












前言
文本分类应该是自然语言处理中最普遍的一个应用,例如文章自动分类、邮件自动分类、垃圾邮件识别、用户情感分类等等,在生活中有很多例子,这篇文章主要从传统和深度学习两块来解释下我们如何做一个文本分类器。
文本分类方法
传统的文本方法的主要流程是人工设计一些特征,从原始文档中提取特征,然后指定分类器如LR、SVM,训练模型对文章进行分类,比较经典的特征提取方法如频次法、tf-idf、互信息方法、N-Gram。
深度学习火了之后,也有很多人开始使用一些经典的模型如CNN、LSTM这类方法来做特征的提取, 这篇文章会比较粗地描述下,在文本分类的一些实验
传统文本分类方法
这里主要描述两种特征提取方法:频次法、tf-idf、互信息、N-Gram。
频次法
频次法,顾名思义,十分简单,记录每篇文章的次数分布,然后将分布输入机器学习模型,训练一个合适的分类模型,对这类数据进行分类,需要指出的时,在统计次数分布时,可合理提出假设,频次比较小的词对文章分类的影响比较小,因此我们可合理地假设阈值,滤除频次小于阈值的词,减少特征空间维度。
TF-IDF
TF-IDF相对于频次法,有更进一步的考量,词出现的次数能从一定程度反应文章的特点,即TF,而TF-IDF,增加了所谓的反文档频率,如果一个词在某个类别上出现的次数多,而在全部文本上出现的次数相对比较少,我们认为这个词有更强大的文档区分能力,TF-IDF就是综合考虑了频次和反文档频率两个因素。
互信息方法
互信息方法也是一种基于统计的方法,计算文档中出现词和文档类别的相关程度,即互信息
N-Gram
基于N-Gram的方法是把文章序列,通过大小为N的窗口,形成一个个Group,然后对这些Group做统计,滤除出现频次较低的Group,把这些Group组成特征空间,传入分类器,进行分类。
深度学习方法
基于CNN的文本分类方法
- 最普通的基于CNN的方法就是Keras上的example做情感分析,接Conv1D,指定大小的window size来遍历文章,加上一个maxpool,如此多接入几个,得到特征表示,然后加上FC,进行最终的分类输出。
- 基于CNN的文本分类方法,最出名的应该是2014 Emnlp的 Convolutional Neural Networks for Sentence Classification,使用不同filter的cnn网络,然后加入maxpool, 然后concat到一起。
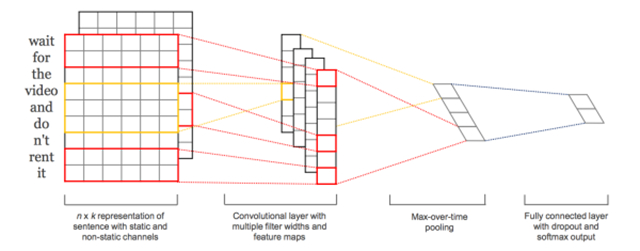
- 这类CNN的方法,通过设计不同的window size来建模不同尺度的关系,但是很明显,丢失了大部分的上下文关系,Recurrent Convolutional Neural Networks for Text Classification,将每一个词形成向量化表示时,加上上文和下文的信息,每一个词的表示如下:
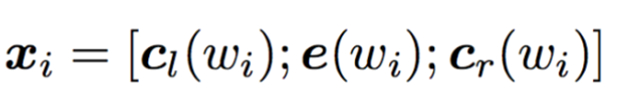
整个结构框架如下:
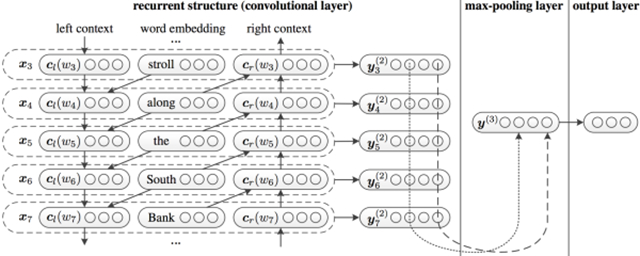
- 如针对这句话”A sunset stroll along the South Bank affords an array of stunning vantage points”,stroll的表示包括c_l(stroll),pre_word2vec(stroll),c_r(stroll), c_l(stroll)编码A sunset的语义,而c_r(stroll)编码along the South Bank affords an array of stunning vantage points的信息,每一个词都如此处理,因此会避免普通cnn方法的上下文缺失的信息。
基于LSTM的方法
- 和基于CNN的方法中***种类似,直接暴力地在embedding之后加入LSTM,然后输出到一个FC进行分类,基于LSTM的方法,我觉得这也是一种特征提取方式,可能比较偏向建模时序的特征;
- 在暴力的方法之上,A C-LSTM Neural Network for Text Classification,将embedding输出不直接接入LSTM,而是接入到cnn,通过cnn得到一些序列,然后吧这些序列再接入到LSTM,文章说这么做会提高***分类的准去率。
代码实践
语料及任务介绍
训练的语料来自于大概31个新闻类别的新闻语料,但是其中有一些新闻数目比较少,所以取了数量比较多的前20个新闻类比的新闻语料,每篇新闻稿字数从几百到几千不等,任务就是训练合适的分类器然后将新闻分为不同类别:

Bow
Bow对语料处理,得到tokens set:
- def __get_all_tokens(self):
- """ get all tokens of the corpus
- """
- fwrite = open(self.data_path.replace("all.csv","all_token.csv"), 'w')
- with open(self.data_path, "r") as fread:
- i = 0
- # while True:
- for line in fread.readlines():
- try:
- line_list = line.strip().split("\t")
- label = line_list[0]
