













在机器人围棋大胜李世石、柯洁之后,人工智能越来越火。作为一项新兴技术,智能问答也是人工智能中必不可少的一环。智能问答一般用于解决企业客服、智能资讯等应用场景,实现的方式多种多样,包括简单的规则实现,也可以基于检索实现,还可以通过encoder-decoder框架生成,本文通过几种常见的问答技术,概要介绍了达观数据智能问答相关原理研究。
1. 基于规则的智能问答
基于规则的智能问答通常是预先设置了一系列的问答规则,在用户输入一个问题时,去规则库里匹配,看是否满足某项规则,如果满足了就返回该规则对应的结果。如规则库里设置“*你好*”->“你好啊!”,那么用户在输入“你好”时,机器人会自动返回“你好啊!”。如果规则库非常庞大,达到了海量的级别库,则可对规则建立倒排索引,在用户新输入一个问题时,先去倒排索引中查找***的规则集合,再通过这个集合中的规则进行匹配返回。
使用规则库的智能问答优点是简单方便,准确率也较高;缺点是规则库要经常维护扩展,而且覆盖的范围小,不能对新出现的问题进行回答。
2. 基于检索的智能问答
基于检索的智能问答很像一个搜索引擎,但又和搜索引擎不同,相比搜索引擎而言,智能问答更侧重于用户意图和语义的理解。它基于历史的问答语料库构建索引,索引信息包括问题、答案、问题特征、答案特征等。用户问问题时,会将问题到索引库中匹配,首先进行关键字和语义的粗排检索,召回大量可能符合答案的问答对;然后通过语义和其他更丰富的算法进行精排计算,返回***的一个或几个结果。
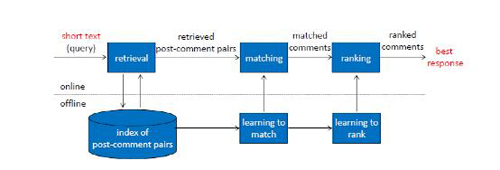
图1
2.1 粗排策略
粗排策略跟一般的搜索引擎非常类似,主要基于的技术包括粗细粒度分词、词重要性计算、核心词识别、命名实体识别、语义归一等相关技术,主要是为了在粗排阶段尽可能地把相关问题进行召回。
1) 词重要性计算:通过计算重要性,越能表示问题的词汇权重越高,在召回时***这些词汇的候选集越有可能被召回。如:“靠谱的英语培训机构有哪些?”,在这个问题中,“英语”、“培训”、“机构”是高权重的词,“靠谱”是较高权重的词,“哪些”是较低权重的词;因此越符合“英语培训机构”的答案越有可能被召回。
2) 核心词识别:核心词就是候选集中必须相关的词。如“北京住宿多少钱?”
,核心词是“北京”、“住宿”,如果候选集中没有这两个相关的词,如“上海住宿多少钱?”,“北京吃饭多少钱”,都是不符合问题需求的。
3) 命名实体识别:通过命名实体识别,能协助识别出问题答案中的核心词,也可以对核心专有名词进行重要性加权,辅助搜索引擎提升召回效果。
4) 语义归一也是扩大召回的重要手段,同一个问题可能有很多种问法,不同的问法如果答案不同,或者召回的结果数目不同,就会很让人烦恼了,比如“刘德华生日是哪天?”、“刘德华出生在哪一天?”,如果不作语义归一的话,有可能某一个问题都不会召回结果。
2.2 精排策略
通过粗排,搜索引擎已经返回了一大批可能相关的结果,比如500个,如何从这500个问题中找到***问题的一个或者几个,非常考验算法精度。一般基于检索的问答系统都会通过语义或者深度学习的方法寻找最匹配的答案。
1) 基于句子相似度的算法。
基于句子相似度的算法有很多种,效果比较好的有基于word2vec的句子相似度计算和基于sentence2vec的句子相似度计算。基于word2vec计算两个句子的相似度,就是以词向量的角度计算***个句子转换到***个句子的代价:
词向量有个有趣的特性,通过两个词向量的减法能够计算出两个词的差异,这些差异性可以应用到语义表达中。如:vec(Berlin) – vec(Germany) = vec(Paris) – vec(France);通过这个特性能够用用来计算句子的相似度。假设两个词xi, xj之间的距离为ci, j= xi- xj2,这可以认为是xi转换到xj的代价。可以将句子用词袋模型d∈Rn表示,模型中某个词i的权重为di= cij=1ncj,其中ci是词i在该句子中出现的次数。设置 T∈Rn*n为一个转换矩阵,Tij表示句子d中词i有多少权重转换成句子d’中的词j,如果要将句子d完全转换成句子d’,所花费的代价计算如下:
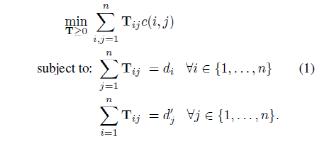
