那就这样吧,任务成功完成,问题解决失败。
然而,这个问题“才下手头,却上心头”,总有一件事放心不下,约吧。 和开发商量了一下,我们想解决这个问题,知道其所以然,防止在其他业务上出现同样的问题。好吧,再给你们一次机会(来之不易啊)。
那么,再找一个夜深人静的夜晚……这次的月亮好像比上次更圆一些,是好日子的征兆么?
操作之前,还简单规划了一下,下面是当时的一个计划步骤。
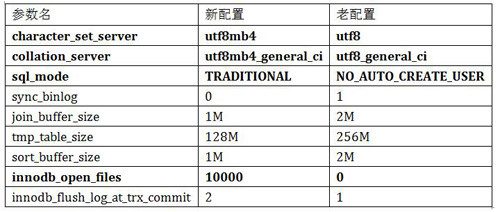
^* 黑体的表示已经专门测试过,没有影响
步骤如下。
考虑到先重现问题,首先应该全部使用新配置测试一次,确定问题是否还存在。
因为重点考虑问题是因为 sql_mode 引起的,所以第二次只将这个参数改为老配置,这样就可以测试出其他配置组合时有问题,或者是没有问题,从而得出结论是 sqlmode 的问题。
如果上面还没有找到问题原因,那么就是除了 sql_mode 之外的其他参数组合出了问题(如果没有,则见鬼了)。此时,通过二分法测试,先测试 innodb_flush_log_at_trx_commit、innodb_open_files、sort_buffer_size 三个参数。
如果发现上一步有问题,则再进行二分;如果没有发现问题,则对 sync_binlog、join_buffer_size、tmp_table_size 进行二分。
如果能走到这里,那也是醉了。
再说吧。
按照步骤,一步步地开始做。
首先使用有问题的配置,测试一遍,发现是老样子,还是有问题的(真是幸运,问题还存在)。
把除了 sql_mode 之外的所有参数改成新的,其他都用老配置,测试发现没有问题。
做完了,也是没有问题。
做完了,还是没有问题。
我醉了。
此时当事人已经搞不清楚了,难道是某两个的组合会导致出现这样的问题?如果是这样的话,那情况就太多了,天已经亮了,很累,放弃吧!
就在想放弃的时候,突然有一种新的思路。在有问题的基础上,把所有经过测试没有影响的可以动态修改的参数改成与 db1 相同的参数,这样应该是最少量的可以影响到性能的参数组合了。此时,在 db1 与 db3 实例上分别执行 show variables,全量导出变量,进行对比,发现有几个参数的区别(左边是老的 db1,右边是新的 db3),如图 16.4 所示。
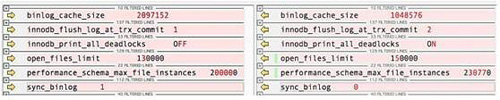
此时,我们做了最后的挣扎,已经只剩下这 6 个了,看上去还是不会有什么影响,有些已经试过了,再随便试一次吧。二分查找,从下面开始找了三个参数,下线、重启、上线……发现问题竟然奇迹般地存在。而此时只剩下了三个参数,其中一个参数是 sync_binlog,有问题的是 0,肯定不会影响啊。只能定位到剩下的两个了,可以看到倒数第二个是一个 performance_schema 的参数,配置文件中没有设置,是默认的,可以忽略。于是,把问题定位到 open_files_limit 了。
此时,再做最后一次,只剩下 open_files_limit 的区别了。结果还是有问题,说明就是这个参数了。
回过头来想了一下,其实当初看区别的时候,这两个参数就在配置文件中,只是看着 13 万和 15 万相差不大,就忽略了。好吧,问题已经解决,找到了原因,天亮了,回家吧。
已经查到了是 open_files_limit 的原因。那么,究竟为什么在一个参数相差这么小的情况下会影响 10 倍的性能呢?查查源码!
