在我刚刚进入大学,从零开始学习 C 语言的时候,我就不断的从学长的口中听到一个又一个语言,比如 C++、Java、Python、JavaScript 这些大众的,也有 Lisp、Perl、Ruby 这些相对小众的。一般来说,当程序员讨论一门语言的时候,默认的上下文经常是:“用 xxx 语言来完成 xxx 任务”。所以一直困扰着的我的一个问题就是,为什么完成某个任务,一定要选择特定的语言,比如安卓开发是 Java,前端要用 JavaScript,iOS 开发使用 Objective-C 或者 Swift。这些问题的答案非常复杂,有的是技术原因,有的是历史原因,有的会考虑成本,很难得出统一的结论,只能 case-by-case 的分析。这篇文章并非专门解答上述问题,而是希望通过介绍一些通用的概念,帮助读者掌握分析问题的能力,如果这个概念在实际编程中用得到,我也会举一些具体的例子。
在阅读本文前,不妨思考一下这几个问题,如果没有头绪,建议看完文章以后再思考一遍。如果觉得答案显而易见,恭喜你,这篇文章并非为你准备的:
- 什么是编译器,它以什么为分界线,分为前端和后端?
- Java 是编译型语言还是解释型语言,Python 呢?
- C 语言的编译器也是 C 语言,那它怎么被编译的?
- 目标文件的格式是什么样的,段表、符号表、重定位表有什么作用?
- Swift 是静态语言,为什么还有运行时库?
- 什么是 ABI,ABI 不稳定有什么问题?
- 什么是 WebAssembly,为什么要推出这门技术,用 C++ 代替 JavaScript 可行么?
- JavaScript 和 DOM API 是什么关系,JavaScript 可以读写文件么?
- C++ 代码可以自动转换成 Java 代码么,任意两种语言是否可以互转?
- 为什么说 Python 是胶水语言,它可以用来开发 iOS/Android 么?
编译原理
就像数学是一个公理体系,从简单的公理就能推导出各种高阶公式一样,我们从最基本的 C 语言和编译说起。
- int main(void) {
- int a = strlen("Hello world"); // 字符串的长度是 11
- return 0;
- }
相关的介绍编译过程的文章很多,读者应该都非常熟悉了,整个流程包括预处理、词法分析、语法分析、生成中间代码,生成目标代码,汇编,链接 等。已有的文章大多分析了每一步的逻辑,但很少谈实现思路,我会尽量用简单的语言来描述每一步的实现思路,相信这样有助于加深记忆。由于主要谈的概念和思路,难免会有一些不够准确的抽象,读者学会抓重点就行。
预处理是一个独立的模块,它放在***介绍,我们先看词法分析。
词法分析
***登场的是编译器,它负责前五个步骤,也就是说编译器的输入是源代码,输出是中间代码。
编译器不能像人一样,一眼就看明白源代码的内容,它只能比较傻的逐个单词分析。词法分析要做的就是把源代码分割开,形成若干个单词。这个过程并不像想象的那么简单。比如举几个例子:
- int t 表示一个整数,而 intt 只是一个变量名。
- int a() 表示一个函数而非整数 a,int a () 也是一个函数。
- a = 没有具体价值,它可以是一个赋值语句,还可以是 a == 1 的前缀,表示一个判断。
词法分析的主要难点在于,前缀无法决定一个完整字符串的含义,通常需要看完整句以后才知道每个单词的具体含义。同时,C 语言的语法也不简单,各种关键字,括号,逗号,语法等等都会给词法分析的实现增加难度。
词法分析的主要实现原理是状态机,它逐个读取字符,然后根据读到的字符的特点转换状态。比如这是 GCC 的词法分析状态机(引用自《编译系统透视》):
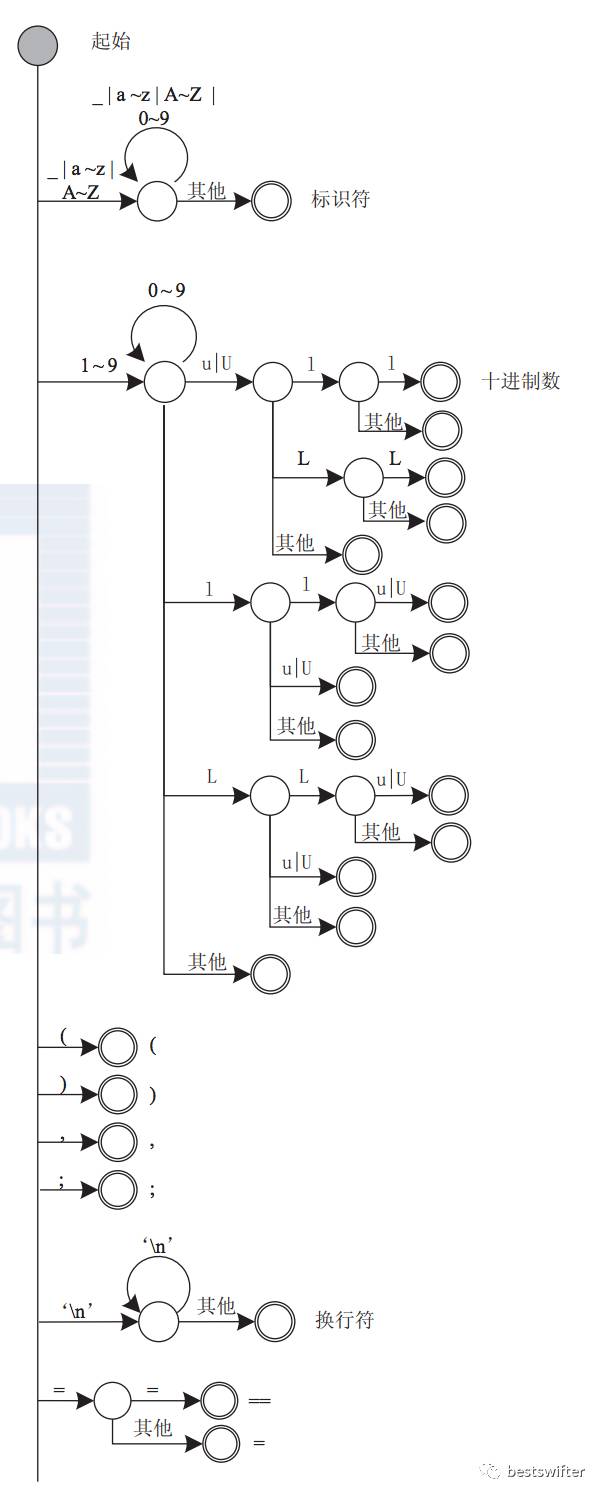
如果自己实现的话,思路也不难。外面包一个循环,然后各种 switch...case 就完事了。词法分析应该算是最简单的一节。
语法分析
经过词法分析以后,编译器已经知道了每个单词,但这些单词组合起来表示的语法还不清楚。一个简单的思路是模板匹配,比如有这样的语句:
- int a = 10;
它其实表示了这么一种通用的语法格式:
类型 变量名 = 常量;
所以 int a = 10; 当然可以匹配上这种模式。同理,它不可能匹配 类型 函数名(参数); 这种函数定义模式,因为两者结构不一致,等号无法被匹配。
语法分析比词法分析更复杂,因为所有 C 语言支持的语法特性都必须被语法分析器正确的匹配,这个难度比纯新手学习 C 语言语法难上很多倍。不过这个属于业务复杂性,无论采用哪种解决方案都不可避免,因为语法规则的数量就是这么多。
在匹配模式的时候,另一个问题在于上述的名词,比如 类型、参数,很难界定。比如int 是类型,long long 也是类型,unsigned long long 也是类型。(int a) 可以是参数,(int a, int b) 也是参数,(unsigned long long a, long long double b, int *p) 看起来能把人逼疯。
