【引自tty之星的博客】前言:在上一章介绍了MySQL的优化以及优化的思路,那么如果有一种情况如果数据库已经建立好了索引,在使用sql语句索引查询时;但是在慢查询日志当中任然找到了之前的sql语句会有哪几种情况:
1):sql语句的索引没有起到效果,
2):查询的数据量过大,造成数据的查询缓慢,
在工作当中每个数据库都会存在庞大的数据量,比如说访问量等等都会造成数据的查询缓慢,那么如何解决这个问题,接下来往下看:
分区和分表:
我们的数据库数据越来越大,随之而来的是单个表中数据太多。以至于查询书读变慢,而且由于表的锁机制导致应用操作也搜到严重影响,出现了数据库性能瓶颈。
1、分表
什么是分表?
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构文件。这些表可以分布在同一块磁盘上,也可以在不同的机器上。app读写的时候根据事先定义好的规则得到对应的表名,然后去操作它。主要针对myisam存储,如果是innodb存储那么将会是.idb文件和.frm文件
将单个数据库表进行拆分,拆分成多个数据表,然后用户访问的时候,根据一定的算法(如用hash的方式,也可以用求余(取模)的方式),让用户访问不同的表,这样数据分散到多个数据表中,减少了单个数据表的访问压力。提升了数据库访问性能。分表的目的就在于此,减小数据库的负担,缩短查询时间。
注:客户端访问的时候根本不知道表已经被分开了,任然属于一个逻辑的整体对于客户端来说,客户端主要关心的是查询的内容以及查询的速度效率,但是作为一名DBA必须要了解这些;只有这样才能够满足客户的要求。
另外在分表的时候分为两种;垂直分割和水平分割:
垂直切分是指数据表列的拆分,把一张列比较多的表拆分为多张表
水平拆分是指数据表行的拆分,把一张的表的数据拆成多张表来存放。
分表的方式:
1)mysql集群
它并不是分表,但起到了和分表相同的作用。集群可分担数据库的操作次数,将任务分担到多台数据库上。集群可以读写分离,减少读写压力。从而提升数据库性能。
2)预先估计会出现大数据量并且访问频繁的表,将其分为若干个表
比如说娱乐新闻的app可以通过每一分钟的访问量,推算出每个小时,以及每一天的大概访问情况,如果是这样的话,那么我们就以分表存储这些数据,例如创建10000张表,设定好阈值,当一定的数据量达到预先设定的值得时候就想下一个表当中存储内容,保证数据库的性能。
3)利用merge存储引擎来实现分表
对于DBA来说,如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了,用merge存储引擎来实现分表, 这种方法比较适合。
那么我们来介绍下merge的用法以及功能:
merge存储引擎:
merge分表,分为主表和子表,主表类似于一个壳子,逻辑上封装了子表,实际上数据都是存储在子表中的。
注:字表是用来存放真实数据的地方是不能在进行细分的,但是可以合并,如果要创建多个字表,就在开始创建的时候多创建几个,进行估算大概需要几个。
我们可以通过主表插入和查询数据,如果清楚分表规律,也可以直接操作子表。
那么我们来对merge进行一个演示,希望大家对merge有一个更加深刻的了解
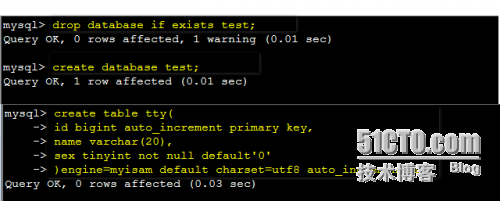
创建一个完整表存储着所有的成员信息(表名为tty)
mysql> drop database IF EXISTS test; =======>如果test存在那么就删掉它
mysql> create database test;=========>创建test数据库
mysql> use test; ==========>进入test库
create table tty( ==============>创建tty表
id bigint auto_increment primary key, ============> 将id号设置为主键
name varchar(20), =============>name的字符类型
sextinyint not nulldefault '0' ==========>性别的字符类型
)engine=myisam default charset=utf8 auto_increment=1; ===========> 存储引擎为myisam,utf-8字符集,可以自动扩展。
接下来往里面添加点数据:
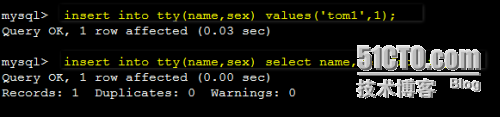
mysql> insert into tty(name,sex) values('tom1',1);
mysql> insert into tty(name,sex) select name,sex from tty;
- 1.