通过 sysbench,创建 60000 个表,每个表 10000 行,在只读模式下,发现设置为 130000 时,QPS 可以达到 20000,而设置为 150000 的时候,QPS 只有 4000 左右。问题重现了,就简单多了。
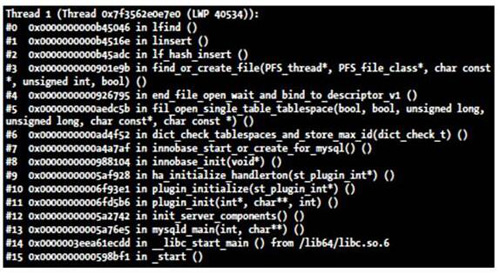
此外,还有一个额外的发现。如果设置为 150000 之后,重启数据库,非常慢,大概需要 1 分钟,而设置为 130000 之后,只需要 10 秒左右。查看了一下在很慢的过程中 mysqld 的线程情况。其中,在启动的过程中,有一个线程长时间都基本处于同一个堆栈,使用 pstack mysqldpid 查看,如图 16.5 所示。
还有一个发现就是,当设置 open_files_limit 为相同的时候,performance_schema_max_file_instances 参数也相同了,并且这个参数没有设置过。那么,通过源码发现,这个参数竟然是通过 open_files_limit 值来设置的。如果 open_files_limit 值设置得比较大(这样就可以忽略掉其他影响条件,比如 max_connection 等),performance_schema_max_file_instances 的值直接就是从 open_files_limit/0.65 得来的(源码对应函数 apply_load_factor)。这样就知道了,130000/0.65 正好是 200000,150000/0.65 正好是 230770,与图 16.4 所示相符合。
另外,通过测试发现,如果单独设置 performance_schema_max_file_instances 为不相同的值,而将 open_files_limit 设置为相同,性能还是不一样。从而可以确定与 open_files_limit 参数实际上没有什么关系,只是 performance_schema_max_file_instances 使用了默认值,它的值就来源于 open_files_limit/0.65 了,这样间接影响了 performance_schema_max_file_instances 值,突然有种“隔山打牛”的感觉。
还有一个发现,如果将 performance_schema_max_file_instances 设置为 200000、210000、220000、230000、240000、300000 等,性能都是差不多的,唯独设置为 230770 是有问题的。仔细研究之后发现,performance_schema_max_file_instances 最终影响的是 performance_schema 数据库中的 file_instances 表,这个表中的数据是通过一个 HASH 表来缓存的,而这个参数决定的是该 HASH 表的大小。
后面又做了一个非常无聊的测试,是 performance_schema_max_file_instances 值与 QPS 的对比,如图 16.6 所示。
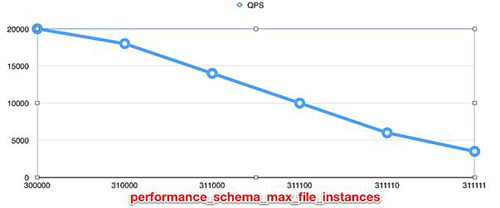
至此,一切都豁然开朗了。结合上面非常慢的堆栈,以及将 performance_schema_max_file_instances 设置为不同值的现象,可以确定,这个问题最终是 HASH 算法的问题。当 HASH 桶大小为一个比较好看的数值时,这个算法就非常快,而如果是一个比较零碎的值时,算法就非常慢了,会导致响应时间是原来的 10 倍。
总结
这个问题,确实很诡异,万万没有想到是相差那么小的一个变量的问题(以至于一开始就被忽略了)。
这个问题,比较少见,只有表比较多的时候才会比较明显(因为表比较少的时候,算法相对比较稳定)。
这个问题,查明了,其实就是一个算法方面的 BUG。
这个问题,简单的规避方法是单独设置 performance_schema_max_file_instances 值为 0,或者设置 performance_schema_max_file_instances 为一个比较好看的数值,又或者设置 open_files_limit 为 0.65 的整数倍,这样都不会有问题。
这个问题,虽然影响比较小,但我们对问题的探索精神不能没有,要了然于胸。
这个问题,到此为止。