在图像分析应用中,海量图片样本的有效自动化过滤是一项重要的基础工作。本文介绍一种基于多重算法过滤的处理方案,能够自动提取有效图像样本,极大减少人工标注的工作量。
背景及问题描述
深度学习技术在计算机视觉领域取得了巨大的成功,其标志性事件之一就是计算机算法在Imagenet竞赛中的目标识别准确率已经超过了人类。在学术圈的创新成果爆发式涌现的同时,各大企业也利用深度学习技术,推出了众多图像分析相关的人工智能相关产品及应用系统。这些成果所采用的技术路线,很多都是利用海量的已标注样本数据,在深度神经网络上训练相应的识别或检测模型。就企业算法应用而言,往往需要根据实际的应用场景,构建自己的训练样本集,以提升算法的有效性。在深度学习大行其道的今天,能够获得大量高质量标注样本,更是搭建高效应用算法系统的重要前提。一方面,深度学习与传统算法相比,其突出特征之一就是提供的训练样本越多,算法的精准性越高;另一方面,尽管无监督的深度学习算法在学术领域也获得了相当大的进步,但就目前而言,有监督的深度学习算法仍然是主流,对于企业级应用更是如此。
其中对于图像识别类的算法应用,通常需要获得不同类别对象的足量样本图像。其样本来源,可以有四种基本途径:
- 实地拍摄相关物品,此类方法效率比较低,适用于类别较少,每类需要大量高质量样本的情况,比如目标检测;
- 识别对象如果是商品,可以利用其商品主图,但商品主图经过图像处理,且较为单一,与实际场景不符;
- 在不同网站通过文本搜索或匹配获取相关的网络图像,此类方法可以获得大量的图像样本;
- 通过图像生成的方式来获得样本图像,比如近年来发展很快的生成对抗网络(GAN),此类方法的前景非常看好,但目前来说在大量不同类别上的效果还有待提升。

图1 不同渠道获取的商品图像样本示例: a 摆拍,b 主图,c 网络图像
目前而言,第三种获取网络图像的方式是常规采用的样本收集方案。
网络来源的图像样本,其存在的一个主要问题是噪声图像非常严重,如果采用主题词搜索得到待选图像集合,里面的不相关图像占据了很大的比例,且来源较为随机;如果采用电商网站晒单图作为待选图像集合,里面同样包含着发票、外包装、聊天纪录等大量无关图像以及顶视图或近视图等不合规图像。因此必须要对得到的图像集进行过滤,筛查出其中的噪声图像。这种过滤如果用人工进行筛选则过于低效,很难满足实际要求,应该用算法自动筛选为主、人工校验为辅的方式来实现。本文下面针对这一问题,介绍一种实用的基于多重处理的图像样本过滤方法。
思路及技术步骤
通过网络直接得到的图像样本集合,一般有以下几个特点。
- 噪声图像可分为:重复图像和极相似图像、常见噪声图像、无规律的杂乱噪声图像,各自均占有一定比例;
- 目标样本图像也占有一定比例,且相对于噪声图像而言,其类内相似度较高。
参照以上的问题特点,可以针对性得到一些解决的思路:
- 对于多且杂的噪声数据,采取多重处理的方式来逐步筛除。噪声数据类型比较多变,采用单一的方法很难全部加以筛除。根据其特点加以多轮的粗筛和精筛,逐批的处理不同类型的噪声数据,可以降低每个环节的技术风险,保证每个环节的有效性。
- 由于目标在样本空间中分布较为集中,如果对待选样本集进行无监督聚类,目标样本会集中在较为紧凑的聚类上。相比于噪声图像的无序杂乱而言,目标样本自身的类内差距还是比较小的,通过对大量实际数据的观察可以印证这一点。
- 对于某一样本,分类器返回的类别置信度可以作为样本与该类别相关度的度量。普通聚类算法不易量化样本点与所属聚类的相关度,无法做更为精细的样本筛选。相比之下利用分类器得到的类别置信度,可以作为相关度的合适度量,用来精细挑选剩余的噪声样本。

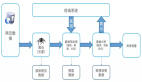