下面举一个简单的例子来解释 int a = 10 是如何被解析的,总的思路是归纳与分解。我们把一个复杂的式子分割成若干部分,然后分析各个部分,这样可以简化复杂度。对于 int a = 10 来说,他是一个声明,声明由两部分组成,分别是声明说明符和初始声明符列表。
| 声明 | 声明说明符 | 初始声明符列表 |
|---|---|---|
| int a = 10 | int | a = 10 |
| int fun(int a) | int | fun(int a) |
| int array[5] | int | array[5] |
声明说明符比较简单,它其实是若干个类型的串联:
声明说明符 = 类型 + 类型的数组(长度可以为 0)
而且我们知道若干个类型连在一起又变成了声明说明符,所以上述等式等价于:
声明说明符 = 类型 + 声明说明符(可选)
再严谨一些,声明说明符还可以包括 const 这样的限定说明符,inline 这样的函数说明符,和 _Alignas 这样的对齐说明符。借用书中的公式,它的完整表达如下:
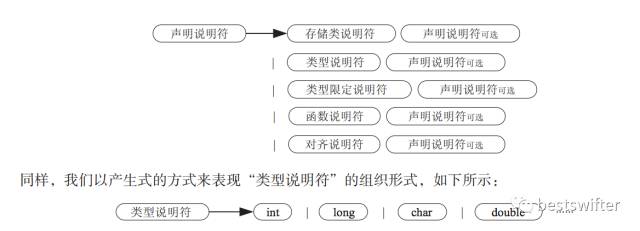
这才仅仅是声明语句中最简单的声明说明符,仅仅是几个类型和关键字的组合而已。后面的初始声明符列表的解析更复杂。如果有能力做完这些解析,恭喜你,成功的解析了声明语句。你会发现什么定义语句啦,调用语句啦,正妩媚的向你招手╮(╯▽╰)╭。
成功解析语法以后,我们会得到抽象语法树(AST: Abstract Syntax Tree)。以这段代码为例:
- int fun(int a, int b) {
- int c = 0;
- c = a + b;
- return c;
- }
它的语法树如下:
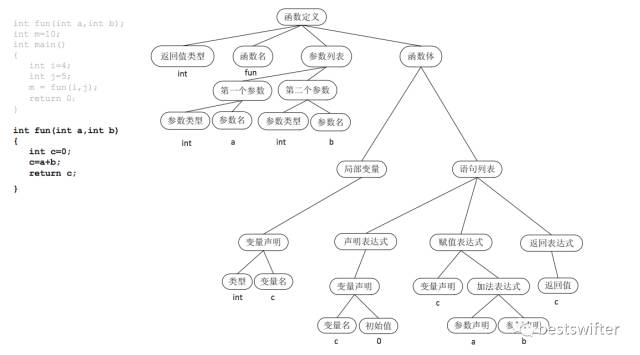
语法树将字符串格式的源代码转化为树状的数据结构,更容易被计算机理解和处理。但它距离中间代码还有一定的距离。
生成中间代码
以 GCC 为例,生成中间代码可以分为三个步骤:
- 语法树转高端 gimple
- 高端 gimple 转低端 gimple
- 低端 gimple 经过 cfa 转 ssa 再转中间代码
简单的介绍一下每一步都做了什么。
语法树转高端 gimple
这一步主要是处理寄存器和栈,比如 c = a + b 并没有直接的汇编代码和它对应,一般来说需要把 a + b 的结果保存到寄存器中,然后再把寄存器赋值给 c。所以这一步如果用 C 语言来表示其实是:
- int temp = a + b; // temp 其实是寄存器
- c = temp;
另外,调用一个新的函数时会进入到函数自己的栈,建栈的操作也需要在 gimple 中声明。
高端 gimple 转低端 gimple
这一步主要是把变量定义,语句执行和返回语句区分存储。比如:
- int a = 1;
- a++;
- int b = 1;
会被处理成:
- int a = 1;
- int b = 1;
- a++;
这样做的好处是很容易计算一个函数到底需要多少栈空间。
此外,return 语句会被统一处理,放在函数的末尾,比如:
- if (1 > 0) {
- return 1;
- }
- else {
- return 0;
- }
会被处理成:
- if (1 > 0) {
- goto a;
- }
- else {
- goto b;
- }
- a:
- return 1;
- b:
- return 0;
低端 gimple 经过 cfa 转 ssa 再转中间代码
这一步主要是进行各种优化,添加版本号等,我不太了解,对于普通开发者来说也没有学习的必要。
中间代码的意义
其实中间代码可以被省略,抽象语法树可以直接转化为目标代码(汇编代码)。然而,不同的 CPU 的汇编语法并不一致,比如 AT&T与Intel汇编风格比较 这篇文章所提到的,Intel 架构和 AT&T 架构的汇编码中,源操作数和目标操作数位置恰好相反。Intel 架构下操作数和立即数没有前缀但 AT&T 有。因此一种比较高效的做法是先生成语言无关,CPU 也无关的中间代码,然后再生成对应各个 CPU 的汇编代码。
生成中间代码是非常重要的一步,一方面它和语言无关,也和 CPU 与具体实现无关。可以理解为中间代码是一种非常抽象,又非常普适的代码。它客观中立的描述了代码要做的事情,如果用中文、英文来分别表示 C 和 Java 的话,中间码某种意义上可以被理解为世界语。
另一方面,中间代码是编译器前端和后端的分界线。编译器前端负责把源码转换成中间代码,编译器后端负责把中间代码转换成汇编代码。
LLVM IR 是一种中间代码,它长成这样:
- define i32 @square_unsigned(i32 %a) {
- %1 = mul i32 %a, %a
- ret i32 %1
- }
生成目标代码
