1、对mysql数据进行备份,常见的方式如以下三种,可能有很多人对备份时数据一致性并不清楚1、直接拷贝整个数据目录下的所有文件到新的机器。优点是简单、快速,只需要拷贝;缺点也很明显,在整个备份过程中新机器处于完全不可用的状态,且目的无法释放源数据文件中因为碎片导致的空间浪费和无法回收已发生扩展的innodb表空间。
2、用xtrabackup进行热备。优点是备份过程中可继续提供服务;缺点和***种方法差不多,目的分区无法释放源数据文件中因为碎片导致的空间浪费和无法回收已发生扩展的innodb表空间。
3、使用官方自带的mysqldump逻辑重做。优点是在整个备份过程中可以向外提供服务,最重要的一点是可以解决碎片浪费。
以上几种方法相信大家也都很熟悉,就不再详细介绍。下面主要讲解一下mysqldump备份时如何保持数据的一致性。mysqldump对不同类型的存储引擎,内部实现也不一样。主要是针对两种类型的存储引擎:支持事务的存储引擎(如InnoDB)和不支持事务的存储引擎(如MyISAM),下面分别看看这两种存储引擎的实现:
1、对于支持事务的引擎如InnoDB,参数上是在备份的时候加上--single-transaction保证数据一致性
--single-transaction实际上通过做了下面两个操作:
①、在开始的时候把该session的事务隔离级别设置成repeatable read;
②、然后启动一个事务(执行bigin),备份结束的时候结束该事务(执行commit)
有了这两个操作,在备份过程中,该session读到的数据都是启动备份时的数据(同一个点)。可以理解为对于innodb引擎来说加了该参数,备份开始时就已经把要备份的数据定下来了,备份过程中的提交的事务时是看不到的,也不会备份进去。
2、对于不支持事务的引擎如MyISAM,只能通过锁表来保证数据一致性,这里分三种情况:
①、导出全库:加--lock-all-tables参数,这会在备份开始的时候启动一个全局读锁(执行flush tables with read lock),其他session可以读取但不能更新数据,备份过程中数据没有变化,所以最终得到的数据肯定是完全一致的;
②、导出单个库:加--lock-tables参数,这会在备份开始的时候锁该库的所有表,其他session可以读但不能更新该库的所有表,该库的数据一致;
③、导出单个表:加--lock-tables参数,这会在备份开始的时候锁该表,其他表不受影响,该表数据一致。
上面只是展示了对不同引擎来讲加的参数只是为了让数据保持一致性,但在备份中业务并没有停止,时刻可能有新的数据进行写入,为了让我们知道备份时是备份了哪些数据,或者截止到那个指针(二进制日志),我们可以再加入 --master-data参数,备份好的sql文件就会记录从备份截至到哪个指针,指针之后的数据更新我们可以通过二进制日志进行恢复。
- # mysqldump -u root -p --single-transaction --master-data --flush-log --database test > test.sql
- --> --flush-log 表示备份开始之后的更行都切到下一个二进制日志
可以在备份的test.sql文件中前几行看到记录着备份当时的二进制日志信息
- # vim test.sql
- --
- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=436263492;
- --
- -- Current Database: `test`
- .....
- # mysqlbinlog --start-position=436263492 mysql-bin.000004 > 00004.sql
- -->在全备恢复之后,我们可以通过之后的二进制日志进行恢复
另外解释下mysqldump备份时为什么要锁表才能保持数据的一致性:
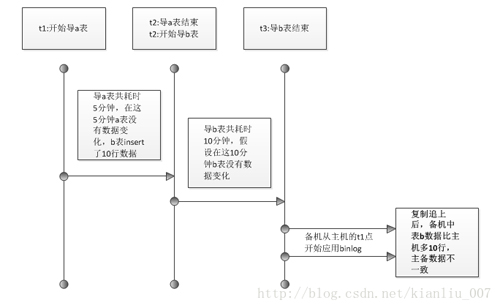
说明:
1、在t1时间点,用mysqldump启动不锁表备份;
2、先导出a表,共耗时5分钟,因为没有锁表,在这5分钟内b表insert了10行数据;
3、到了t2时间点,a表导出完成,开始导出b表;
4、导出b表耗时10分钟,在导出b表的过程中,a、b表均没有数据变化;
5、到了t3时间点,b表导出完成,全部备份结束;
6、然后备机从t1时间点的binlog位置开始应用binlog,***备机中b表的数据比主机多10行,数据不一致。
从这个图可以看出,对于不支持事务的存储引擎如MyISAM如果备份过程中不锁表,不同表开始备份时对应的binlog和pos是不一致的,这时候所有表都从备份开始的点应用binlog,有很大肯会出现数据不一致(备份过程中所有表均无数据更新除外)。