- self.labels.append(label)
- text = line_list[1]
- text_tokens = self.cut_doc_obj.run(text)
- self.corpus.append(' '.join(text_tokens))
- self.dictionary.add_documents([text_tokens])
- fwrite.write(label+"\t"+"\\".join(text_tokens)+"\n")
- i+=1
- except BaseException as e:
- msg = traceback.format_exc()
- print msg
- print "=====>Read Done<======"
- break
- self.token_len = self.dictionary.__len__()
- print "all token len "+ str(self.token_len)
- self.num_data = i
- fwrite.close()
然后,tokens set 以频率阈值进行滤除,然后对每篇文章做处理来进行向量化:
- def __filter_tokens(self, threshold_num=10):
- small_freq_ids = [tokenid for tokenid, docfreq in self.dictionary.dfs.items() if docfreq < threshold_num ]
- self.dictionary.filter_tokens(small_freq_ids)
- self.dictionary.compactify()
- def vec(self):
- """ vec: get a vec representation of bow
- """
- self.__get_all_tokens()
- print "before filter, the tokens len: {0}".format(self.dictionary.__len__())
- self.__filter_tokens()
- print "After filter, the tokens len: {0}".format(self.dictionary.__len__())
- self.bow = []
- for file_token in self.corpus:
- file_bow = self.dictionary.doc2bow(file_token)
- self.bow.append(file_bow)
- # write the bow vec into a file
- bow_vec_file = open(self.data_path.replace("all.csv","bow_vec.pl"), 'wb')
- pickle.dump(self.bow,bow_vec_file)
- bow_vec_file.close()
- bow_label_file = open(self.data_path.replace("all.csv","bow_label.pl"), 'wb')
- pickle.dump(self.labels,bow_label_file)
- bow_label_file.close()
最终就得到每篇文章的bow的向量,由于这块的代码是在我的笔记本上运行的,直接跑占用内存太大,因为每一篇文章在token set中的表示是极其稀疏的,因此我们可以选择将其转为csr表示,然后进行模型训练,转为csr并保存中间结果代码如下:
- def to_csr(self):
- self.bow = pickle.load(open(self.data_path.replace("all.csv","bow_vec.pl"), 'rb'))
- self.labels = pickle.load(open(self.data_path.replace("all.csv","bow_label.pl"), 'rb'))
- data = []
- rows = []
- cols = []
- line_count = 0
- for line in self.bow:
- for elem in line:
- rows.append(line_count)
- cols.append(elem[0])
- data.append(elem[1])
- line_count += 1
- print "dictionary shape ({0},{1})".format(line_count, self.dictionary.__len__())
- bow_sparse_matrix = csr_matrix((data,(rows,cols)), shape=[line_count, self.dictionary.__len__()])
- print "bow_sparse matrix shape: "
- print bow_sparse_matrix.shape
- # rarray=np.random.random(size=line_count)
- self.train_set, self.test_set, self.train_tag, self.test_tag = train_test_split(bow_sparse_matrix, self.labels, test_size=0.2)