目标代码也可以叫做汇编代码。由于中间代码已经非常接近于实际的汇编代码,它几乎可以直接被转化。主要的工作量在于兼容各种 CPU 以及填写模板。在最终生成的汇编代码中,不仅有汇编命令,也有一些对文件的说明。比如:
- .file "test.c" # 文件名称
- .global m # 全局变量 m
- .data # 数据段声明
- .align 4 # 4 字节对齐
- .type m, @objc
- .size m, 4
- m:
- .long 10 # m 的值是 10
- .text
- .global main
- .type main, @function
- main:
- pushl %ebp
- movl %esp, %ebp
- ...
汇编
汇编器会接收汇编代码,将它转换成二进制的机器码,生成目标文件(后缀是 .o),机器码可以直接被 CPU 识别并执行。从目标代码可以猜出来,最终的目标文件(机器码)也是分段的,这主要有以下三个原因:
- 分段可以将数据和代码区分开。其中代码只读,数据可写,方便权限管理,避免指令被改写,提高安全性。
- 现代 CPU 一般有自己的数据缓存和指令缓存,区分存储有助于提高缓存***率。
- 当多个进程同时运行时,他们的指令可以被共享,这样能节省内存。
段分离我们并不遥远,比如命令行中的 objcopy 可以自行添加自定义的段名,C 语言的 __attribute((section(段名)))__ 可以把变量定义在某个特定名称的段中。
对于一个目标文件来说,文件的最开头(也叫作 ELF 头)记录了目标文件的基本信息,程序入口地址,以及段表的位置,相当于是对文件的整体描述。接下来的重点是段表,它记录了每个段的段名,长度,偏移量。比较常用的段有:
- .strtab 段: 字符串长度不定,分开存放浪费空间(因为需要内存对齐),因此可以统一放到字符串表(也就是 .strtab 段)中进行管理。字符串之间用\0 分割,所以凡是引用字符串的地方用一个数字就可以代表。
- .symtab: 表示符号表。符号表统一管理所有符号,比如变量名,函数名。符号表可以理解为一个表格,每行都有符号名(数字)、符号类型和符号值(存储地址)
- .rel 段: 它表示一系列重定位表。这个表主要在链接时用到,下面会详细解释。
链接
在一个目标文件中,不可能所有变量和函数都定义在文件内部。比如 strlen 函数就是一个被调用的外部函数,此时就需要把 main.o 这个目标文件和包含了 strlen函数实现的目标文件链接起来。我们知道函数调用对应到汇编其实是 jump 指令,后面写上被调用函数的地址,但在生成 main.o 的过程中,strlen() 函数的地址并不知道,所以只能先用 0 来代替,直到***链接时,才会修改成真实的地址。
链接器就是靠着重定位表来知道哪些地方需要被重定位的。每个可能存在重定位的段都会有对应的重定位表。在链接阶段,链接器会根据重定位表中,需要重定位的内容,去别的目标文件中找到地址并进行重定位。
有时候我们还会听到动态链接这个名词,它表示重定位发生在运行时而非编译后。动态链接可以节省内存,但也会带来加载的性能问题,这里不详细解释,感兴趣的读者可以阅读《程序员的自我修养》这本书。
预处理
***简单描述一下预处理。预处理主要是处理一些宏定义,比如#define、#include、#if 等。预处理的实现有很多种,有的编译器会在词法分析前先进行预处理,替换掉所有 # 开头的宏,而有的编译器则是在词法分析的过程中进行预处理。当分析到 # 开头的单词时才进行替换。虽然先预处理再词法分析比较符合直觉,但在实际使用中,GCC 使用的却是一边词法分析,一边预处理的方案。
编译 VS 解释
总结一下,对于 C 语言来说,从源码到运行结果大致上需要经历编译、汇编和链接三个步骤。编译器接收源代码,输出目标代码(也就是汇编代码),汇编器接收汇编代码,输出由机器码组成的目标文件(二进制格式,.o 后缀),***链接器将各个目标文件链接起来,执行重定位,最终生成可执行文件。
编译器以中间代码为界限,又可以分前端和后端。比如 clang 就是一个前端工具,而 LLVM 则负责后端处理。另一个知名工具 GCC(GNU Compile Collection)则是一个套装,包揽了前后端的所有任务。前端主要负责预处理、词法分析、语法分析,最终生成语言无关的中间代码。后端主要负责目标代码的生成和优化。
关于编译原理的基础知识虽然枯燥,但掌握这些知识有助于我们理解一些有用的,但不太容易理解的概念。接下来,我们简单看一下别的语言是如何运行的。
Java
在 Java 代码的执行过程中,可以简单分为编译和执行两步。Java 的编译器首先会把 .java 格式的源码编译成 .class 格式的字节码。字节码对应到 C 语言的编译体系中就是中间码,Java 虚拟机执行这些中间码得到最终结果。
回忆一下上文对中间码的解释,一方面它与语言无关,仅仅描述客观事实。另一方面它和目标代码的差距并不大,已经包括了对寄存器和栈的处理,仅仅是抽象了 CPU 架构而已,只要把它具体化成各个平台下的目标代码,就可以交给汇编器了。
