什么是PAI?
PAI的全称是Platform of Artificial Intelligence,主要在使用机器学习做模型训练时提供整套链路。机器学习即服务,把机器学习作为服务对外推出,大家可以在平台上使用比较先进的机器学习算法。将多种深度学习框架集成到PAI中,同时基于深度学习框架包装成更加易用的组件。具备异构的计算服务能力,把CPU计算能力和GPU计算能力统一调度起来,异构的计算能力透明,大家的注意力是哪些机器学习算法可以帮助业务,不用关心底层资源的申请和分配。PAI也支持在线预测服务,模型一键发布。
大规模分布式机器学习的挑战
数据规模和特征会不断增加,这就会导致模型复杂度的增加,之前的模型已经不能够处理这么高的复杂度了。特征增加之后,模型变得越来越大,模型很难做到单机加载,所以在模型存储时需要做分片和切分。在常规的机器学习里面,更多的注意力放在理解业务的数据、特征,而现在的注意力会转移到模型本身,更多考虑怎么通过调整模型的结构达到更好的预测效果。
编程模型演进
MapReduce编程模型
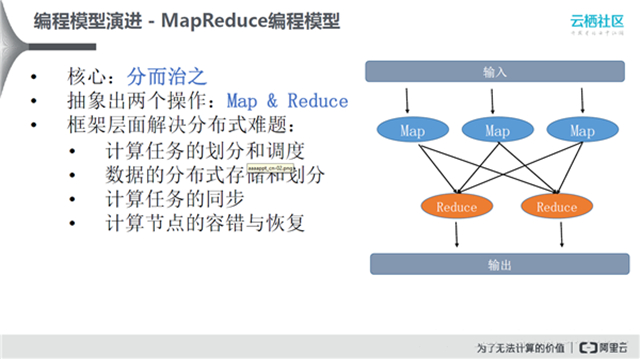
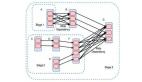
MapReduce核心的思想是分而治之,即把数据切分成很多块,每个节点处理其中的一小块。做分布式系统时会面临很多问题,比如希望计算任务可以在MapReduce框架层面做切分和调度。MapReduce从框架层面极大地降低了把任务迁移到分布式计算系统上的难度和门槛。对于数据的分布式存储和划分,数据可分散存储在几千台机器上,并且都有相应副本,不需要担心数据的丢失,底层的分布式存储会统一进行处理。计算任务的同步和计算节点的容错与恢复,若使用普通机器去搭大型计算群的时候,机器的宕机时比较普遍的现象,使用MapReduce则不需要关心这一点。右图是MapReduce的编程模型,最初是用来处理SQL等问题。
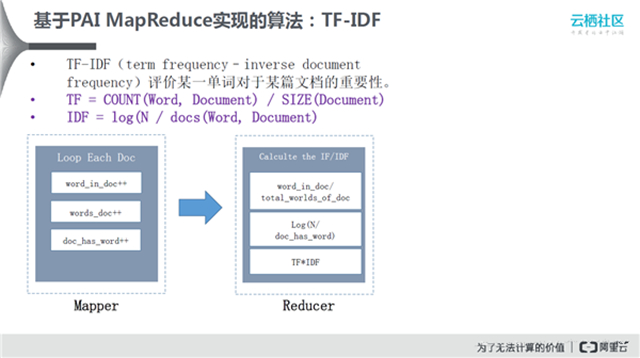
在机器学习里面,有些算法是基于MapReduce编程模型去实现的。TF-IDF用来评估文档里面单词是否能表示文档主题。首先计算文档里面单词出现的频率,把谓词和叹词去掉,关注真正有意义的词。IDF则是统计该词在所有文档里面出现的频率,将其和文档里出现的频率经过算法计算得出最终结果。这个过程如何通过MapReduce实现呢?在Mapper中迭代的去加载每一篇要训练的文章,在迭代过程中统计每个单词出现的频率。将统计结果放入Reducer中,进行计算,得到TF-IDF结果表。