- print "train set shape: "
- print self.train_set.shape
- train_set_file = open(self.data_path.replace("all.csv","bow_train_set.pl"), 'wb')
- pickle.dump(self.train_set,train_set_file)
- train_tag_file = open(self.data_path.replace("all.csv","bow_train_tag.pl"), 'wb')
- pickle.dump(self.train_tag,train_tag_file)
- test_set_file = open(self.data_path.replace("all.csv","bow_test_set.pl"), 'wb')
- pickle.dump(self.test_set,test_set_file)
- test_tag_file = open(self.data_path.replace("all.csv","bow_test_tag.pl"), 'wb')
- pickle.dump(self.test_tag,test_tag_file)
***训练模型代码如下:
- def train(self):
- print "Beigin to Train the model"
- lr_model = LogisticRegression()
- lr_model.fit(self.train_set, self.train_tag)
- print "End Now, and evalution the model with test dataset"
- # print "mean accuracy: {0}".format(lr_model.score(self.test_set, self.test_tag))
- y_pred = lr_model.predict(self.test_set)
- print classification_report(self.test_tag, y_pred)
- print confusion_matrix(self.test_tag, y_pred)
- print "save the trained model to lr_model.pl"
- joblib.dump(lr_model, self.data_path.replace("all.csv","bow_lr_model.pl"))
TF-IDF
TF-IDF和Bow的操作十分类似,只是在向量化使使用tf-idf的方法:
- def vec(self):
- """ vec: get a vec representation of bow
- """
- self.__get_all_tokens()
- print "before filter, the tokens len: {0}".format(self.dictionary.__len__())
- vectorizer = CountVectorizer(min_df=1e-5)
- transformer = TfidfTransformer()
- # sparse matrix
- self.tfidf = transformer.fit_transform(vectorizer.fit_transform(self.corpus))
- words = vectorizer.get_feature_names()
- print "word len: {0}".format(len(words))
- # print self.tfidf[0]
- print "tfidf shape ({0},{1})".format(self.tfidf.shape[0], self.tfidf.shape[1])
- # write the tfidf vec into a file
- tfidf_vec_file = open(self.data_path.replace("all.csv","tfidf_vec.pl"), 'wb')
- pickle.dump(self.tfidf,tfidf_vec_file)
- tfidf_vec_file.close()
- tfidf_label_file = open(self.data_path.replace("all.csv","tfidf_label.pl"), 'wb')
- pickle.dump(self.labels,tfidf_label_file)
- tfidf_label_file.close()
这两类方法效果都不错,都能达到98+%的准确率。
CNN
语料处理的方法和传统的差不多,分词之后,使用pretrain 的word2vec,这里我遇到一个坑,我开始对我的分词太自信了,***模型一直不能收敛,后来向我们组博士请教,极有可能是由于分词的词序列中很多在pretrained word2vec里面是不存在的,而我这部分直接丢弃了,所有可能存在问题,分词添加了词典,然后,对于pre-trained word2vec不存在的词做了一个随机初始化,然后就能收敛了,学习了!!!