解释型语言
一般来说我们也把解释型语言叫做脚本语言,比如 Python、Ruby、JavaScript 等等。这类语言的特点是,不需要编译,直接由解释器执行。换言之,运行流程变成了:
源代码 -> 解释器 -> 运行结果
需要注意的是,这里的解释器只是一个黑盒,它的实现方式可以是多种多样的。举个例子,它的实现可以非常类似于 Java 的执行过程。解释器里面可以包含一个编译器和虚拟机,编译器把源码转化成 AST 或者字节码(中间代码)然后交给虚拟机执行,比如 Ruby 1.9 以后版本的官方实现就是这个思路。
至于虚拟机,它并不是什么黑科技,它的内部可以编译执行,也可以解释执行。如果是编译执行,那么它会把字节码编译成当前 CPU 下的机器码然后统一执行。如果是解释执行,它会逐条翻译字节码。
有意思的是,如果虚拟机是编译执行的,那么这套流程和 C 语言几乎一样,都满足下面这个流程:
源代码 -> 中间代码 -> 目标代码 -> 运行结果
下面是重点!!!
下面是重点!!!
下面是重点!!!
因此,解释型语言和编译型语言的根本区别在于,对于用户来说,到底是直接从源码开始执行,还是从中间代码开始执行。以 C 语言为例,所有的可执行程序都是二进制文件。而对于传统意义的 Python 或者 JavaScript,用户并没有拿到中间代码,他们直接从源码开始执行。从这个角度来看, Java 不可能是解释型语言,虽然 Java 虚拟机会解释字节码,但是对于用户来说,他们是从编译好的 .class 文件开始执行,而非源代码。
实际上,在 x86 这种复杂架构下,二进制的机器码也不能被硬件直接执行,CPU 会把它翻译成更底层的指令。从这个角度来说,我们眼中的硬件其实也是一个虚拟机,执行了一些“抽象”指令,但我相信不会有人认为 C 语言是解释型语言。因此,有没有虚拟机,虚拟机是不是解释执行,会不会生成中间代码,这些都不重要,重要的是如果从中间代码开始执行,而且 AST 已经事先生成好,那就是编译型的语言。
如果更本质一点看问题,根本就不存在解释型语言或者编译型语言这种说法。已经有人证明,如果一门语言是可以解释的,必然可以开发出这门语言的编译器。反过来说,如果一门语言是可编译的,我只要把它的编译器放到解释器里,把编译推迟到运行时,这么语言就可以是解释型的。事实上,早有人开发出了 C 语言的解释器:
C 源代码 -> C 语言解释器(运行时编译、汇编、链接) -> 运行结果
我相信这一点很容易理解,规范和实现是两套分离的体系。我们平常说的 C 语言的语法,实际上是一套规范。理论上来说每个人都可以写出自己的编译器来实现 C 语言,只要你的编译器能够正确运行,最终的输出结果正确即可。而编译型和解释型说的其实是语言的实现方案,是提前编译以获得***的性能提高,还是运行时去解析以获得灵活性,往往取决于语言的应用场景。所以说一门语言是编译型还是解释型的,这会非常可笑。一个标准怎么可能会有固定的实现呢?之所以给大家留下了 C 语言是编译型语言,Python 是解释型语言的印象,往往是因为这门语言的应用场景决定了它是主流实现是编译型还是解释型。
自举
不知道有没有人思考过,C 语言的编译器是如何实现的?实际上它还是用 C 语言实现的。这种自己能编译自己的神奇能力被称为自举(Bootstrap)。
乍一看,自举是不可能的。因为 C 语言编译器,比如 GCC,要想运行起来,必定需要 GCC 的编译器将它编译成二进制的机器码。然而 GCC 的编译器又如何编译呢……
解决问题的关键在于打破这个循环,我们可以先用一个比 C 语言低级的语言来实现一个 C 语言编译器。这件事是可能做到的,因为这个低级语言必然会比 C 语言简单,比如我们可以直接用汇编代码来写 C 语言的编译器。由于越低级的语言越简单,但表达能力越弱,所以用汇编来写可能太复杂。这种情况下我们可以先用一个比 C 语言低级但比汇编高级的语言来实现 C 语言的编译器,同时用汇编来实现这门语言的编译器。总之就是不断用低级语言来写高级语言的编译器,虽然语言越低级,它的表达能力越弱,但是它要解析的语言也在不断变简单,所以这件事是可以做到的。
有了低级语言写好的 C 语言编译器以后,这个编译器是二进制格式的。此时就可以删掉所有的低级语言,只留一个二进制格式的 C 语言编译器,接下来我们就可以用 C 语言写编译器,再用这个二进制格式的编译器去编译 C 语言实现的 C 语言编译器了,于是完成了自举。
以上逻辑描述起来比较绕,但我想多读几遍应该可以理解。如果实在不理解也没关系,我们只要明白 C 语言可以自举是因为它可以编译成二进制机器码,只要用低级语言生成这个机器码,就不再需要低级语言了,因为机器码可以直接被 CPU 执行。
从这个角度来看,解释型语言是不可能自举的。以 Python 为例,自举要求它能用 Python 语言写出来 Python 的解释器,然而这个解释器如何运行呢,最终还是需要一个解释器。而解释器体系下, Python 都是从源码经过解释器执行,又不能留下什么可以直接被硬件执行的二进制形式的解释器文件,自然是没办法自举的。然而,就像前面说的,Python 完全可以实现一个编译器,这种情况下它就是可以自举的。
