研究背景
阿里小蜜是阿里巴巴推出的围绕电商服务、导购以及任务助理为核心的智能人机交互产品,在去年双十一期间,阿里小蜜整体智能服务量达到643万,其中智能解决率达到95%,成为了双十一期间服务的绝对主力。阿里小蜜所使用的问答技术也在经历着飞速的发展,从最初基于检索的知识库问答演进到了***的语义深度建模。
近期,阿里小蜜正在开展新的探索,让机器具有如同人一般的阅读理解能力,这将使得问答产品体现出真正的智能,进一步提升服务效率。
在问答技术中,最常见的是检索式问答,但存在很多的限制,例如,需要人工进行知识提炼,让机器在事先准备好的问答对基础之上进行检索。而我们经常需要对这样一段话进行提问:
- 5月18日,阿里巴巴集团发布了2017财年Q4财报和2017财年全年的业绩报告。财报显示,阿里巴巴集团2017财年的收入为1582.73亿元人民币,同比增长56%;经调整后净利为578.71亿元人民币。Q4集团收入为385.79亿元,同比增长60%;非美国通用会计准则下的净利同比增长38%至104.4亿元人民币。
- Q:阿里巴巴2017财年收入是多少呢?
- A:1582.73亿人民币
其中包含很多的数字、日期、金额以及一些客观事实描述,如果对每个提问点都设置一个问答对,将会是非常繁琐的过程,同时,由于真实场景中问题的长尾性,人工提炼也无法穷尽所有可能的问题,知识往往覆盖率比较低。如果能脱离人工提炼知识的过程,直接让机器在非结构化文本内容中进行阅读理解,并回答用户的问题,将是一个里程碑式的进步。
深度学习近年来在自然语言处理领域中广泛应用,在机器阅读理解领域也是如此,深度学习技术的引入使得机器阅读理解能力在最近一年内有了大幅提高,因此我们尝试结合深度学习与真实业务场景,探索机器阅读在电商领域的创新与落地场景。
电商领域的应用场景
那么机器阅读理解及问答技术在电商领域会有哪些合适的应用场景呢?
阿里小蜜的交易规则解读类场景
首先是电商交易规则解读类场景,例如在每次双11等活动时,都会有大量的用户对活动规则进行咨询。以往,阿里小蜜的知识运营同学都需要提前研究淘宝和天猫上的活动规则,从一堆规则描述、活动介绍文本中提炼可能的问题。而通过机器阅读理解的运用,则可以让机器直接对规则进行阅读,为用户提供规则解读服务,是最自然的交互方式。
2016年淘宝双十一消费者交易规则
发货时间说明:
- 2016年11月11日00:00:00-2016年11月17日23:59:59期间付款成果的订单,确认收到时间如下:
- (1)如果选择的物流方式为快递与货运,自“卖家已发货”状态起的15天后,系统会自动确认收货。
- (2)如果选择物流方式为平邮,自“卖家已发货”状态起的30天后,系统会自动确认收货。
- 示例提问:我双十一买的东西什么时候会自动确认收货?
店小蜜的商品售前咨询场景
店小蜜是一款面向淘系千万商家的智能客服。用户在淘宝和天猫上购物时,往往会对较为关注的商品信息进行询问确认后才会下单购买,例如“荣耀5c的双摄像头拍照效果有什么特点?” 而这些信息往往已经存在于商品的详情描述页,通过机器阅读理解技术,可以让机器对详情页中的商品描述文本进行更为智能地阅读和回答,降低服务成本的同时提高购买转化率。
相关工作调研
基于知识库自动构建的机器阅读
用传统的自然语言处理方式完成基于机器阅读理解的问答,一般需要先在文本中进行实体和属性的解析,构建出结构化的知识图谱,并在知识图谱基础上进行问答。 主要涉及以下几个过程:
· 实体检测:识别文本中提及的实体,对实体进行分类。
· 实体链接:将检测出来的实体与知识库中现有实体进行匹配和链接。
· 属性填充:从文档中检测实体的各类预先定义好的属性,补充到知识库中。
· 知识检索:在知识库中根据实体和属性找到最相关的答案作为回答。
显然,用传统的知识库构建方式来进行机器阅读,虽然其可控性和可解释性较好,但领域垂直特点较强,难以适应多变的领域场景,且技术上需要分别解决多个传统NLP中的难点,如命名实体识别、指代消解、新词发现、同义词归一等,而每个环节都可能引入误差,使得整体误差逐渐扩大。
