目标读者
知道逻辑回归是什么,懂一点 Python,听说过 TensorFlow
数据集
来自 Coursera 上 Andrew 的机器学习课程中的ex2data1.txt,根据学生的两次考试成绩判断该学生是否会被录取。
环境
Python 2.7 - 3.x
pandas, matplotlib, numpy
安装 TensorFlow
在自己的电脑上安装 TensorFlow 框架,安装方法过程不赘述,CPU 版相对更容易一点,GPU 版需要 CUDA 支持,各位看官看情况安装就好。
开始
创建一个文件夹(比如就叫做tensorflow),在文件夹中创建一个 Python 文件main.py,并将数据集文件放到这个文件夹下:
数据形式:
前两列分别为两次考试成绩(x1, x2),***一列为是否被录取(y),1代表被录取,0则反之。
在源文件main.py中,我们首先引入需要的包:
import pandas as pd # 用于读取数据文件
import tensorflow as tf
import matplotlib.pyplot as plt # 用于画图
import numpy as np # 用于后续计算- 1.
- 2.
- 3.
- 4.
pandas是一个数据处理相关的包,可以对数据集进行读取和其他各种操作;matplotlib可以用来把我们的数据集绘成图表展示出来。
接着我们将数据集文件读入程序,用于后面的训练:
# 读取数据文件
df = pd.read_csv("ex2data1.txt", header=None)
train_data = df.values- 1.
- 2.
- 3.
pandas函数read_csv可以将 csv(comma-separated values)文件中的数据读入df变量,通过df.values将 DataFrame 转化为二维数组:
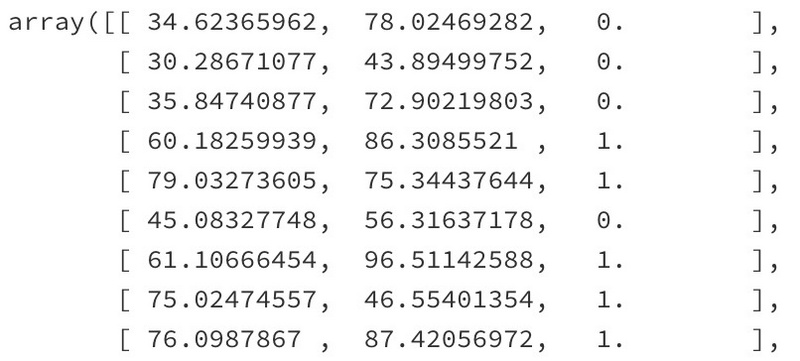
有了数据之后,我们需要将特征(x1, x2)和标签(y)分别放到两个变量中,以便在训练中代入公式:
# 分离特征和标签,并获取数据维数
train_X = train_data[:, :-1]
train_y = train_data[:, -1:]
feature_num = len(train_X[0])
sample_num = len(train_X)
print("Size of train_X: {}x{}".format(sample_num, feature_num))
print("Size of train_y: {}x{}".format(len(train_y), len(train_y[0])))- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
可以看到,我们的数据集中有100条样例,每条样例的特征数量为2。
TensorFlow 模型设计
在逻辑回归中,我们使用的预测函数(Hypothesis)为:
其中,sigmoid是一个激活函数,在这里表示学生被录取的概率:
这个函数的形状请自行百度
W 和 b 是我们接下来的学习目标,W 为权值矩阵(Weights),b 为偏置量(Bias,体现在图像上又叫截距)。
我们使用的损失函数为:
由于我们的数据集只有两个特征,因此不用担心过拟合,所以损失函数里的正规化项就不要了😌。
首先我们用 TensorFlow 定义两个变量用来存放我们的训练用数据:
# 数据集
X = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)- 1.
- 2.
- 3.
这里的X和y不是一般的变量,而是一个 placeholder(占位符),意味着这两个变量的值是未指定的,直到你开始训练模型时才需要将给定的数据赋值给变量。
接着我们再定义出我们要训练的 W 和 b:
# 训练目标
W = tf.Variable(tf.zeros([feature_num, 1]))
b = tf.Variable([-.9])- 1.
- 2.
- 3.
这里他们的类型为 Variable(变量),意味着这两个变量将在训练迭代的过程中不断地变化,最终取得我们期望的值。可以看到,我们将 W 的初始值设为了 feature_num 维的0向量,将 b 初始值设为了 -0.9(随便设的,不要介意😶)
接下来我们要用 TensorFlow 的方式将损失函数表达出来:
db = tf.matmul(X, tf.reshape(W, [-1, 1])) + b
hyp = tf.sigmoid(db)
cost0 = y * tf.log(hyp)
cost1 = (1 - y) * tf.log(1 - hyp)
cost = (cost0 + cost1) / -sample_num
loss = tf.reduce_sum(cost)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
可以看到,我表达损失函数是分三步进行的:先分别将求和内的两部分表示出来,再将它们加和并和外面的常数m进行运算,***对这个向量进行求和,便得到了损失函数的值。
接下来,我们要定义使用的优化方法:
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)- 1.
- 2.
其中,***步是选取优化器,这里我们选择梯度下降方法;第二步是优化目标,从函数名字顾名思义,我们的优化目标是使得损失函数的值最小化。
注意:此处的学习率(0.001)应当尽可能小,否则可能会出现损失计算中出现 log(0)的问题。
训练
上面的工作做完之后,我们就可以开始训练我们的模型了。
在 TensorFlow 中,首先要将之前定义的Variable初始化:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)- 1.
- 2.
- 3.