所以一门语言能不能自举,主要取决于它的实现形式能否被编译并留下二进制格式的可执行文件。
运行时
本文的读者如果是使用 Objective-C 的 iOS 开发者,想必都有过在面试时被 runtime 支配的恐惧。然而,runtime 并非是 Objective-C 的专利,绝大多数语言都有这个概念。所以有人说 Objective-C 具有动态性是因为它有 runtime,这种说法并不准确,我觉得要把 Objective-C 的 runtime 和一般意义的运行时库区分开,认识到它仅仅是运行时库的一个组成部分,同时还是要深入到方法调用的层面来谈。
运行时库的基本概念
以 C 语言为例,有非常多的操作最终都依赖于 glibc 这个动态链接库。包括但不限于字符串处理(strlen、strcpy)、信号处理、socket、线程、IO、动态内存分屏(malloc)等等。这一点很好理解,如果回忆一下之前编译器的工作原理,我们会发现它仅仅是处理了语言的语法,比如变量定义,函数声明和调用等等。至于语言的功能, 比如内存管理,內建的类型,一些必要功能的实现等等。如果要对运行时库进行分类,大概有两类。一种是语言自身功能的实现,比如一些內建类型,内置的函数;另一种则是语言无关的基础功能,比如文件 IO,socket 等等。
由于每个程序都依赖于运行时库,这些库一般都是动态链接的,比如 C 语言的 (g)libc。这样一来,运行时库可以存储在操作系统中,节省内存占用空间和应用程序大小。
对于 Java 语言来说,它的垃圾回收功能,文件 IO 等都是在虚拟机中实现,并提供给 Java 层调用。从这个角度来看,虚拟机/解释器也可以被看做语言的运行时环境(库)。
swift 运行时库
经过这样的解释,相信 swift 的运行时库就很容易理解了。一方面,swift 是绝对的静态语言,另一方面,swift 毫无疑问的带有自己的运行时库。举个最简单的例子,如果阅读 swift 源码就会发现某些类型,比如字符串(String),或者数组,再或者某些函数(print)都是用 swift 实现的,这些都是 swift 运行时库的一部分。按理说,运行时库应该内置于操作系统中并且和应用程序动态链接,然而坑爹的 Swift 在本文写作之时依然没有稳定 ABI,导致每个程序都必须自带运行时库,这也就是为什么目前 swift 开发的 app 普遍会增加几 Mb 包大小的原因。
说到 ABI,它其实就是一个编译后的 API。简单来说,API 是描述了在应用程序级别,模块之间的调用约定。比如某个模块想要调用另一个模块的功能,就必须根据被调用模块提供的 API 来调用,因为 API 中规定了方法名、参数和返回结果的类型。而当源码被编译成二进制文件后,它们之间的调用也存在一些规则和约定。
比如模块 A 有两个整数 a 和 b,它们的内存布局如下:
| 模块 A |
|---|
| 初始地址 |
| a |
| b |
这时候别的模块调用 A 模块的 b 变量,可以通过初始地址加偏移量的方式进行。
如果后来模块 A 新增了一个整数 c,它的内存布局可能会变成:
| 模块 A |
|---|
| 初始地址 |
| c |
| a |
| b |
如果调用方还是使用相同的偏移量,可以想见,这次拿到的就是变量 a 了。因此,每当模块 A 有更新,所有依赖于模块 A 的模块都必须重新编译才能正确工作。如果这里的模块 A 是 swift 的运行时库,它内置于操作系统并与其他模块(应用程序)动态链接会怎么样呢?结果就是每次更新系统后,所有的 app 都无法打开。显然这是无法接受的。
当然,ABI 稳定还包括其他的一些要求,比如调用和被调用者遵守相同的调用约定(参数和返回值如何传递)等。
JavaScript 那些事
我们继续刚才有关运行时的话题,先从 JavaScript 的运行时聊起,再介绍 JavaScript 的相关知识。
JavaScript 是如何运行的
JavaScript 和其他语言,无论是 C 语言,还是 Python 这样的脚本语言,***的区别在于 JavaScript 的宿主环境比较奇怪,一般来说是浏览器。
无论是 C 还是 Python,他们都有一个编译器/解释器运行在操作系统上,直接把源码转换成机器码。而 JavaScript 的解释器一般内置在浏览器中,比如 Chrome 就有一个 V8 引擎可以解析并执行 JavaScript 代码。因此 JavaScript 的能力实际上会受到宿主环境的影响,有一些限制和加强。
首先来看看 DOM 操作,相关的 API 并没有定义在 ECMAScript 标准中,因此我们常用的 window.xxx 还有 window.document.xxx 并非是 JavaScript 自带的功能,这通常是由宿主平台通过 C/C++ 等语言实现,然后提供给 JavaScript 的接口。同样的,由于浏览器中的 JavaScript 只是一个轻量的语言,没有必要读写操作系统的文件,因此浏览器引擎一般不会向 JavaScript 提供文件读写的运行时组件,它也就不具备 IO 的能力。从这个角度来看,整个浏览器都可以看做 JavaScript 的虚拟机或者运行时环境。