基于End-to-end的机器阅读
近年来,一些高质量的公开数据集为机器阅读领域的研究带来了革命性的变化,推动了基于End-to-end方法的高速进步,基于不同的数据集可以解决一些特定的机器阅读理解任务。以下首先介绍每一类中具有代表性的数据集。
- Facebook的bAbI推理型问答数据集
bAbI数据集是由人工构造的由若干简单事实形成的英文文章,给出文章和对应问题后,要求机器阅读理解文章内容并作出一定的推理,从而得出正确答案,往往是文章中的某个(或几个)关键词或者实体。
数据集包含对20个具体任务的评测,包括Supporting Fact、Yes/No Question、Counting、Time Reasoning、Position Reasoning、Path Finding等等。数据集规模相对比较小,仅由1000个训练数据和1000个测试数据构成,每个任务150个词。

- Microsoft的MCTest选择题数据集
MCTest数据集用于回答选择题,由真实的英文儿童读物构成。给出一篇150-300词的故事文章,并对故事内容进行提问,要求机器在几个候选答案中选出正确的答案。数据集的数据量较小,分为160篇和500篇两种。

- DeepMind的CNN\DailyMail完形填空数据集
该数据集来自于真实的新闻数据,但由自动标注而得,并非人工标注。给出一篇新闻和一个问句,把问句中的某个实体抽掉,要求能正确预测被抽掉的实体。这个实体必须是在文中出现过的。该数据集的数据量相对比较大,CNN9有万篇,DailyMail有22万篇。

- Facebook的CBT完形填空数据集
该数据集也是由真实的儿童读物,由自动标注方式构成,其形式是给出21个句子,前20个是完整的供机器阅读的句子,将第21个句子中的实体抽掉,要求能正确预测出来。

- 讯飞和哈工大的中文完形填空数据集
这是一份中文数据集,和CBT类似,这份数据集是根据真实的新闻数据由自动标注的方式获得的完形填空数据集,数据集较大,共有87万篇。

- Stanford的SQuAD可变长答案数据集
SQuAD是斯坦福发布的英文可变长答案数据集。问题和答案由大量众包人力来标注。内容主要以Wiki文章为主,涵盖了体育、政治、商业等各种领域的内容。数据集包含500多篇文章(在1000篇文章中随机选取,保证数据分布广泛),再将500多篇文章拆成了2万多个小段落,再对段落进行提问,共10万个问题(每个段落提5个以上的问题)。
每个问题需要由3位标注者进行标注,其中***位标注者需要提问和回答,后两位标注者只需回答***位标注者的提问。取第二位标注者的答案作为Human Predict, 取***、三位标注者的答案作为Ground Truth,以此获得多个Ground Truth来降低标注误差。且鼓励标注者用自己的语言来提问,不要去抄原文中的话。
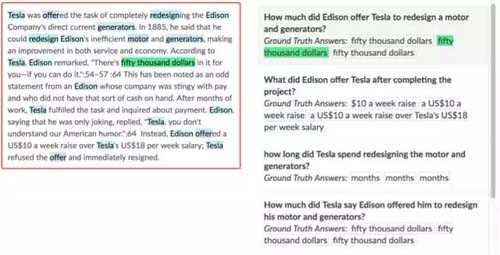
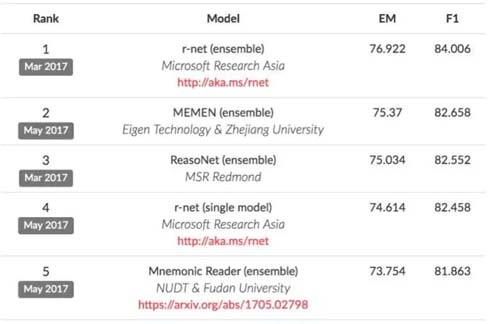
该数据集一经推出便引发学术界的持续关注,在SQuAD的Leadeboard上不断有新的模型提出一遍遍刷新benchmark,截止目前(2017年6月),***的方法已经获得超过84的F1值。值得一提的是,Standford在推出该数据集时,基于传统Lexical特征工程的方式构造了Baseline(考虑Word/POS/Dependency..),作为白盒模型有较好的比较意义,同时也提供了人工评测的Acc作参照,方便衡量问题上界。
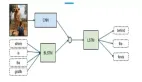
几乎所有围绕SQuAD的模型都可以概括为类似的结构:
(1)Embedding层:将原文和问题中的词汇映射为向量表示。
(2)Encoding层:用RNN对原文和问题进行编码,使得每个词蕴含上下文语义信息。
(3)Interaction层:用于捕捉问题和原文之间的交互关系,并输出编码了问题语义信息的query-aware的原文表示。