图2 技术方案概要图
根据以上的解决思路,设计出一个多重过滤的技术方案,其具体流程可分为如下几个步骤(参见图2):
- 图像去重:去除重复图像及极相似图像;
- 常见噪声图像过滤:过滤掉人脸、包装、发票等无关的常见类型噪声图像;
- 基于聚类的样本挑选:在深度特征空间上进行聚类,选取合适的聚类作为目标样本,并将其他聚类作为噪声图像去除;
- 基于分类的样本筛选:利用分类器返回的置信度来评估样本与相应类别的相关度,进一步筛选样本。
详细介绍
图像去重及常见噪声图像过滤
待选样本集里含有较多的重复图像或极相似图像,可以通过不同的方式去重:提取图像的直方图特征向量,利用特征向量之间的相似性进行去重;或者构建一个哈希表,提取图像的简单颜色和纹理特征,对特征量化后利用哈希表进行查询,能够查询到的就是重复或极相似图像,查询不到的加入表中。前一种方法对于微小差异表现更好,后一种方法的计算性能优势明显。
待选样本集里往往会含有一些常见的噪声图像模式,比如人脸、纸箱外包装、发票、聊天纪录图、商品或店铺Logo图等,占有相当高的比例。对于这些常见噪声图像,先提取其HOG特征,并用提前训练好的SVM分类器对其进行分类。为了保证精度,对于不同类的噪声图像,分别训练1vN的SVM分类器,只要图像判别为其中任一类噪声图像,即将其筛出。
以上两步,只利用了图像的简单特征,只能够去除样本集里的重复图像和常见噪声图像,对于更复杂的噪声图像模式,需要利用更有效的图像特征,并对于复杂类别采用无监督聚类来挖掘。
基于聚类的样本挑选
要利用图像本身的丰富信息对其进行聚类,首先需要提取更为丰富的图像特征。因此可利用深度网络模型来提取图像特征,得到的特征融合了常见的图像基本特征,并包含了更为高阶的图像语义信息,具有更强的表现能力。这里借助在Imagenet数据集上训练得到的网络模型,并利用已有的样本集进行fine-tune,这样模型对于特定品类的表达能力得到增强。这里对于一个图像样本,通过深度网络得到的特征是1024维向量,进一步通过PCA降维成256维的特征向量。这样图像样本集就构成了一个特征数据空间。
接下来,在降维后的特征数据空间,利用一种基于密度的聚类算法进行聚类。该算法最突出的特点采用了一种新颖的聚类中心选择方法,其准则可描述为:
- 聚类中心附近的点密度很大,且其密度大于其任何邻居点的密度;
- 聚类中心和点密度比它更大的数据点,它们的距离是比较大的。
选择了合适的聚类中心之后,再将各数据点分类到离其最近的聚类上,并根据各点距离相应聚类中心的远近,把它们划分成核心数据点和边缘数据点。
该聚类算法思路简单,效率较高,并且对于不同的场景具有较好的鲁棒性。
在所得的聚类结果中,进一步选出密度较大且半径较为紧凑的聚类,其中的样本作为待选的目标样本数据,而其他聚类对应的样本则作为噪声样本予以筛除。
基于分类的样本筛选
以上聚类所得的目标样本中,可能还含有少数的不相关样本,需要进一步的筛选。这里利用分类器的置信度评估样本的类别相关度,其中与所属类别不相关或弱相关的样本可以进一步去除。
具体方法是从目标样本中随机可放回的选取若干样本,并打上新的类别标签,作为新的训练样本,对一个已有的卷积神经网络模型进行fine-tune,这个卷积神经网络模型与前面提取特征的网络模型必须有一定差异(模型结构和训练数据都不同)。利用这个新的模型,对目标样本进行识别,得到其类别置信度。如果某个样本在所属类别上置信度很低,则将该样本作为不相关样本予以筛除。
经过以上筛选之后,最终得到的目标样本经过人工简单校验,就可以作为高质量样本集用于训练和测试。
应用效果