如果用Xd表示句子中的词向量通过权重di进行加权平均的句向量,可以推导出,句子转换代价的下限是两个句向量的欧式距离。
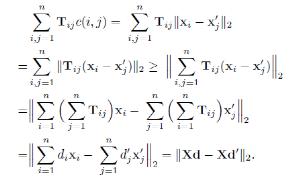
一般这个下限表示两个短句子相似的程度已经足够了,如果需要通过完全***化的方法计算minT≥0i, j =1nTijc(i, j)的值,可以通过EMD solver算法计算。
2) 基于深度学习计算问答匹配程度。
基于句向量的距离计算句子相似度,可以cover大部分的case,但在句子表面相似,但含义完全不同的情况下就会出现一些问题,比如“我喜欢冰淇淋”和“我不喜欢冰淇淋”,分词为“我”,“不”,“喜欢”,“冰淇淋”,两个句子的相似度是很高的,仅一字“不”字不同,导致两个句子意思完全相反。要处理这种情况,需要使用深度模型抓住句子的局部特征进行语义识别。
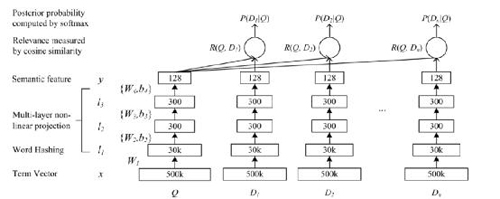
图2
如图所示,Q是用户的问题,D是返回的各个答案。对于某一个问答句子,首先将它映射到500k大小的BOW向量Term Vector里。因为Term Vector是稀疏矩阵,可以使用Word Hashing或者其他Embedding的方法将其映射到30k大小的词向量空间里。接下来的l1, l2, l3层就是传统的MLP网络,通过神经网络得到query和document的语义向量。计算出(D,Q)的cosine similarity后,用softmax做归一化得到的概率值是整个模型的最终输出,该值作为监督信号进行有监督训练。模型通过挖掘搜索点击日志构造的query和对应的正负document样本(点击/不点击),输入DSSM进行训练。
3) 基于卷积神经网络计算问答匹配程度。
句子中的每个词,单独来看有单独的某个意思,结合上下文时可能意思不同;比如“Microsoft office”和“I sat in the office”,这两句话里的office意思就完全不一样。通过基于卷积神经网络的隐语义模型,我们能够捕捉到这类上下文信息。
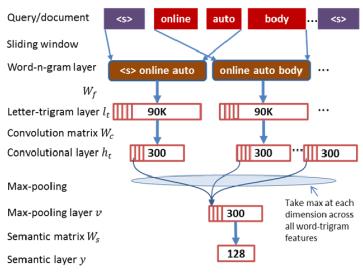
图3
如图所示,先通过滑窗构造出query或document中的一系列n-gram terms,比如图中是Word-n-gram layer中的trigram;然后通过word-hashing或者embedding将trigram terms表示为90k的向量;通过卷积向量Convolution matrix Wc对每个letter-trigram向量作卷积,可以得到300维的卷积层Convolutional layer;***通过max-pooling取每个维度在Convolutional layer中的***值,作为文本的隐语义向量。模型也是通过挖掘搜索日志进行有监督训练。
通过卷积神经网络,能得到句子中最重要的信息。如下面一些句子,高亮的部分是卷积神经识别的核心词,它们是在300维的Max-pooling层向量里的5个***神经元激活值,回溯找到原始句子中的词组。
microsoft office excel could allow remote code execution
welcome to the apartment office
4) 基于主题模型计算问答匹配程度。
短文本一般词语比较稀疏,如果直接通过共现词进行匹配,效果可能会不理想。华为诺亚方舟实验室针对短文本匹配问题,提出一个DeepMatch的神经网络语义匹配模型,通过(Q, A)语料训练LDA主题模型,得到其topic words,这些主题词用来检测两个文本是否有语义相关。该模型还通过训练不同“分辨率”的主题模型,得到不同抽象层级的语义匹配(“分辨率”即指定topic个数,高分辨率模型的topic words通常更加具体,低分辨率的topic words通常更加抽象)。在高分辨率层级无共现关系的文本,可能在低分辨率存在更抽象的语义关联。DeepMatch模型借助主题模型反映词的共现关系,可以避免短文本词稀疏带来的问题,并且能得到不同的抽象层级的语义相关性。
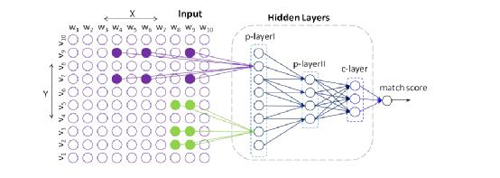
图4