(4)Answer层:基于query-aware的原文表示来预测答案开始和结束的位置。
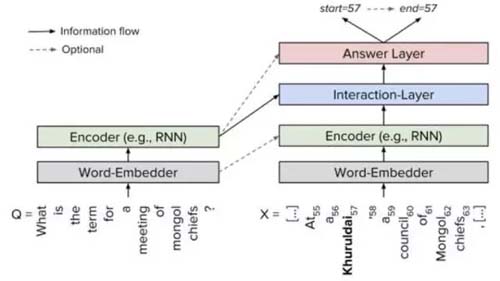
显然,SQuAD数据集相比之前的完形填空、选择题型数据集来说,数据量更大、数据质量更高、解决的问题也更复杂,同时也更接近于真实的业务场景,因为在大部分的真实问答场景中,答案都并非单个实体,很可能是一个短句,因此我们将主要围绕SQuAD LeaderBoard上榜的模型来作一些具体的介绍。
基于SQuAD的机器阅读模型
- Match-LSTM with AnswerPointer
Match-LSTMwith Answer Pointer模型是较早登上SQuAD LeaderBoard的模型,作者提出了融合 match-lstm 和 pointer-network 的机器阅读框架,后续也被多篇相关工作所借鉴。其中的Boundary Model由于只预测答案开始和结束位置,极大地缩小了搜索答案的空间,使得整个预测过程得到了简化。
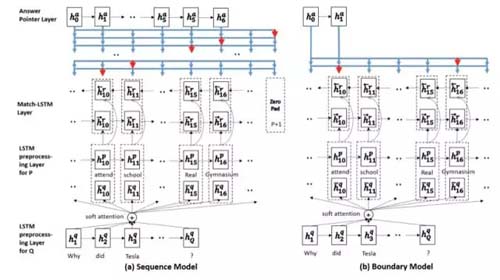
模型主要包括三个部分:
(1)用LSTM分别对question和passage进行encoding;
(2)用match-LSTM对question和passage进行match。这里将question当做premise,将
passage当做hypothesis,用标准的word-by-word attention得到attention向量,然后对question的隐层输出进行加权,并将其跟passage的隐层输出进行拼接,得到一个新的向量,然后输入到LSTM;
(3)利用pointer net从passage中选择tokens作为答案。包括Sequence Model和Boundary Model。其中Sequence Model是在passage中选择不连续的word作为answer;BoundaryModel只需要passage的起始位置和中止位置得到连续的words作为answer。
Bidirectional AttentionFlow
BiDAF模型***的特点是在interaction层引入了双向注意力机制,计算Query2Context和Context2Query两种注意力,并基于注意力计算query-aware的原文表示。
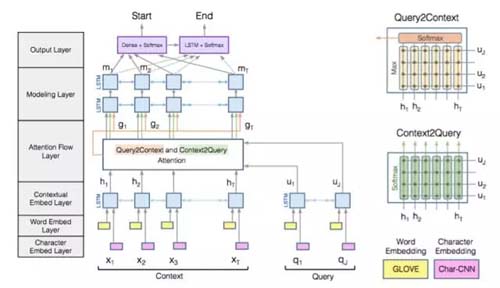
模型由这样几个层次组成:
(1)Character Embedding Layer使用char-CNN将word映射到固定维度的向量空间;
(2)Word Embedding Layer使用(pre-trained)word embedding将word映射到固定维度的向量空间;
(3)Contextual Embedding Layer将上面的到的两个word vector拼接,然后输入LSTM中进行context embedding;
(4)Attention Flow Layer将passage embedding和question embedding结合,使用Context-to-query Attention 和Query-to-contextAttention得到word-by-word attention;
(5)Modeling Layer将上一层的输出作为bi-directional RNN的输入,得到Modeling结果M;
(6)Output Layer使用M分类得到passage的起始位置,然后使用M输入bi-directional LSTM得到M2,再使用M2分类得到passage的中止位置作为answer。
FastQAExt
FastQAExt***的特点在于其较为轻量级的网络结构,在输入的embedding层加入了两个简单的统计特征:
(1)文章中的词是否出现在问题中,是一个binary特征。