通过对于从网络获取的上万类别的近500万样本图像进行处理,并由人工校验算法的筛选结果。最终所得的目标样本,总体的类别相关度达到95%,其中对于较为热门的类别,样本相关度可以达到99%以上,总效率超过人工筛选百倍以上。图3左边是筛选得到的目标样本,右边是筛除掉的噪声图像。
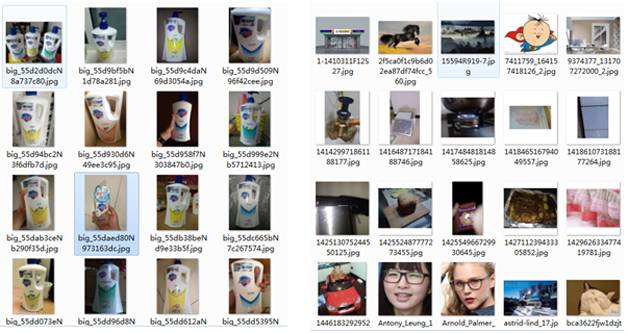
图3 样本图像筛选结果示例
苏宁“智能视觉图谱”是一个综合性的图像、视频相关算法平台,其宗旨是为公司内外的相关业务场景提供应用算法服务。目前所提供的算法接口包括商品识别、人脸特征分析及人脸验证、Logo检测、敏感图分析、广告敏感词分析、图像抠图等,分别涉及商品内容识别、人脸识别、目标检测、敏感图识别、OCR算法、图像分割及抠图等算法领域,平台所支持的算法服务还在进一步增加中,已有算法的效果与性能也在不断优化,以满足各种实际应用场景的需要。其中较多与识别相关的算法服务,都需要利用足量样本数据训练高精度的分类器。上文所述技术方案已广泛应用于当中商品图像识别、敏感图识别、Logo识别等应用算法的样本筛选工作,极大的提升了开发效率,节省了人力成本,并为高效算法模型的训练提供了可靠的数据保障。以商品图像识别类算法为例,利用以上样本收集和过滤方式获得***别的真实图像样本,以ResNet模型为架构,训练出高准确率的商品识别模型,并在此基础上搭建了面向全品类商品的图像检索系统,并广泛应用于商品种类识别、基于外形的商品推荐、商品图像检索、基于外形相似度的商品匹配等实际业务场景。
总结
在企业级深度学习图像应用中,海量高质量图像样本的获取,是取得优异算法性能的重要前提。工程实践中,在图像样本严重不足的情况下,仅仅对样本进行数据增强,都可以在测试集上获得几个百分点的效果提升,如果能够增加丰富真实的样本数据,对于相应类别的识别率提升更是立竿见影,而且泛化性能很好,可以经受住各种实际场景的考验。因此样本工程(图像样本的获取和挑选)是绝对不能忽视的重要工作,而且需要长期进行下去。不过,“爬图容易挑图难”,即使积累了海量样本数据,却因为缺乏有效的处理手段和标注人力而望洋兴叹,这也是经常遇到的一种数据困境。
本文主要介绍了我们在这个问题上的一种实践方案,其结果说明,采用多重过滤的方式,充分利用初级特征、深度特征等特征表达方式和无监督聚类、深度分类器等分类方法,就可以从纷繁芜杂的网络图像中,有效抽取高质量的目标样本。另外,我们也看到深度学习领域在不断取得新的研究成果,其中无监督式的深度学习更符合人类的认知习惯,且对样本质量没有如此苛刻的要求,该领域理论和技术的飞速发展对企业深度学习应用将意味着更为光明的未来。
主要参考文献:
1. Clustering by fast search and find of density peaks, Science, 2014, 344(6191):1492-6, Alex Rodriguez and Alessandro Laio,.
2. Extracting Visual Knowledge from the Internet, Y Yao,J Zhang,XS Hua,F Shen,Z Tang.
3. Going deeper with convolutions[J]. arXiv preprint arXiv:1409.4842, 2014, Szegedy C, Liu W, Jia Y, et al.
4. Deep Residual Learning for Image Recognition,Computer Vision and Pattern Recognition , 2015 :770-778,K He, X Zhang, S Ren, J Sun.