MapReduce编程模型有两个特点:不同计算任务之间独立,每个Mapper和Reducer只会计算自己相关的数据,数据并行度高;适合不需要不同节点通信的机器学习算法。
MPI编程模型

逻辑回归算法是需要节点间进行通信的,该算法在个性化推荐中可以经常看到。个性化推荐算法是指每个人点击进来之后会进行分类,判断是否会对某些商品感兴趣,然后进行推荐。模型函数如上图中公式所示,定义损失函数,损失函数值越小说明模型拟合越好,寻找损失函数最小值的过程中用到了梯度下降算法。
早期,很多逻辑回归算法都是基于MPI编程模型实现的,MPI是消息传递接口,定义了Send,Receive,BC阿斯图,AllReduce接口,支持单机多Instance和多机多Instance,具有高度灵活,描述能力强,大量用于科学计算。
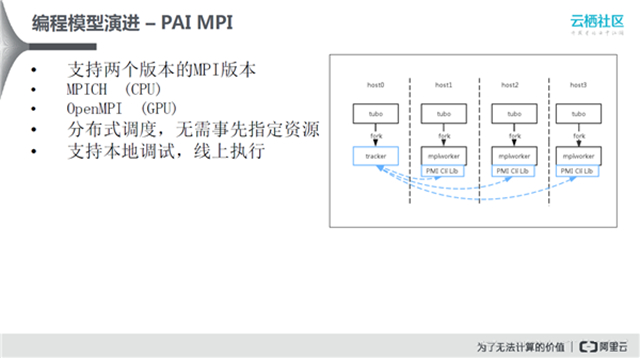
MPI使用时有很多限制,首先必须提前知道阶段任务在哪些计算节点上做。在大规模的计算集群里面,所有资源的分配都是动态的,在任务执行之前不知道任务会调度到哪些节点上,但是早期有很多算法需要基于MPI实现,所以对MPI底层做了网络拓扑的建立,做了大量的重构,帮助MPI相关程序能够基于分布式的调度系统调度起来。
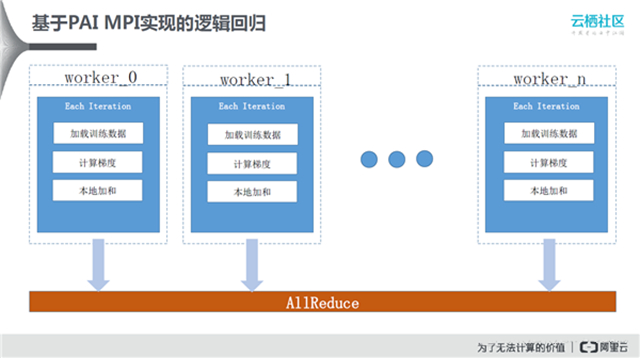
逻辑回归的实现过程如上图所示。其中,有n个计算节点,首先会加载训练样本,计算梯度,然后本地加和,最后调用AllReduce接口去计算现在模型所在的位置。MPI本身还存在一些缺点:首先MPI中Worker的数目有上限,当需要更多节点的时候会发生性能下降。
参数服务器Parameter Server
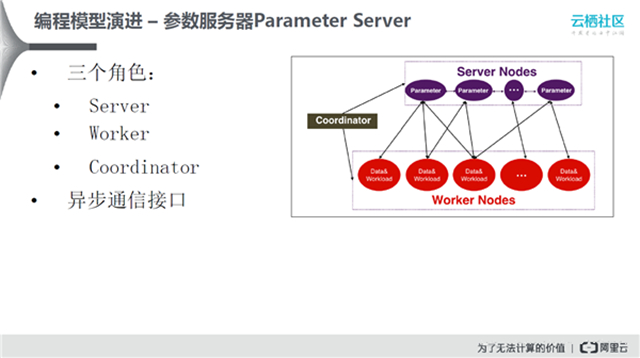
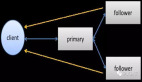
Parameter Server和MPI相比,在更高的层次定义了编程模型和接口。Parameter Server中有三个角色,Server节点用来存储模型,计算节点会加载部分模型、训练数据,每轮迭代时每个节点会计算下个梯度,将节点和Server进行通信。Coordinator用来判断训练是否结束。此外,Parameter Server支持异步通信接口,不需要在不同计算节点间做同步。
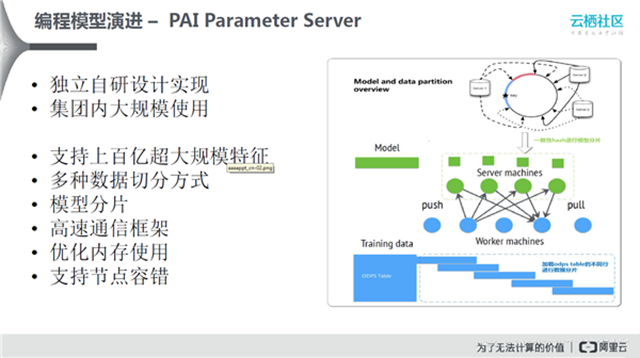