载入word2vec模型和构建cnn网络代码如下(增加了一些bn和dropout的手段):
- def gen_embedding_matrix(self, load4file=True):
- """ gen_embedding_matrix: generate the embedding matrix
- """
- if load4file:
- self.__get_all_tokens_v2()
- else:
- self.__get_all_tokens()
- print "before filter, the tokens len: {0}".format(
- self.dictionary.__len__())
- self.__filter_tokens()
- print "after filter, the tokens len: {0}".format(
- self.dictionary.__len__())
- self.sequence = []
- for file_token in self.corpus:
- temp_sequence = [x for x, y in self.dictionary.doc2bow(file_token)]
- print temp_sequence
- self.sequence.append(temp_sequence)
- self.corpus_size = len(self.dictionary.token2id)
- self.embedding_matrix = np.zeros((self.corpus_size, EMBEDDING_DIM))
- print "corpus size: {0}".format(len(self.dictionary.token2id))
- for key, v in self.dictionary.token2id.items():
- key_vec = self.w2vec.get(key)
- if key_vec is not None:
- self.embedding_matrix[v] = key_vec
- else:
- self.embedding_matrix[v] = np.random.rand(EMBEDDING_DIM) - 0.5
- print "embedding_matrix len {0}".format(len(self.embedding_matrix))
- def __build_network(self):
- embedding_layer = Embedding(
- self.corpus_size,
- EMBEDDING_DIM,
- weights=[self.embedding_matrix],
- input_length=MAX_SEQUENCE_LENGTH,
- trainable=False)
- # train a 1D convnet with global maxpooling
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH, ), dtype='int32')
- embedded_sequences = embedding_layer(sequence_input)
- x = Convolution1D(128, 5)(embedded_sequences)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = MaxPooling1D(5)(x)
- x = Convolution1D(128, 5)(x)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = MaxPooling1D(5)(x)
- print "before 256", x.get_shape()
- x = Convolution1D(128, 5)(x)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = MaxPooling1D(15)(x)
- x = Flatten()(x)
- x = Dense(128)(x)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = Dropout(0.5)(x)
- print x.get_shape()
- preds = Dense(self.class_num, activation='softmax')(x)
- print preds.get_shape()
- adam = Adam(lr=0.0001)
- self.model = Model(sequence_input, preds)
- self.model.compile(
- loss='categorical_crossentropy', optimizer=adam, metrics=['acc'])
另外一种网络结构,韩国人那篇文章,网络构造如下:
- def __build_network(self):
- embedding_layer = Embedding(
- self.corpus_size,
- EMBEDDING_DIM,
- weights=[self.embedding_matrix],
- input_length=MAX_SEQUENCE_LENGTH,
- trainable=False)
