近日,来自德国 Tubingen大学和Potsdam大学的研究人员们共同发布了一项研究成果——深度神经网络和人类视觉在信号变弱时进行物体识别的差异对比。这些专家分别来自神经信息处理、综合神经学、心理学与生物控制等不同领域。此项研究旨在对DNN和人类神经系统的结构和处理过程的差别作出相应解释,并且找到在信号变弱时两种视觉系统的分类错误模式的不同。
论文:Comparing deep neural networks against humans: object recognition when the signal gets weaker

论文链接:https://arxiv.org/pdf/1706.06969.pdf
摘要:人类视觉在进行物体识别时通常是很迅速的,而且似乎毫不费力,并且很大程度上与视角和面向对象无关。直到最近,动态视觉系统才有能力完成这一非凡的计算技能。这正是随着一类叫做深度神经网络(DNN)算法的出现而改变的,它在物体识别任务中已经可以达到人类级别的分类表现。而且,更多与 DNN 方法相类似的研究报告,还有人体视觉系统处理物体的进程,都表明现在的 DNN 可能就是人类视觉进行物体识别的良好模型。然而,***型的 DNN 和灵长类动物的视觉系统确实在结构和处理过程上还存在着明显的不同。这些不同的潜在的行为结果还不能得到充分的解释。我们的目标正是通过比较人类和 DNN 对图像降解(image degradations)的整合能力来解决这一问题。我们发现人类视觉系统对图像处理操作具有更好的鲁棒性,比如在反差衰(contrast reduction)、加性噪声(additive noise)或者新型的幻象失真(eidolon-distortions)这些方面。而且我们逐步地找到了在信号逐渐变弱时,人类和 DNN 进行分类时的错误方式的不同,这表明人类和现在的 DNN 在进行视觉物体识别(visual object recognition)时仍旧存在着很大差异。我们希望我们的发现,还有我们经过仔细测试而且可以自由使用的行为型数据集,可以给计算机视觉界提供一种新的且实用的基准,从而来增强 DNN 的鲁棒性,并且促使神经科学家去搜寻可以促进这种鲁棒性的大脑机制。

图 1
图 1.:实验原理图。在呈现出一个中央固定方块之后(300 ms),图像在 200ms 的情况下可视,紧接着是一个 1/f 频谱(200ms)的噪声屏蔽(noise-mask)。然后,在 1500ms 时出现一个响应屏,在这里观察者可以点击一个类别。注意我们在这张图中增强了噪声屏蔽的对比,这是为了在出版时拥有更好的可视性。从上到下的类别分别是:刀具,自行车,熊,卡车,飞机,表,船,小汽车,键盘,烤箱,猫,鸟,大象,椅子,瓶子,狗。这些图示是 MS COCO(http://mscoco.org/ explore/)版本的修改版。
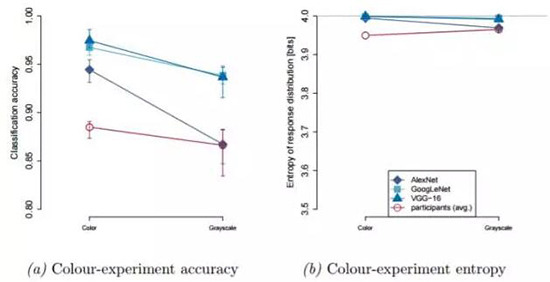
图 2
图 2: 颜色试验结果(n=3)。(a)精度。DNN 对应蓝色,人类对应红色;菱形对应 AlexNet,方形对应 GoogLeNet,三角是 VGG-16,圆圈是人类观察者。(b)响应分布熵(Response distribution entropy)。

图 3
图 3: 预估刺激信号(Estimated stimuli)对应 50% 分类精度。(a)噪声实验。(b)Eidolon 实验。连贯性参数=1.0。首行:刺激信号(stimuli)对应平均人类观察者的阈值(threshold)。底下三行:刺激信号对应 VGG-16(第二行), GoogLeNet(第三行)和 AlexNet(***一行)的相同精度。
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】