如图所示,绿色和紫色块分别表示在同一个分辨率下不同的主题在X和Y文本中***的主题词块,与上一层分辨率(p-layerII)的主题的关联通过是否与上一层的主题词块有重叠得到。如此通过多层的主题,能够构建出神经网络,并使用有监督的方式对相关权重进行训练。
3. 基于产生式的智能问答
基于产生式的智能问答系统,主要是通过seq2seq的方式,通过一个翻译模型的方式进行智能回答,其中问题是翻译模型的原语言,答案是翻译模型的目标语言。Seq2seq模型包含两个RNN,一个是Encoder,一个是Decoder。Encoder将一个句子作为输入序列,每一个时间片处理一个字符。Decoder通过Encoder生成的上下文向量,使用时间序列生成翻译(回答)内容。(达观数据 江永青)
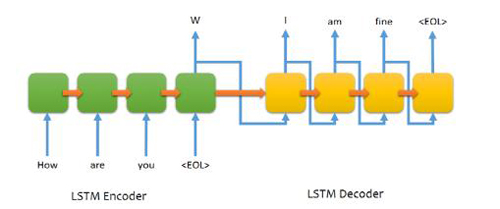
图5
在Encoder中,每一个隐藏的状态影响到下一个隐藏状态,并且***一个隐藏状态可以被认为是序列的总结信息。***这个状态代表了序列的意图,也就是序列的上下文。通过上下文信息,Decoder会生成另一个结果序列,每一个时间片段,根据上下文和之前生成的字符,Decoder都会生成一个翻译字符。
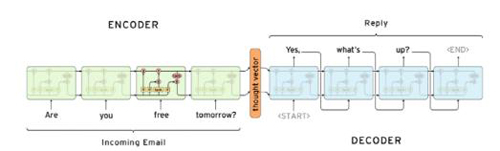
图6
这个模型有一些不足:首先是这个模型不能处理变长的字符序列,而一般的翻译模型和问答模型中的序列长度都是不定的。另外一个是仅通过一个context变量,并不足以完全表示输入序列的信息。在序列变得很长之后,大量的信息会被丢弃,因此需要多个context变量及注意力机制进行处理。
3.1 Padding
通过Padding方式,可以将问答字符串固定为定长的序列,比如使用如下几个序列进行Padding:
EOS : 序列的结束
PAD : Padding字符
GO : 开始Decode的字符
UNK : 不存在字典中的字符
对于问答对:
Q : 你过得怎样?
A : 过得很好。
通过padding将生成固定的如下字符串:
Q : [ PAD, PAD, PAD, PAD, “?”, “样”, “怎”, “得”, “过”, “你” ]
A : [ GO, “过”, “得”, “很”, “好”, “。”, PAD, EOS, PAD, PAD ]
3.2 注意力机制
Seq2Seq的一个限制是输入序列的所有信息只能编码到一个定长的数组context里,如果输入序列变长的话,我们很容易会丢失信息,因此Seq2Seq模型对长输入序列效果很差。通过引入一个注意力机制,可以让Decoder在翻译(回答)时按权重选择性地提取输入的各个隐层变量进行计算,这样就能在产生输出时考虑到输入的关键信息了。
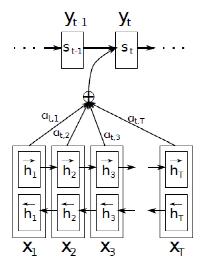
图7
如图中,每个输入的状态yi除了与前一个状态yi-1,输入的隐藏状态si有关之外,还与注意力向量ci有关。

这里的注意力向量不再是单独的一个c,而是对于每一个输入yi都有对应的ci,它的计算方式如下:
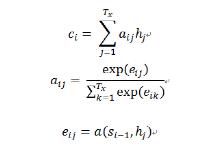
eij是一个对准模型,它计算了位置为i的输入和位置为j的输出之间关系的比重。它通过输出的隐藏状态si – 1(用来计算si及输出状态yi)和输入序列的第j个隐藏变量hj计算而得。
通过将问答对以翻译模型进行训练(问题作为原语言,答案作为目标语言),在新来一个问题时,可以在没有任何历史相似问题的情况下得到较接近的答案。然而因为目前的翻译模型还不够成熟,经常翻译出莫名奇妙的答案,让人摸不着头脑,如下所示:
你好->你好
很高兴认识你->我也是
你是谁->我是说,我们是朋友
我们是朋友吗->不是
我们为什么不是朋友->我们不知道,我们都不知道你们在哪里
达观数据很厉害->我们知道
通过产生式的翻译模型,即使基于大量的语料训练,很有可能效果还是不够理想,因此经常作为基于规则和检索的问答系统的辅助方式。
4. 小结
本文介绍了智能问答技术的相关原理,讲述了实现智能问答的一般方法。借助于深度学习技术,智能问答效果比传统机器学习提升20%左右。达观数据拥有多年的自然语言处理技术积累,并且紧跟行业潮流,在文本语义、信息检索、智能问答方面不断深耕,助力各个企业享受大数据技术的成果。
【本文为51CTO专栏作者“达观数据”的原创稿件,转载可通过51CTO专栏获取联系】




