- 2.
- 3.
第二条语句多执行几次就有了很多数据
执行之后我们来查询一下有多少条数据:
mysql> select * from tty; {有8192条数据}
- 1.
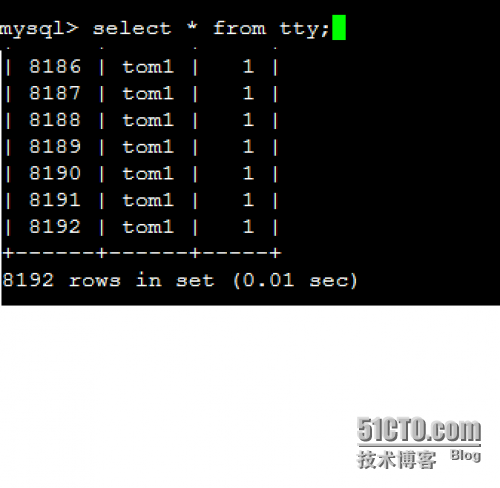
下面我们进行分表,这里我们把tty分两个表tb_tty1,tb_tty2。
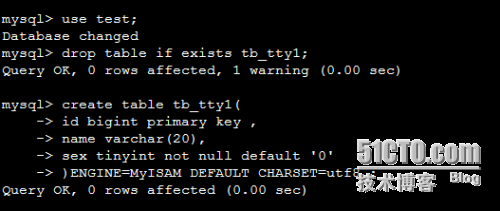
创建tb_tty1表:
mysql> use test;
DROP table IF EXISTS tb_tty1;
create table tb_tty1(
id bigint primary key ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
DROP table IF EXISTS tb_tty2;
create table tb_tty2(
id bigint primary key,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
创建tb_tty2表
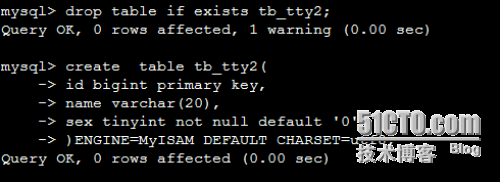
//创建tb_tty2也可以用下面的语句 create table tb_tty2 like tb_tty1;
创建主表tb_tty
DROP table IF EXISTS tb_tty;
- 1.
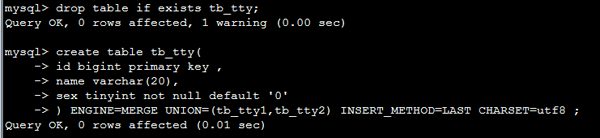
注:INSERT_METHOD,此参数INSERT_METHOD = NO 表示该表不能做任何写入操作只作为查询使用,INSERT_METHOD = LAST表示插入到最后的一张表里面。INSERT_METHOD = first表示插入到第一张表里面。
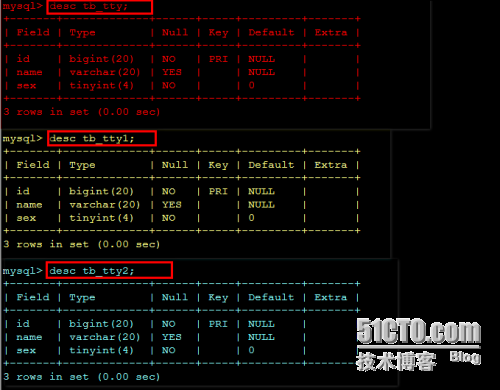
查看一下tb_tty表、tb_tty1、tb_tty2的结构:
mysql>desc tb_tty;
- 1.
接下来,我们把数据分到两个分表中去:
mysql> insert into tb_tty1(id,name,sex) select id,name,sex from tty where id%2=0;
mysql> insert into tb_tty2(id,name,sex) select id,name,sex from tty where id%2=1;
- 1.
- 2.
- 3.