因此,当我们换一个宿主环境,比如 Node.js,JavaScript 的能力就会发生变化。它不再具有 DOM API,但多了读写文件等能力。这时候,Node.js 就更像是一个标准的 JavaScript 解析器了。这也是为什么 Node.js 让 JavaScript 可以编写后端应用的原因。
JIT 优化
解释执行效率低的主要原因之一在于,相同的语句被反复解释,因此优化的思路是动态的观察哪些代码是经常被调用的。对于那些被高频率调用的代码,可以用编译器把它编译成机器码并且缓存下来,下次执行的时候就不用重新解释,从而提升速度。这就是 JIT(Just-In-Time) 的技术原理。
但凡基于缓存的优化,一定会涉及到缓存***率的问题。在 JavaScript 中,即使是同一段代码,在不同上下文中生成的机器码也不一定相同。比如这个函数:
- function add(a, b) {
- return a + b;
- }
如果这里的 a 和 b 都是整数,可以想见最终的代码一定是汇编中的 add 命令。如果类似的加法运算调用了很多次,解释器可能会认为它值得被优化,于是编译了这段代码。但如果下一次调用的是 add("hello", "world"),之前的优化就无效了,因为字符串加法的实现和整数加法的实现完全不同。
于是优化后的代码(二进制格式)还得被还原成原先的形式(字符串格式),这样的过程被称为去优化。反复的优化 -> 去优化 -> 优化 …… 非常耗时,大大降低了引入 JIT 带来的性能提升。
JIT 理论上给传统的 JavaScript 带了了 20-40 倍的性能提升,但由于上述去优化的存在,在实际运行的过程中远远达不到这个理论上的性能天花板。
WebAssembly
前文说过,JavaScript 实际上是由浏览器引擎负责解析并提供一些功能的。浏览器引擎可能是由 C++ 这样高效的语言实现的,那么为什么不用 C++ 来写网页呢?实际上我认为从技术角度来说并不存在问题,直接下发 C++ 代码,然后交给 C++ 解释器去执行,再调用浏览器的 C++ 组件,似乎更加符合直觉一些。
之所以选择 JavaScript 而不是 C++,除了主流浏览器目前都只支持 JavaScript 而不支持 C++ 这个历史原因以外,更重要的一点是一门语言的高性能和简单性不可兼得。JavaScript 在运行速度方面做出了牺牲,但也具备了简单易开发的优点。作为通用编程语言,JavaScript 和 C++ 主要的性能差距就在于缺少类型标注,导致无法进行有效的提前编译。之前说过 JIT 这种基于缓存去猜测类型的方式存在瓶颈,那么最精确的方式肯定还是直接加上类型标注,这样就可以直接编译了,代表性的作品有 Mozilla 的Asm.js。
Asm.js 是 JavaScript 的一个子集,任何 JavaScript 解释器都可以解释它:
- function add(a, b) {
- a = a | 0 // 任何整数和自己做按位或运算的结果都是自己
- b = b | 0 // 所以这个标记不改变运算结果,但是可以提示编译器 a、b 都是整数
- return a + b | 0
- }
如果有 Asm.js 特定的解释器,完全可以把它提前编译出来。即使没有也没关系,因为它完全是 JavaScript 语法的子集,普通的解释器也可以解释。
然而,回顾一下我们最初对解释器的定义: 解释器是一个黑盒,输入源码,输出运行结果。Asm.js 其实是黑盒内部的一个优化,不同的黑盒(浏览器)无法共享这一优化。换句话说 Asm.js 写成的代码放到 Chrome 上面和普通的 JavaScript 毫无区别。
于是,包括微软、谷歌和苹果在内的各大公司觉得,是时候搞个标准了,这个标准就是 WebAssembly 格式。它是介于中间代码和目标代码之间的一种二进制格式,借用WebAssembly 系列(四)WebAssembly 工作原理 一文的插图来表示:
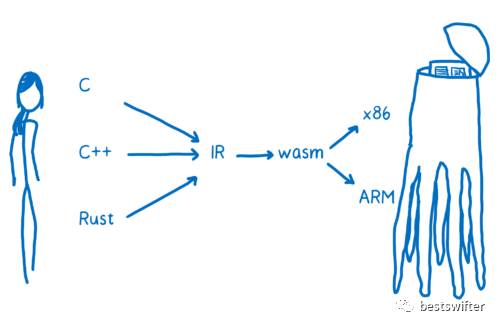
通常从中间代码到机器码,需要经过平台具体化(转目标代码)和二进制化(汇编器把汇编代码变为二进制机器码)这两个步骤。而 WebAssembly 首先完成了第二个步骤,即已经是二进制格式的,但只是一系列虚拟的通用指令,还需要转换到各个 CPU 架构上。这样一来,从 WebAssembly 到机器码其实是透明且统一的,各个浏览器厂商只需要考虑如何从中间代码转换 WebAssembly 就行了。
由于编译器的前端工具 Clang 可以把 C/C++ 转换成中间代码,因此理论上它们都可以用来开发网页。然而谁会这么这么做呢,放着简单快捷,现在又高效的 JavaScript 不写,非要去啃 C++?
