关于Android模块化我有一些话不知当讲不当讲
最近公司一个项目使用了模块化设计,本人参与其中的一个小模块开发,但是整体的设计并不是我架构设计的,开发半年有余,在此记录下来我的想法。
模块化场景
为什么需要模块化?
当一个App用户量增多,业务量增长以后,就会有很多开发工程师参与同一个项目,人员增加了,原先小团队的开发方式已经不合适了。
原先的一份代码,现在需要多个人来维护,每个人的代码质量也不相同,在进行代码Review的时候,也是比较困难的,同时也容易会产生代码冲突的问题。
同时随着业务的增多,代码变的越来越复杂,每个模块之间的代码耦合变得越来越严重,解耦问题急需解决,同时编译时间也会越来越长。
人员增多,每个业务的组件各自实现一套,导致同一个App的UI风格不一样,技术实现也不一样,团队技术无法得到沉淀。
架构演变
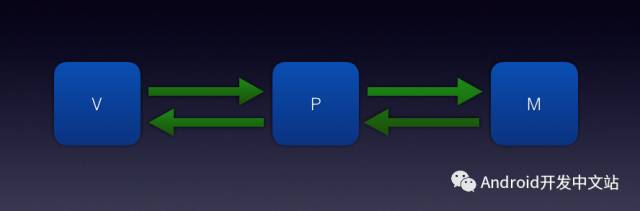
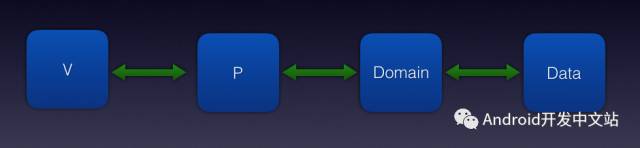
在刚刚开始的时候,项目架构使用的是MVP模式,这也是最近几年很流行的一个架构方式,下面是项目的原始设计。
随着业务的增多,我们添加了Domain的概念,Domain从Data中获取数据,Data可能会是Net,File,Cache各种IO等,然后项目架构变成了这样。
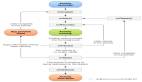
再然后随着人员增多,各种基础组件也变的越来越多,业务也很复杂,业务与业务之间还有很强的耦合,就变成了这样的。
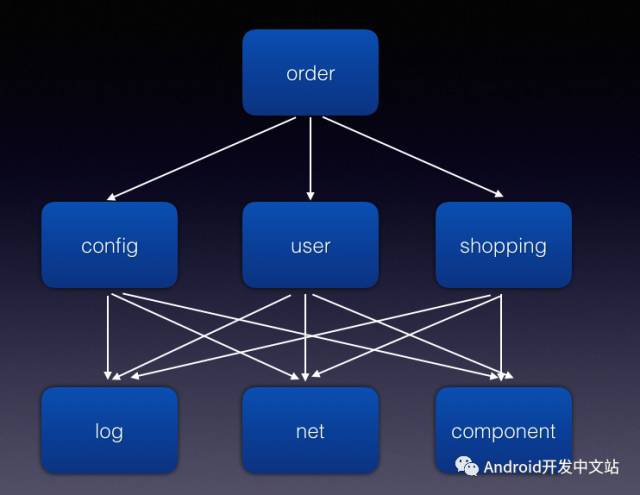
使用模块化技术以后,架构变成了这样。
技术要点
这里简单介绍下Android项目实现模块化需要使用的技术以及技术难点。
Library module
在开始开始进行模块化之前,需要把各个业务单独抽取成Android Library Module,这个是Android Studio自带一个功能,可以把依赖较少的,作为基本组件的抽取成一个单独模块。
如图所示,我把各个模块单独分为一个独立的项目。
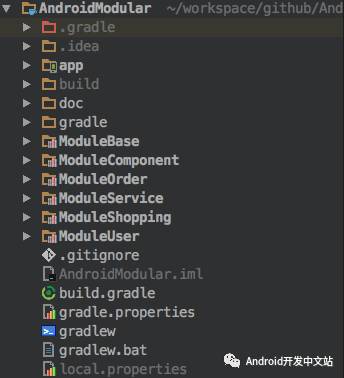
在主项目中使用gradle添加代码依赖。
- // common
- compile project(':ModuleBase')
- compile project(':ModuleComponent')
- compile project(':ModuleService')
- // biz
- compile project(':ModuleUser')
- compile project(':ModuleOrder')
- compile project(':ModuleShopping')
Library module开发问题
在把代码抽取到各个单独的Library Module中,会遇到各种问题。最常见的就是R文件问题,Android开发中,各个资源文件都是放在res目录中,在编译过程中,会生成R.java文件。R文件中包含有各个资源文件对应的id,这个id是静态常量,但是在Library Module中,这个id不是静态常量,那么在开发时候就要避开这样的问题。
举个常见的例子,同一个方法处理多个view的点击事件,有时候会使用switch(view.getId())这样的方式,然后用case R.id.btnLogin这样进行判断,这时候就会出现问题,因为id不是经常常量,那么这种方式就用不了。
同样开发时候,用的最多的一个第三方库就是ButterKnife,ButterKnife也是不可以用的,在使用ButterKnife的时候,需要用到注解配置一个id来找到对应view,或者绑定对应的各种事件处理,但是注解中的各个字段的赋值也是需要静态常量,那么就不能够使用ButterKnife了。
解决方案有下面几种:
1.重新一个Gradle插件,生成一个R2.java文件,这个文件中各个id都是静态常量,这样就可以正常使用了。
2.使用Android系统提供的最原始的方式,直接用findViewById以及setOnClickListener方式。
3.设置项目支持Databinding,然后使用Binding中的对象,但是会增加不少方法数,同时Databinding也会有编译问题和学习成本,但是这些也是小问题,个人觉的问题不大。
上面是主流的解决方法,个人推荐的使用优先级为 3 > 2 > 1。