如果要是分为三个表的情况可以使用ID%3=0、ID%3=1、id%=2

查看两个子表的数据:{前面说过共有8192条数据}
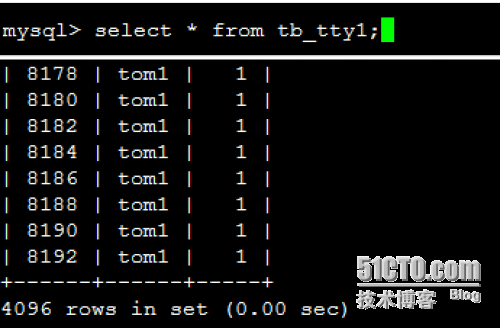
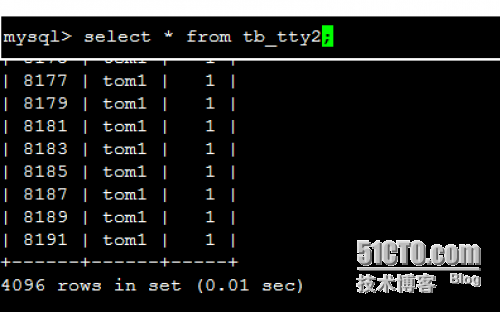
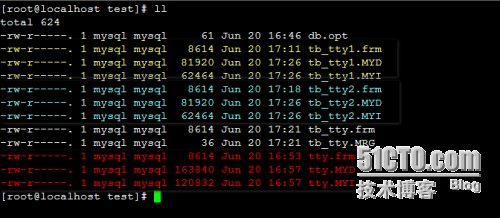
注意:总表只是一个外壳,存取数据发生在一个一个的子表里面。
注意:每个子表都有自已独立的相关表文件,而主表只是一个壳,并没有完整的相关表文件
2、分区
什么是分区?
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置。
另外分区也可以分为两种:
垂直分区和水平分区
水平分区(Horizontal Partitioning)这种形式分区是对表的行进行分区,所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
垂直分区(Vertical Partitioning)这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
查看当将配置是否支持分区:
mysql> show plugins;
- 1.
在显示结果中,可以看到partition是ACTIVE的,表示支持分区

之前演示了一个分表的方式,接下来为大家演示一个分区的方式:
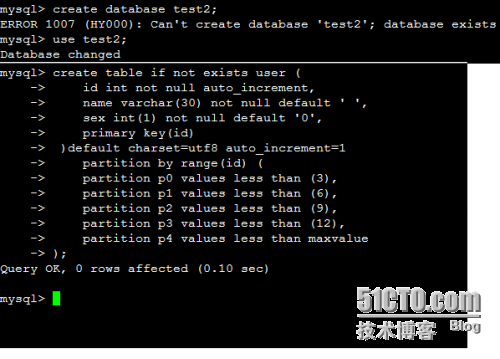
mysql> create database test2;
mysql> use test2;
mysql> create table if not exists user (
id int not null auto_increment,
name varchar(30) not null default ' ',
sex int(1) not null default '0',
primary key(id)
)default charset=utf8 auto_increment=1
partition by range(id) (
partition p0 values less than (3),
partition p1 values less than (6),
partition p2 values less than (9),
partition p3 values less than (12),
partition p4 values less than maxvalue
);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
插入些数据
mysql> insert into test2.user(name,sex)values ('tom1','0');
mysql> insert into test2.user(name,sex)values ('tom2','1');
mysql> insert into test2.user(name,sex)values ('tom3','1');
mysql> insert into test2.user(name,sex)values ('tom4','0');
mysql> insert into test2.user(name,sex)values ('tom5','0');
mysql> insert into test2.user(name,sex)values ('tom6','1');
mysql> insert into test2.user(name,sex)values ('tom7','1');
mysql> insert into test2.user(name,sex)values ('tom8','1');
mysql> insert into test2.user(name,sex)values ('tom9','1');
mysql> insert into test2.user(name,sex)values ('tom10','1');
mysql> insert into test2.user(name,sex)values ('tom11','1');
mysql> insert into test2.user(name,sex)values ('tom12','1');
mysql> insert into test2.user(name,sex)values ('tom13','1');
mysql> insert into test2.user(name,sex)values ('tom14','1');
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
到存放数据库表文件的地方看一下
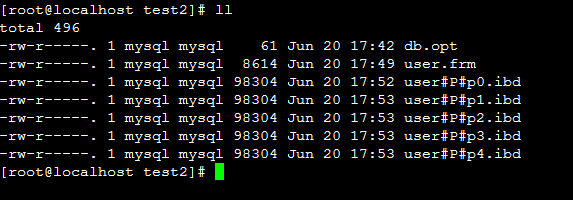
通过命令:
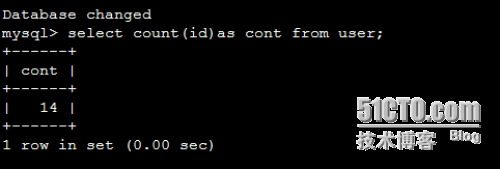
mysql> select count(id) as count from user;
- 1.