跨语言那些事儿
C++ 写网页这个脑洞虽然比较大,但它启发我思考一个问题:“对于一个常见的可以由某个语言完成的任务(比如 JavaScript 写网页),能不能换一个语言来实现(比如 C++),如果不能,制约因素在哪里”。
由于绝大多数主流语言都是图灵完备的,也就是说一切可计算的问题,在这些语言层面都是等价的,都可以计算。那么制约语言能力的因素也就只剩下了运行时的环境是否提供了相应的功能。比如前文解释过的,虽然浏览器中的 JavaScript 不能读写文件,不能实现一个服务器,但这是浏览器(即运行时环境)不行,不是 JavaScript 不行,只要把运行环境换成 Node.js 就行了。
直接语法转换
大部分读者应该接触过简单的逆向工程。比如编译后的 .o 目标文件和 .class 字节码都可以反编译成源代码,这种从中间代码倒推回源代码的技术也被叫做反编译(decompile),反编译器的工作流程基本上是编译器的倒序,只不过***的反编译一般来说比较困难,这取决于中间代码的实现。像 Java 字节码这样的中间代码,由于信息比较全,所以反编译就相对容易、准确一些。C 代码在生成中间代码时丢失了很多信息,因此就几乎不可能 100% 准确的倒推回去,感兴趣的读者可以参考一下知名的反编译工具Hex-Rays 的一篇博客。
前文说过,编译器前端可以对多种语言进行词法分析和语法分析,并且生成一套语言无关的中间代码,因此理论上来说,如果某个编译器前端工具支持两个语言 A 和 B 的解析,那么 A 和 B 是可以互相转换的,流程如下:
A 源码 <--> 语言无关的中间代码 <--> B 源码
其中从源码转换到中间代码需要使用编译器,从中间代码转换到源码则使用反编译器。
但在实际情况中,事情会略复杂一些,这是因为中间代码虽然是一套语言无关、CPU 也无关的指令集,但不代表不同语言生成的中间代码就可以通用。比如中间代码共有 1、2、3、……、6 这六个指令。A 语言生成的中间代码仅仅是所有指令的一个子集,比如是 1-5 这 5 个指令;B 语言生成的中间代码可能是所有指令的另一个子集,比如 2-6。这时候我们说的 B 语言的反编译器,实际上是从 2-6 的指令子集推导出 B 语言源码,它对指令 1 可能无能为力。
以 GCC 的中间代码 RTL: Register Transfer Language 为例,官方文档 在对 RTL 的解释中,就明确的把 RTL 树分为了通用的、C/C++ 特有的、Java 特有的等几个部分。
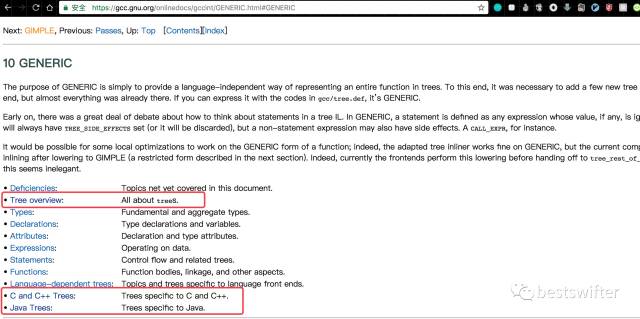
具体来说,我们知道 Java 并不能直接访问内存地址,这一点和浏览器上的 JavaScript 不能读写文件很类似,都是因为它们的运行环境(虚拟机)具备这种能力,但没有在语言层面提供。因此,含有指针四则运算的 C 代码无法直接被转换成 Java 代码,因为 Java 字节码层面并没有定义这样的抽象,一种简单的方案是申请一个超大的数组,然后自己模拟内存地址。
所以,即使编译器前端同时支持两种语言的解析,要想进行转换,还必须处理两种语言在中间代码层面的一些小差异,实际流程应该是:
A 源码 <--> 中间代码子集(A) <--适配器--> 中间代码子集(B) <--> B 源码
这个思路已经不仅仅停留在理论上了,比如 Github 上有一个库: emscripten 就实现了将任何 Clang 支持的语言(比如 C/C++ 等)转换成 JavaScript,再比如 lljvm实现了 C 到 Java 字节码的转换。
然而前文已经解释过,实现单纯语法的转换意义并不大。一方面,对于图灵完备的语言来说,换一种表示方法(语言)去解决相同的问题并没有意义。另一方面,语言的真正功能绝不仅仅是语法本身,而在于它的运行时环境提供了什么样的功能。比如 Objective-C 的 Foundation 库提供了字典类型 NSDictionary,它如果直接转换成 C 语言,将是一个找不到的符号。因为 C 语言的运行时环境根本就不提供对这种数据结构的支持。因此凡是在语言层面进行强制转换的,要么利用反编译器拿到一堆格式正确但无法运行的代码,要么就自行解析语法树并为转换后的语言添加对应的能力,来实现转换前语言的功能。
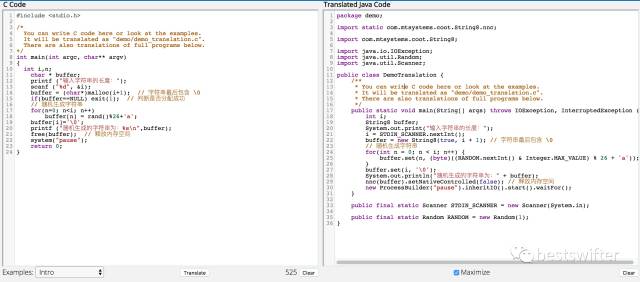
比如图中就是一个 C 语言转换 Java 的工具,为了实现 C 语言中的字符串申请和释放内存,这个工具不得不自己实现了 com.mtsystems.coot.String8 类。这样巨大的成本,显然不够普适,应用场景相对有限。
总之,直接的语法转换是一个美好的想法,但实现起来难度大,收益有限,通常是为了移植已经用某个语言写好的框架,或者开个脑洞用于学习,但实际应用场景并不多。
胶水语言 Python
Python 一个很强大的特点是胶水语言,可以把 Python 理解为各种语言的粘合剂。对于 Python 可以处理的逻辑,用 Python 代码即可完成。如果追求***的性能或者调用已经实现的功能,也可以让 Python 调用已经由别的语言实现的模块,以 Python 和 C 语言的交互解释一下。
首先,如果是 C 语言要执行 Python 代码,显然需要一个 Python 的解释器。由于在 Mac OS X 系统上,Python 解释器是一个动态链接库,所以只要导入一下头文件即可,下面这段代码可以成功输出 “Hello Python!!!”:
- #include <stdio.h>
- #import <Python/Python.h>
- int main(int argc, const char * argv[]) {
- Py_SetProgramName(argv[0]);
- Py_Initialize();
- PyRun_SimpleString("print 'Hello Python!!!'\n");
- Py_Finalize();
- return 0;
- }
如果是在 iOS 应用里,由于 iOS 系统没有对应的动态库,所以需要把 Python 的解释器打包成一个静态库并且链接到应用中,网上已经有人做好了: python-for-iphone,这就是为什么我们看到一些教育类的应用模拟了 Python 解释器,允许用户编写 Python 代码并得到输出。
Python 调用 Objective-C/C 也不复杂,只需要在 C 代码中指定要暴露的模块 A 和要暴露的方法 a,然后 Python 就可以直接调用了:
- import A
- A.a()
详细的教程可以看这里: 如何实现 C/C++ 与 Python 的通信?