- # train a 1D convnet with global maxpooling
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH, ), dtype='int32')
- embedded_sequences = embedding_layer(sequence_input)
- conv_blocks = []
- for sz in self.filter_sizes:
- conv = Convolution1D(
- self.num_filters,
- sz,
- activation="relu",
- padding='valid',
- strides=1)(embedded_sequences)
- conv = MaxPooling1D(2)(conv)
- conv = Flatten()(conv)
- conv_blocks.append(conv)
- z = Merge(
- conv_blocks,
- mode='concat') if len(conv_blocks) > 1 else conv_blocks[0]
- z = Dropout(0.5)(z)
- z = Dense(self.hidden_dims, activation="relu")(z)
- preds = Dense(self.class_num, activation="softmax")(z)
- rmsprop = RMSprop(lr=0.001)
- self.model = Model(sequence_input, preds)
- self.model.compile(
- loss='categorical_crossentropy',
- optimizer=rmsprop,
- metrics=['acc'])
LSTM
由于我这边的task是对文章进行分类,序列太长,直接接LSTM后直接爆内存,所以我在文章序列直接,接了两层Conv1D+MaxPool1D来提取维度较低的向量表示然后接入LSTM,网络结构代码如下:
- def __build_network(self):
- embedding_layer = Embedding(
- self.corpus_size,
- EMBEDDING_DIM,
- weights=[self.embedding_matrix],
- input_length=MAX_SEQUENCE_LENGTH,
- trainable=False)
- # train a 1D convnet with global maxpooling
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH, ), dtype='int32')
- embedded_sequences = embedding_layer(sequence_input)
- x = Convolution1D(
- self.num_filters, 5, activation="relu")(embedded_sequences)
- x = MaxPooling1D(5)(x)
- x = Convolution1D(self.num_filters, 5, activation="relu")(x)
- x = MaxPooling1D(5)(x)
- x = LSTM(64, dropout_W=0.2, dropout_U=0.2)(x)
- preds = Dense(self.class_num, activation='softmax')(x)
- print preds.get_shape()
- rmsprop = RMSprop(lr=0.01)
- self.model = Model(sequence_input, preds)
- self.model.compile(
- loss='categorical_crossentropy',
- optimizer=rmsprop,
- metrics=['acc'])
CNN 结果:
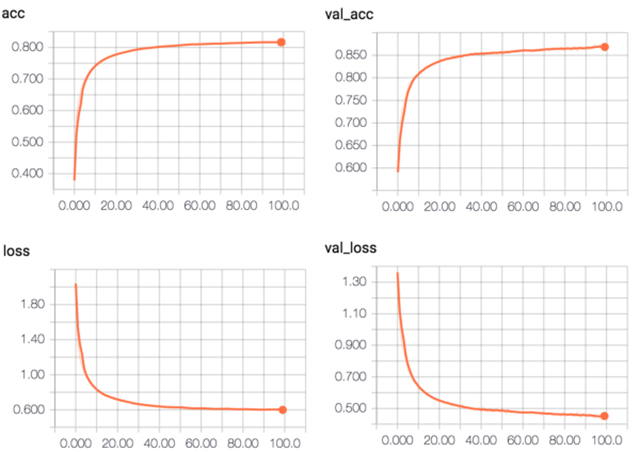
C-LSTM 结果:
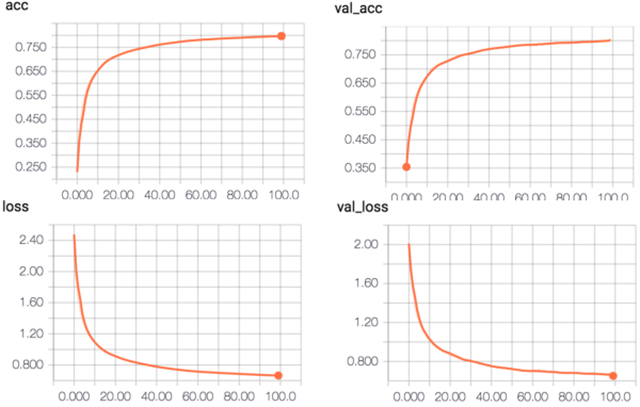
整个实验的结果由于深度学习这部分都是在公司资源上跑的,没有真正意义上地去做一些trick来调参来提高性能,这里所有的代码的网络配置包括参数都仅做参考,更深地工作需要耗费更多的时间来做参数的优化。
PS: 这里发现了一个keras 1.2.2的bug, 在写回调函数TensorBoard,当histogram_freq=1时,显卡占用明显增多,M40的24g不够用,个人感觉应该是一个bug,但是考虑到1.2.2而非2.0,可能后面2.0都优化了。
所有的代码都在github上:tensorflow-101/nlp/text_classifier/scripts
总结和展望
在本文的实验效果中,虽然基于深度学习的方法和传统方法相比没有什么优势,可能原因有几个方面:
- Pretrained Word2vec Model并没有覆盖新闻中切分出来的词,而且比例还挺高,如果能用网络新闻语料训练出一个比较精准的Pretrained Word2vec,效果应该会有很大的提升;
- 可以增加模型训练收敛的trick以及优化器,看看是否有准确率的提升;
- 网络模型参数到现在为止,没有做过深的优化。



