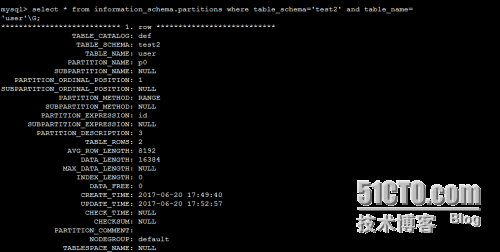
从information_schema系统库中的partitions表中查看分区信息
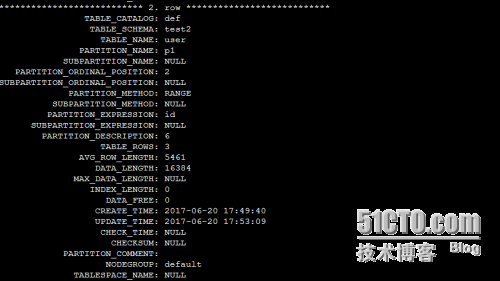
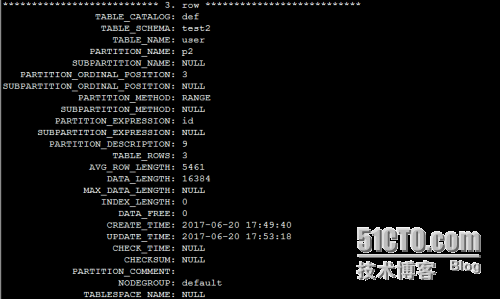
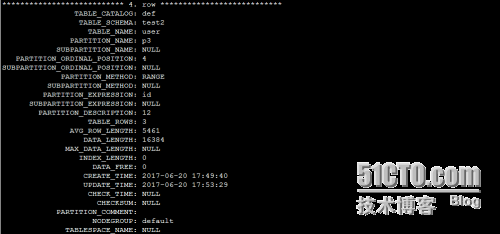
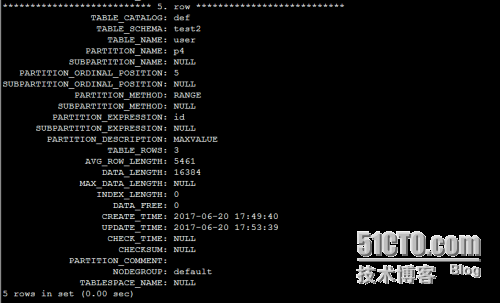
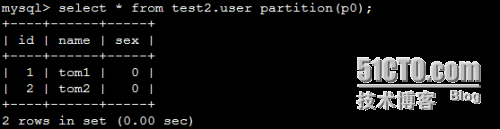
从某个分区中查询数据
mysql> select * from test2.user partition(p0);
- 1.
新增分区
mysql> alter table test2.user add partition (partition partionname values less than (n));
- 1.
使用此命令的时候需要的将p5删掉之后才可以进行新的增加
删除分区
当删除了一个分区,也同时删除了该分区中所有的数据。

分区的合并
下面的SQL,将p1 – p3合并为2个分区p01– p02
mysql> alter table test2.user
-> reorganize partition p1,p2,p3 into
-> (partition p01 values less than (8),
->partition p02 values less than (12)
-> );
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.