有时候,如果能把自己熟悉的语言应用到一个陌生的领域,无疑会大大降低上手的难度。以 iOS 开发为例,开发者的日常其实是利用 Objective-C 语法来描述一些逻辑,最终利用 UIKit 等框架完成和应用的交互。 一种很自然而然的想法是,能不能用 Python 来实现逻辑,并且调用 Objective-C 的接口,比如 UIKit、Foundation 等。实际上前者是完全可以实现的,但是 Python 调用 Objective-C 远比调用 C 语言要复杂得多。
一方面从之前的分析中也能看出,并不是所有的源码编译成目标文件都可以被 Python 引用;另一方面,最重要的是 Objective-C 方法调用的特性。我们知道方法调用实际上会被编译成 msg_Send 并交给 runtime 处理,最终找到函数指针并调用。这里 Objective-C 的 runtime 其实是一个用 C 语言实现动态链接库,它可以理解为 Objective-C 运行时环境的一部分。换句话说,没有 runtime 这个库,包含方法调用的 Objective-C 代码是不可能运行起来的,因为 msg_Send 这个符号无法被重定向,运行时将找不到 msg_Send 函数的地址。就连原生的 Objective-C 代码都需要依赖运行时,想让 Python 直接调用某个 Objective-C 编译出来的库就更不可能了。
想用 Python 写开发 iOS 应用是有可能的,比如: PyObjc,但最终还是要依赖 Runtime。大概的思路是首先用 Python 拿到 runtime 这个库,然后通过这个库去和 runtime 交互,进而具备了调用 Objective-C 和各种框架的能力。比如我要实现 Python 中的 UIView 这个类,代码会变成这样:
- import objc
- # 这个 objc 是动态加载 libobjc.dylib 得到的
- # Python 会对 objc 做一些封装,提供调用 runtime 的能力
- # 实际的工作还是交给 libobjc.dylib 完成
- class UIView:
- def __init__(self, param):
- objc.msgSend("UIView", "init", param)
这么做的性价比并不高,如果和 JSPatch 相比,JSPatch 使用了内置的 JavaScriptCore 作为 JavaScript 的解析器,而 PyObjc 就得自己带一个 libPython.a 解释器。此外,由于 iOS 系统的沙盒限制,非越狱机器并不能拿到 libobjc 库,所以这个工具只能在越狱手机上使用。
OCS
既然说到了 JSPatch 这一类动态化的 iOS 开发工具,我就斗胆猜测一下腾讯 OCS 的实现原理,目前介绍 OCS 的文章***,由于苹果公司的要求,原文已经被删除,从新浪博客上摘录了一份: OCS ——史上最疯狂的 iOS 动态化方案。如果用一句话来概述,那么就是 OCS 是一个 Objective-C 解释器。
首先,OCS 基于 clang 对下发的 Objective-C 代码做词法、语法分析,生成 AST 然后转化成自定义的一套中间码(OSScript)。当然,原生的 Objective-C 可以运行,绝不仅仅是编译器的功劳。就像之前反复强调的那样,运行时环境也必不可少,比如负责 GCD 的 libdispatch 库,还有内存管理,多线程等等功能。这些功能原来都由系统的动态库实现,但现在必须由解释器实现,所以 OCS 的做法是开发了一套自己的虚拟机去解释执行中间码。这个运行原理就和 JVM 非常类似了。
当然,最终还是要和 Objective-C 的 Runtime 打交道,这样才能调用 UIKit 等框架。由于对虚拟机的实现原理并不清楚,这里就不敢多讲了,希望在学习完 JVM 以后再做分享。
参考资料
- AT&T与Intel汇编风格比较
- glibc
- WebAssembly 系列(一)生动形象地介绍 WebAssembly
- Decompilers and beyond
- python-for-iphone
- 如何实现 C/C++ 与 Python 的通信?
- WebAssembly 系列(四)WebAssembly 工作原理
- 扯淡:大白话聊聊编译那点事儿
- rubicon-objc
- OCS ——史上最疯狂的 iOS 动态化方案
- 虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
- JavaScript的功能是不是都是靠C或者C++这种编译语言提供的?
- 计算机编程语言必须能够自举吗?
- 如何评论浏览器***的 WebAssembly 字节码技术?
- Objective-C Runtime —— From Build To Did Launch
- 10 GENERIC
- 写个编译器,把C++代码编译到JVM的字节码可不可行?