今天要给大家分享的内容和 YGC(Young GC)有关,是我最近碰到的一个案例,希望将排查思路分享给大家,如果大家后面碰到类似的问题,可以直接作为一个经验来排查。
我之前里写过几篇 YGC 的文章,也许其中有人已经看过了,没看过的可以去看看,那两个坑在这里就不再描述,大家可以直接当经验使用。
Java 堆分为新生代和老生代,YGC 其实就是针对新生代的垃圾回收,对象都是优先在新生代分配的,因此当新生代内存不够分配的时候就会触发垃圾回收,正常情况下可能触发一次 YGC 就可以解决问题并正常分配的,当然也有极端情况可能要进行大扫除,对整个堆进行回收,也就是我们说的 Full GC,这种情况发生就会比较悲剧了。
这里再提一下,YGC 也是会 STW(stop the world) 的,也就是会暂停整个应用,不要觉得 YGC 发生频繁不是问题。
说实话我比较不喜欢排查 YGC 的问题,因为 YGC 的日志太简单了,正常情况下只能知道新生代内存从多少变到了多少,花了多长时间,再无其它信息了。
所以当有人来咨询为什么我的程序 YGC 越来越长的问题的时候,我其实是抗拒的,不过也无奈,总得尝试去帮人家解决,包括前面说的那两个问题,也是费了不少精力查出来的,希望大家珍惜。。。
有些时候你越想逃避,偏偏就会找上你,YGC 的问题最近说实话找我的挺多的,不过有好些都是踩过的坑,所以能顺利帮人家解决,但是今天要说的这个问题是之前从未碰到过的,是一个全新的问题,所以也费了我不少精力,也因为其他问题要查被拖延了几天。
这个问题最终排查下来其实是 JVM 本身设计上面的一个缺陷,我改天也会提到 openjdk 社区去和大家一起讨论下这个设计,希望能彻底***这个问题。
这个问题现象也很明显,就是发现 YGC 的时间越来越长,从 20ms 慢慢增加到100ms+,甚至还一直在涨。
不过这个增长过程还是挺缓慢的,其实 YGC 时间在几十毫秒我个人认为算正常现象,没必要去深究,再说了还是经过压测了一个晚上才涨上来的,所以平时应该也不是啥问题吧,不过这次正巧赶上年中大促,所以大家对时间也比较敏感,便接手来排查这个案例了。
首先排除了之前碰到的几种情况,然后我要同事加了一个我们 alijdk 特定的参数,可以打印 YGC 过程里具体各个阶段的耗时情况,可惜的是并没有找出问题,因为我们漏掉了一些点,导致没有直接定位出来。
于是我怀疑那些没跟踪到的逻辑,首先怀疑的就是引用这块的处理,所以叫同事加上了 -XX:+PrintReferenceGC 这个参数,这个参数会打印各种引用的处理时间,大概如下:

点击下面图片进入小程序查看PrintReferenceGC参数详情

从当时的那个日志里,我发现了一个现象,就是随着 YGC 时间的增长,JNI Weak Reference 的处理耗时也在不断增长,所以基本就定位到了 YGC 增长的直接原因。
JNI Weak Reference 到底是什么呢?大家都知道 Java 层面有各种引用,包括 SoftReference,WeakReference 等,其中 WeakReference 可以保证在 GC 的时候不会阻碍其引用对象的回收,同样的在 native 代码里,我们也可以做类似的事情,有个叫做 JNIHandles::make_weak_global 的方法来达到这样的效果。
于是我开始修改 JVM,尝试打印一些信息出来,不知道大家注意过,我们 dump 线程的时候,使用 jstack 命令,***一条输出里会看到类似 JNI global references: 328 的日志,这里其实就是打印了 JNI 里的两种全局引用总数,分别是 _global_handles 和 _weak_global_handles。
于是尝试将这两种情况分开来,看具体哪种有多少个,于是改了***个版本,从修改之后的输出来看,_global_handles 的引用个数基本稳定不变,但是 _weak_global_handles 的变化却比较明显。
至此也算佐证了 JNI Weak Reference的问题,于是我想再次修改 JVM,打印了这些 JNI Weak Reference 引用的具体对象是什么对象。
在每次我执行 jstack 时,就会顺带把那些对象都打印出来,当然那个时候是为了性能,毕竟程序还跑在线上,不敢动太大,比如要是大量输出日志不可控,那就麻烦了,所以就借助 jstack 来手动触发这个逻辑。
从输出来看,看到了大量的下面的内容:

于是询问同事是不是存在大量的 Java 对 JavaScript 的调用,被告知确实有使用,那问题点基本算定位到了,我马上要同事针对他们的用法写一个简单的 demo 出来复现下问题。
没想到很快就写好,而且真的很容易复现,大概逻辑如下:
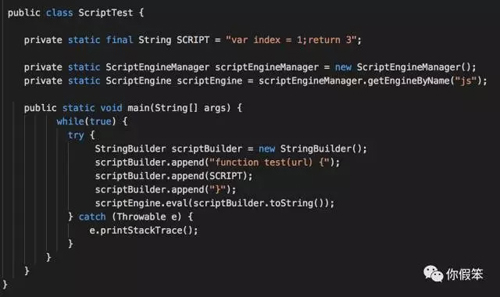
于是我开始 debug,最终确认和上面的 demo 完全等价于下面的 demo。
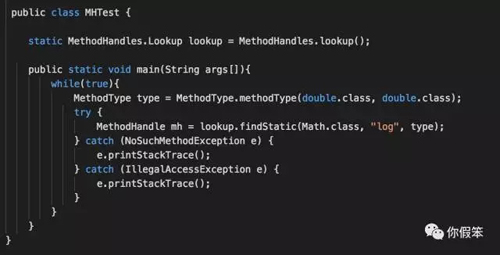
所以大家直接运行上面的 demo 就能复现问题,JVM 参数如下:
- -Xmx300M -Xms300M -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintReferenceGC
对了,运行平台是 JDK 8,JDK 6 是不存在这个问题的,因为 invokedynamic 指令以及 nashorn 是在 JDK 6 里不存在的。
上面的 demo 看起来是不是没毛病,但是却真的会让你的 GC 越来越慢,通过对 JVM 进行 debug 的方式抓出了下面的类似堆栈。
在 JDK 层面的栈如下:
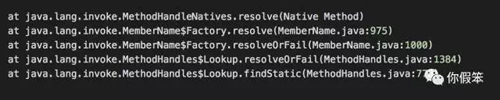
最上面的 resolve 方法是一个 native 方法,这个方法发现可以直接调用到上面提到的 JNIHandles::make_weak_global 方法。

JNIHandles::make_weak_global 方法其实就是创建了一个 JNI Weak Reference。
在这里我要稍微描述下了,因为太繁琐就不准备贴代码了。
JVM 里有个数据结构叫做 JNIHandleBlock,之前提到了 global_handles 和 _weak_global_handles,其实他们都是一个 JNIHandleBlock 链表。
可以想象下里面有个 next 字段链到下一个 JNIHandleBlock,同时里面还有一个数组 _handle[],长度是 32,当我们要分配一个 JNI Weak Reference 的时候,就相当于在这个 JNIHandleBlock 链表里找一个空闲的位置(就是那些 _handle 数组),如果发现每个 JNIHandleBlock 的 _handle 数组都满了,就会创建一个新的 JNIHandleBlock,然后加到链里,注意这个链可以***长,所以问题就来了,假如我们上层代码不断触发底层调用 JNIHandles::make_weak_global 来创建一个 JNI Weak Reference,那是不是意味着这个 JNIHandleBlock 链会不断增长,那会不会无穷增长呢,答案是肯定的,既然有创建 JNI Weak Reference 的 API,是不是也存在销毁 JNI Weak Reference 的 API?
当然是存在的,可以看到有 JNIHandles::destroy_weak_global 方法,这个实现其实很简单,就是相当于设计一个标记,表示这个数组里的这个位置是可以重用的了,在 GC 发生的时候,如果发现这个坑被标记了,于是就将这个坑加入到一个 free_list 里,当我们下面再想要分配一个 JNI Weak Reference 的时候,就可以有机会从 free_list 里去分配一个重用了。
但是这个 api 是在什么情况下才能调用的呢,其实只有在类卸载的时候才会去调用这个 api,那到底是什么类被卸载了,那就是调用了 MethodHandles.lookup() 这个方法的那个类,从我们上面的 demo 来看,就是 MHTest 这个主类本身,从同事给我的 demo 来看,其实是 jdk.nashorn.internal.runtime.Context 这个类,但是这个类其实是被 ext_classloader 加载的,也就是说这个类根本就不会被卸载,不能卸载那问题就严重了,意味着 GC 发生的时候并不能将那些引用对象已经死掉的坑置空,这样在我们需要再次分配 JNI Weak Reference 的时候,没有机会来重用那些坑,最终的结果就是不断地创建新的 JNIHandleBlock 加到链表里,导致链表越来越长,然而 GC 的时候是会去不断扫描这个链表的,因此看到 GC 的时候也会越来越长。
那还有一个问题,假如说调用 MethodHandles.lookup() 的类真的被卸载了还存在这个问题吗,答案是 GC 时间不会再恶化了,但是之前已经达到的恶化结果已经无法再修复了。
所以,这算是一个 JVM 设计上的缺陷吧,只要 Java 层面能触发不断调用到JNIHandles::make_weak_global,那这个问题将会立马重现。
其实解决方案我也想了一个,就是在遍历这些 JNIHandleBlock 的时候,如果发现对应的_handle数组全是空的话,那就直接将 JNIHandleBlock 回收掉,这样在 GC 发生的过程中并不会扫描到很多的 JNIHandleBlock 而耗时掉。
至于同事的那个问题的解决方案,其实也简单,对于同一个 JavaScript 脚本,不要每次都去调用 eval 方法,可以缓存起来,这样就减少了不断去触发调用 JNIHandles::make_weak_global 的动作从而可以避免 JNIHandleBlock 不断增长的问题。
【本文是51CTO专栏作者李嘉鹏的原创文章,转载请通过微信公众号(你假笨,id:lovestblog)联系作者本人获取授权】