阿里在2014年下半年,独立自研了PAI Parameter Server计算模型,已在集团内大规模使用。具体做的工作如上图所示。MPI的一个缺点是不支持容错,而每天上万台的集群会出现各种各样的故障,PAI Parameter Server针对大规模集群做了节点容错功能。Parameter Server集成很多算法,比如逻辑回归等。
深度学习
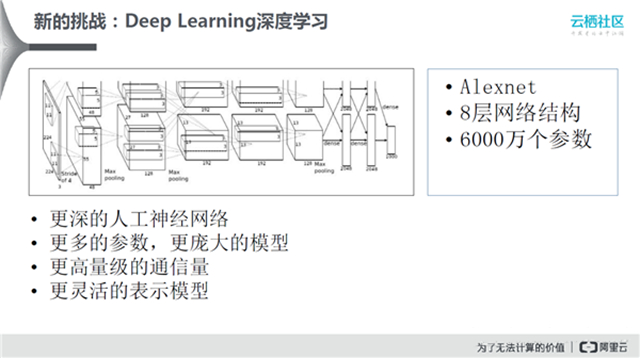
深度学习是人工神经网络的延伸,相比之下能够支持更深的网络。上图中,Alexnet是卷积神经网络,总共有8层网络,深度学习如果想要获得更好的效果,必须要构建一个更深的神经网络。随着神经网络变深,需要更多的参数,并且模型也会更加庞大。多级训练则需要更高量级的通信量。
TensorFlow

TensorFlow是谷歌第二代的深度学习框架,支持各种神经网络,具有高度的灵活性,丰富的社区生态,支持CNN、RNN、LSTM等网络。
上图中TensorFlow的例子是两层神经网络做图片的分类。上面通过API定义训练图片和测试数据,接着定义了模型(softmax多分类模型),定义损失函数通过交叉熵来做,最后选择优化函数找最优点。下面部分则是通过API把训练数据喂给模型再计算当前模型的准确率。从上例中,可以看出,API非常灵活,基于Python,所以非常方便。
PAI TensorFlow
将TensorFlow迁移到PAI上之后,将TensorFlow作业服务化,起TensorFlow作业的时候不需要去申请资源、做训练数据的迁移;分布式调度(包括单机和多机)只需提交模型训练Python文件;GPU卡映射;多种数据源,结构化数据和非结构化数据都支持;超参支持,训练模型时会调整学习率,通过超参把参数存进来就不需要每次都调整了;模型在线预测,训练好模型之后可以部署到在线预测服务上,调用API获知模型结果是否正面。
PAI Pluto(多机多卡Caffe)

Caffe早于TensorFlow,Caffe可以认为是第一代的深度学习框架,使用Caffe时需要通过配置文件配置深度学习的卷积神经网路。目前,很多关于图像的应用都是基于Caffe来做的,使用CNN的网络,比如身份证识别、驾照识别等。其缺点是单机,当训练样本多的时候训练时间非常长。将Caffe底层嫁接到OpenMPI通信框架上,可以支持多机Caffe,能够达到线性加速比。
总结
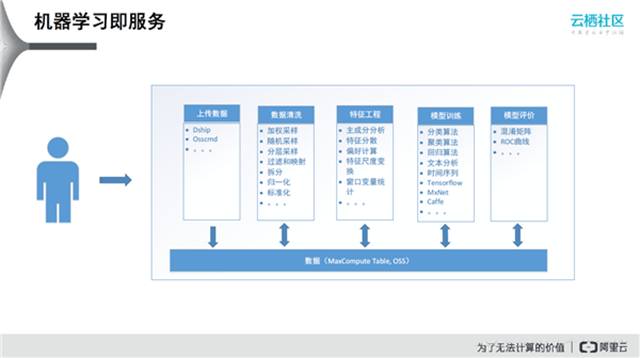
前文提到了PAI上支持的各种编程模型,在公有云上希望把机器学习作为一个服务推出来,包括数据上传、数据清洗、特征工程、模型训练、模型评价。这样就可以在PAI上做一站式的模型训练和预测。