在这里,我们看到出现了一个tf.Session(),顾名思义是会话,即任务执行的主体。我们上面定义了一堆东西,只是一个模型为了得到结果而需要的执行步骤和框架,一个类似流程图的东西,光有流程图还不够,我们需要一个主体来实际地运行它,这就是Session的作用。
----------特别提示----------
如果你是使用 GPU 版 TensorFlow 的话,并且你想在显卡高占用率的情况下(比如玩游戏)训练模型,那你要注意在初始化 Session 的时候为其分配固定数量的显存,否则可能会在开始训练的时候直接报错退出:
2017-06-27 20:39:21.955486: E c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\35\tensorflow\stream_executor\cuda\cuda_blas.cc:365] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
Traceback (most recent call last):
File "C:\Users\DYZ\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py", line 1139, in _do_call
return fn(*args)
File "C:\Users\DYZ\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py", line 1121, in _run_fn
status, run_metadata)
File "C:\Users\DYZ\Anaconda3\envs\tensorflow\lib\contextlib.py", line 66, in __exit__
next(self.gen)
File "C:\Users\DYZ\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\errors_impl.py", line 466, in raise_exception_on_not_ok_status
pywrap_tensorflow.TF_GetCode(status))
tensorflow.python.framework.errors_impl.InternalError: Blas GEMV launch failed: m=2, n=100
[[Node: MatMul = MatMul[T=DT_FLOAT, transpose_a=false, transpose_b=false, _device="/job:localhost/replica:0/task:0/gpu:0"](_arg_Placeholder_0_0/_3, Reshape)]]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
这时你需要用下面的方法创建 Session:
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))- 1.
- 2.
这里的0.333就是占你总显存的份额。
----------End 特别提示----------
下面就是用我们的数据集来对模型进行训练了:
feed_dict = {X: train_X, y: train_y}
for step in range(1000000):
sess.run(train, {X: train_X, y: train_y})
if step % 100 == 0:
print(step, sess.run(W).flatten(), sess.run(b).flatten())- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
首先讲要传入的数据存放到一个变量中,在训练模型时传入 sess.run();我们进行 10000 次训练,每隔 100
次输出一次当前的目标参数 W, b。
到这里,训练代码的部分就完成了,你可以使用你自己的 python 命令来运行了。如果你严格按照上面的代码做了,不出现错误,你现在应该可以看到控制台里已经开始不断输出训练状态了:
图形化表示结果
当训练结束后,你可以得到一个 W,和一个 b,这样我们可以将数据集和拟合的结果通过图表直观地展现出来。
就在写作的过程中,我用上面的代码训练出了一个结果:

我们将其直接写入代码,即:
w = [0.12888144, 0.12310864]
b = -15.47322273- 1.
- 2.
下面我们先将数据集表示在图表上(x1为横轴,x2为纵轴):
x1 = train_data[:, 0]
x2 = train_data[:, 1]
y = train_data[:, -1:]
for x1p, x2p, yp in zip(x1, x2, y):
if yp == 0:
plt.scatter(x1p, x2p, marker='x', c='r')
else:
plt.scatter(x1p, x2p, marker='o', c='g')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
其中,我们用 红色的x 代表 没有被录取,用 绿色的o 代表 被录取。
其次我们将训练得出的决策边界 XW + b = 0 表示到图表上:
# 根据参数得到直线
x = np.linspace(20, 100, 10)
y = []
for i in x:
y.append((i * -w[1] - b) / w[0])
plt.plot(x, y)
plt.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
此时,如果你的代码没错的话,再次运行,你将得到如下结果:
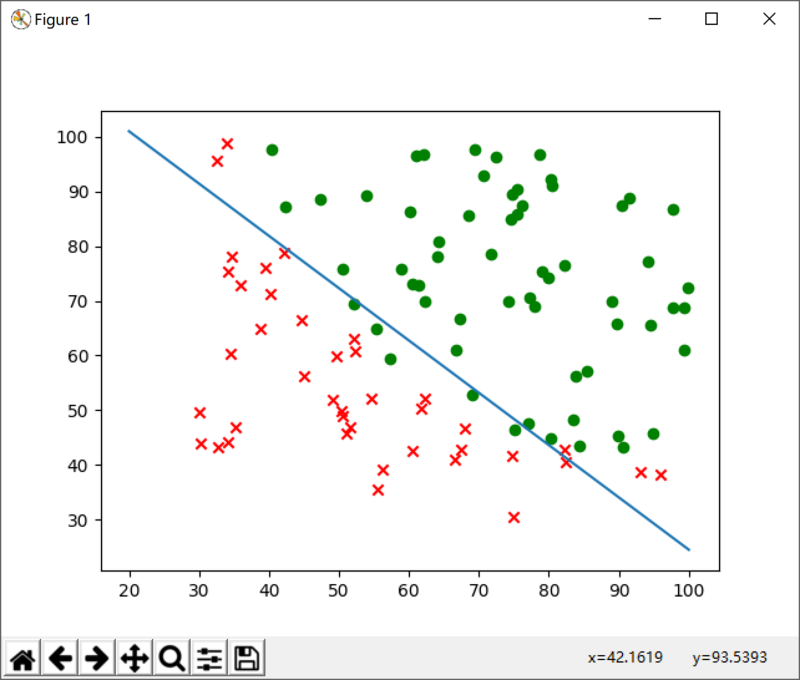
可以看到,我们通过训练得出的参数划出一条直线,非常合适地将两种不同的数据样例区分开来。
到此,一个完整的简单的逻辑回归模型就实现完毕了,希望通过这篇文章,能让各位看官对在 TensorFlow 中机器学习模型的实现有一个初步的了解。本人也在初步学习当中,如有不当之处欢迎在评论区拍砖,在实现以上代码的过程中如果遇到什么问题也请在评论区随意开火。