当你想对两个表进行差分运算时,你有两种选择:使用NOT EXISTS 的子查询或者NOT IN 。后者可以说更易于编写,可以使查询方法更加明显。现代数据库系统可以优化两种执行计划从而查询到类似的结果,可以在外部和内部处理查询的相关性(我说“现代”,因为在上世纪90年代中期我已经吸取教训,当时我正在使用Oracle 7.3,它没有这个功能)。
两种结构有一个很大的不同:如果子查询返回的结果为NULL,那么 NOT IN 的条件将不执行,因为 NULL不等于它或不等于其它值。但是如果你注意到这一点,它们是等价的。事实上,这些消息告诉我们,NOT IN 查询更快,人们更喜欢用它查询。
这篇文章是关于一个数据库显著变慢的情况,而空值正是罪魁祸首。
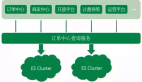
考虑以下两个可能是用来追踪点击流数据的表。由于我们跟踪匿名和注册用户, EVENTS.USER_ID是可空的。然而,当用户不空,二级指标标就会具有较高的基数。
create table USERS
(
ID integer auto_increment primary key,
...
)
create table EVENTS
(
ID integer auto_increment primary key,
TYPE smallint not null,
USER_ID integer
...
)
create index EVENTS_USER_IDX on EVENTS(USER_ID);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
好的,现在让我们使用这些表:从一小部分用户开始,我们想找到那些没有特定事件的用户。 使用NOT IN子句,并确保null值不出现在内部结果中,查询如下所示:
select ID
from USERS
where ID in (1, 7, 2431, 87142, 32768)
and ID not in
(
select USER_ID
from EVENTS
where TYPE = 7
and USER_ID is not null
);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
对于我的测试数据集,USERS表有100,000行,EVENTS表有10,000,000行,并且EVENTS表中大约75%的USER_ID为空。 我在我的笔记本电脑上运行这条查询,它有一个Core i7处理器,12 GB的RAM和一个SSD。
我一直运行了约2分钟,这真是...哇。
让我们用NOT EXISTS和相关的子句替换NOT IN:
select ID
from USERS
where ID in (1, 7, 2431, 87142, 32768)
and not exists
(
select 1
from EVENTS
where USER_ID = USERS.ID
and TYPE = 7
);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
这个版本运行在0.01秒,这比我预期的时间更短。
是时候比较一下执行计划了。 ***个计划来自NOT IN查询,第二个来自NOT EXISTS。
+----+--------------------+--------+------------+----------------+-----------------+-----------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+--------+------------+----------------+-----------------+-----------------+---------+------+------+----------+--------------------------+
| 1 | PRIMARY | USERS | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 5 | 100.00 | Using where; Using index |
| 2 | DEPENDENT SUBQUERY | EVENTS | NULL | index_subquery | EVENTS_USER_IDX | EVENTS_USER_IDX | 5 | func | 195 | 10.00 | Using where |
+----+--------------------+--------+------------+----------------+-----------------+-----------------+---------+------+------+----------+--------------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
执行计划几乎相同:都是从USERS表中选择行,然后使用嵌套循环连接(“DEPENDENT SUBQUERY”)从EVENTS表中检索行。都声称使用EVENTS_USER_IDX在子查询中选择行。并且他们在每一步都估计了相似的行数。
但更仔细地查看连接类型。 NOT IN版本使用 index_subquery,而NOT EXISTS版本使用 ref。再查看ref列:NOT EXISTS版本使用了对其它列的显式引用,而NOT IN使用了一个函数。这里发生了什么?
index_subquery连接类型表示MySQL将扫描索引以查找子查询的相关行。可能是这个问题吗?我不这么认为,因为EVENTS_USER_IDX索引是“narrow”类型:它只有一列,所以引擎不应该读取大量的块来查找对应的外部查询的ID行(的确,我尝试了各种查询来测试这个索引,并且所有的运行都在几百分之一秒内)。
为了获取更多信息,我转向使用“extended”执行计划。 要查看此计划,请使用explain extended作为查询前缀,并接着使用 show warnings得到被MySQL优化器优化后的查询语句。 这是从NOT IN查询得到的(为了清晰重新格式化了):
/* select#1 */ select `example`.`USERS`.`ID` AS `ID`
from `example`.`USERS`
where ((`example`.`USERS`.`ID` in (1,7,2431,87142,32768))
and (not(
(`example`.`USERS`.`ID`,
(
(
(`example`.`USERS`.`ID`) in EVENTS on EVENTS_USER_IDX checking NULL where ((`example`.`EVENTS`.`TYPE` = 7) and (`example`.`EVENTS`.`USER_ID` is not null)) having
(`example`.`EVENTS`.`USER_ID`)))))))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
我找不到“on EVENTS_USER_IDX checking NULL”的解释,但我认为发生的是:优化器认为它正在执行一个IN查询,可以在结果中包含NULL; 在做出此决定时,它不考虑where子句中的空检查。 因此,它将检查(examine)USER_ID为null的750万行,以及与外部查询的值匹配的几十行。 通过“检查(examine)”,我的意思是它将读取表行,然后应用不为null条件。 此外,基于运行查询所花费的时间,我认为它为外部查询中的每个候选值执行了此操作。
所以,本文的论点是:每当你想在可为空的列上使用IN或NOT IN子查询时,请重新思考并使用EXISTS或NOT EXISTS代替。