(2)基于“问题中的词如果在原文中很少出现,则对问题的回答影响更大”的原理,设计了一个weighted特征。
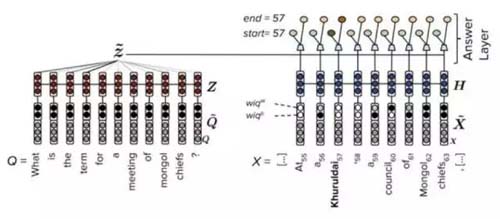
2个统计特征的引入相当于给模型提前提供了先验知识,这将加快模型的收敛速度,整体上,FastQAExt由以下三个部分组成:
(1)Embedding层:word 和char 两种embedding,且拼接上述的2种统计特征作为输入向量。
(2)Encoding层:汇总原文和问题的总表示。
(3)Answer层:计算问题对总表示,将query-aware原文表示和问题总表示共同输入两个前馈网络产生答案开始和结束位置概率。
r-net
r-net是目前在SQuAD LeaderBoard上排名领先的模型,r-net的特点是使用了双interaction层架构。
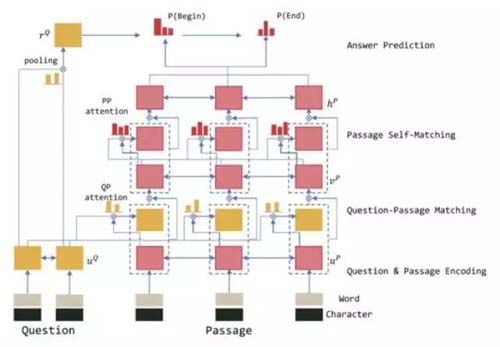
r-net由以下三个部分组成:
(1)Encoding层:使用word和char两种Embedding作为输入。
(2)Question-Passage Matching层:负责捕捉原文和问题之间的交互信息。
(3)Passage Self-Matching层:负责捕捉原文内部各词之间的交互信息。
(4)Answer层:借鉴了match-lstm及pointer network的思路来预测答案的开始和结束位置,并在问题表示上用attention-pooling来生成pointer network的初始状态。
业务场景下的挑战与实践
通过上述介绍可以看到,围绕SQuAD数据集的机器阅读理解模型已经在学术界取得了相当大的突破,其解决的问题是在一定长度的wiki内容中进行知识问答,然而阿里小蜜的实际电商业务场景与之相比篇章更长、答案粒度更粗(业务场景下句子粒度居多)、业务含义更复杂且用户的提问更为随意,因此SQuAD数据集及其相关模型还不能直接运用于解决我们实际的电商场景问题。
要将机器阅读理解技术运用到实际业务场景中,还存在相当大到挑战,我们在以下几方面进行了探索和实践:
- 中文数据集的构建
为了使得模型能解决特定的业务问题,标注一个高质量的业务数据集是必不可少的,然而人工标注的成本较高,因此在业务数据集之外,需要将公开的数据集进行结合利用。而目前公开的中文数据集较为缺乏,可以通过批量翻译等方式快速构造中文数据集,翻译得到的结果由于保持了词汇及大致的上下文信息,也能取得一定的训练效果。
- 模型的业务优化
需要改进模型的结构设计,使得模型可以支持电商文档格式的输入。电商规则文档往往包含大量的文档结构,如大小标题和文档的层级结构等,将这些特定的篇章结构信息一起编码输入到网络中,将大幅提升训练的效果。
- 模型的简化
学术成果中的模型一般都较为复杂,而工业界场景中由于对性能的要求,无法将这些模型直接在线上使用,需要做一些针对性的简化,使得模型效果下降可控的情况下,尽可能提升线上预测性能。例如可以简化模型中的各种bi-lstm结构。
- 多种模型的融合
当前这些模型都是纯粹的end-to-end模型,其预测的可控性和可解释性较低,要适用于业务场景的话,需要考虑将深度学习模型与传统模型进行融合,达到智能程度和可控性的***平衡点。
- 总结
机器阅读理解是当下自然语言处理领域的一个热门任务。近年来,各类阅读理解的数据集以及方法层出不穷,尤其是围绕SQuAD数据集的模型正在快速的发展中,这些模型的研究在学术界非常活跃。总的来说,对于解决wiki类客观知识问答已经取得比较好的结果,但对于复杂问题来说仍处于比较初级的阶段。
学术界的思路和工业界实际场景相结合将能产生巨大的价值,阿里小蜜已经在这方面开展探索和落地的尝试,在算法、模型和数据方面进行积累和沉淀,未来在更多的真实领域场景中,用户将能感受到机器阅读理解技术带来的更为便利的智能服务。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】