当把个模块分开以后,每个人就可以单独分组对应的模块就行了,不过会有资源冲突问题,个人建议是对各个模块的资源名字添加前缀,比如user模块中的登录界面布局为activity_login.xml,那么可以写成这样us_activity_login.xml。这样就可以避免资源冲突问题。同时Gradle也提供的一个字段resourcePrefix,确保各个资源名字正确,具体用法可以参考官方文档。
依赖管理
当完成了Library module后,代码基本上已经很清晰了,跟我们上面的最终架构已经很相似了,有了最基本的骨架,但是还是没有完成,因为还是多个人操作同一个git仓库,各个开发小伙伴还是需要对同一个仓库进行各种fork和pr。
随着对代码的分割,但是主项目app的依赖变多了,如果修改了lib中的代码,那么编译时间是很恐怖的,大概统计了一下,原先在同一个模块的时候,编译时间大概需要2-3min,但是分开以后大概需要5-6min,这个是绝对无法忍受的。
上面的***问题,可以这样解决,把各个子module分别使用单独的一个git仓库,这样每个人也只需要关注自己需要的git仓库即可,主仓库使用git submodule的方式,分别依赖各个子模块。
但是这样还是无法解决编译时间过长的问题,我们把各个模块也单独打包,每次子模块开发完成以后,发布到maven仓库中,然后在主项目中使用版本进行依赖。
举个例子,比如进行某一版本迭代,这个版本叫1.0.0,那么各个模块的版本也叫同样的版本,当版本完成测试发布后,对各个模块打对应版本的tag,然后就很清楚的了解各模块的代码分布。
gradle依赖如下。
- // common
- compile 'cn.mycommons:base:1.0.0'
- compile 'cn.mycommons:component:1.0.0'
- compile 'cn.mycommons:service:1.0.0'
- // biz
- compile 'cn.mycommons:user:1.0.0'
- compile 'cn.mycommons:order:1.0.0'
- compile 'cn.mycommons:shopping:1.0.0'
可能有人会问,既然各个模块已经分开开发,那么如果进行开发联调,别急,这个问题暂时保留,后面会对这个问题后面再表。
数据通信
当一个大项目拆成若干小项目时候,调用的姿势发生了少许改变。我这边总结了App各个模块之间的数据通信几种方式。
- 页面跳转,比如在订单页面下单时候,需要判断用户是否登录,如果没有则需要跳到登录界面。
- 主动获取数据,比如在下单时候,用户已经登录,下单需要传递用户的基本信息。
- 被动获得数据,比如在切换用户的时候,有时候需要更新数据,如订单页面,需要把原先用户的购物车数据给清空。
再来看下App的架构。
***个问题,原先的方式,直接指定某个页面的ActivityClass,然后通过intent跳转即可,但是在新的架构中,由于shopping模块不直接依赖user,那么则不能使用原始的进行跳转,我们解决方式使用Router路由跳转。
第二个问题,原先的方式有个专门的业务单利,比如UserManager,直接可以调用即可,同样由于依赖发生了改变,不能够进行调用。解决方案是所有的需要的操作,定义成接口放在Service中。
第三个问题,原先的方式,可以针对事件变化提供回调接口,当我需要监听某个事件时候,设置回调即可。
页面路由跳转
如上分析,原先方式代码如下。
- Intent intent = new Intent(this, UserActivity.class);
- startActivity(intent);
但是使用Router后,调用方式改变了。
- RouterHelper.dispatch(getContext(), "app://user");
具体的原理是什么,很简单的,做一个简单的映射匹配即可,把"app://user"与UserActivity.class配对,具体的就是定义一个Map,key是对应的Router字符,value是Activity的class。在跳转时候从map中获取对应的ActivityClass,然后在使用原始的方式。
可能有人的会问,要向另外一个页面传递参数怎么办,没事我们可以在router后面直接添加参数,如果是一个复杂的对象那么可以把对象序列化成json字符串,然后再从对应的页面通过反序列化的方式,得到对应的对象。
例如:
- RouterHelper.dispatch(getContext(), "app://user?id=123&obj={"name":"admin"}");
注: 上面的router中json字符串是需要url编码的,不然会有问题的,这里只是做个示例。
除了使用Router进行跳转外,我想了一下,可以参考Retrofit方式,直接定义跳转Java接口,如果需要传递额外参数,则以函数参数的方式定义。
这个Java接口是没有实现类的,可以使用动态代理方式,然后接下来的方式,和使用Router的方式一样。
那么这总两种方式有什么优缺点呢。
Router方式:
- 有点:不需要高难度的技术点,使用方便,直接使用字符串定义跳转,可以好的往后兼容
- 缺点:因为使用的是字符串配置,如果字符输入字符,则很难发现bug,同时也很难知道某个参数对应的含义
仿Retrofit方式:
- 因为是Java接口定义,所以可以很简单找到对应的跳转方法,参数定义也很明确,可以直接写在接口定义处,方便查阅。
- 同样因为是Java接口定义,那么如果需要扩展参数,只能重新定义新方法,这样会出现多个方法重载,如果在原先接口上修改,对应的原先调用方也要做响应的修改,比较麻烦。上面是两种实现方式,如果有相应同学要实现模块化,可以根据实际情况做出选择。
Interface和Implement
如上分析,如果需要从某个业务中获取数据,我们分别需要定义接口以及实现类,然在获取的时候在通过反射来实例化对象。
下面是简单的代码示例
接口定义
- public interface IUserService {
- String getUserName();
- }
实现类
- class UserServiceImpl implements IUserService {
- @Override
- public String getUserName() {
- return "UserServiceImpl.getUserName";
- }
- }
反射生成对象
- public class InjectHelper {
- @NonNull
- public static AppContext getAppContext() {
- return AppContext.getAppContext();
- }
- @NonNull
- public static IModuleConfig getIModuleConfig() {
- return getAppContext().getModuleConfig();
- }
- @Nullable
- public static <T> T getInstance(Class<T> tClass) {
- IModuleConfig config = getIModuleConfig();
- Class<? extends T> implementClass = config.getServiceImplementClass(tClass);
- if (implementClass != null) {
- try {
- return implementClass.newInstance();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- return null;
- }
- }
实际调用
- IUserService userService = InjectHelper.getInstance(IUserService.class);
- if (userService != null) {
- Toast.makeText(getContext(), userService.getUserName(), Toast.LENGTH_SHORT).show();
- }
本示例中每次调用都是用反射生成新的对象,实际应用中可能与IoC工具结合使用,比如Dagger2.
EventBus
针对上面的第三个问题,原先设计的使用方式也是可以的,只需要把回调接口定义到对应的service接口中,然后调用方就可以使用。
但是我建议可以使用另外一个方式——EventBus,EventBus也是利用观察者模式,对事件进行监听,是设置回调更优雅方式的实现。
优点:不需要定义很多个回调接口,只需要定义事件Class,然后通过Claas的***性来进行事件匹配。
缺点:需要定义很多额外的类来表示事件,同时也需要关注EventBus的生命周期,在不需要使用事件时候,需要注销事件绑定,不然容易发生内存泄漏。