【51CTO.com原创稿件】随着公司规模的发展,数据量呈递增式爆棚,他也见证了基础数据平台从无到有、从小到大的历程。头条在这一发展过程中对于数据使用及难度都经历了数量级的变化。本文将与大家分享数据平台经历的各种坑及一些重要的技术决策。
基础数据平台的建设历程
为什么要建设基础数据平台?
对于初创公司来讲,核心是服务好用户,做好产品功能的迭代。当公司发展到一定阶段,业务开始多元化并开始精细化运营,数据需求变多,产生的数据量和数据处理复杂度也大幅增加,这时就该建设基础数据平台了。
2014 年,头条每天只有几百万活跃用户,支撑好产品是首要任务,并没有专门的人负责做数据。众多复杂业务的上线,同步会招聘大量的 PM(产品经理)和运营。基于刻到骨子里的数据驱动的思想,各种各样的数据需求源源不断的被提上来,这时不再是几个数据工程师单打独斗就能解决问题了,而让PM 和运营直接分析数据的门槛也很高。
面对这些情况,头条的做法是成立数据平台团队,把数据基础设施像 Hadoop、Hive、Spark、Kylin 等封装成工具,把这些工具结合通用的分析模式整合成完整的解决方案,再把这些解决方案通过平台的形式,提供给业务部门使用。
这里需要注意数据平台的发展是一个演进的过程,并不需要追求一开始就大而全,不同阶段采用的技术能匹配当时需求就好。
基础数据平台的职责什么?
数据平台的需求最初来自推荐业务,从用户的阅读需求出发,搭建面向全公司的通用数据平台。其中,用户数据(内容偏爱、行为轨迹、阅读时间等)是头条最庞大的数据源,这些被记录下来的数据反映了用户的兴趣,会以各种形式传输和存储,并提供给全公司各个业务系统来调用。
还要维护面向 RD(分析师)数据工具集(日志收集、入库、调度、依赖管理、查询、元数据、报表),面向 PM、运营的通用用户行为分析平台,底层查询引擎(Hive,Presto,Kylin 等 OLAP 查询引擎,支撑上层数据平台和数据仓库),平台基础数据仓库及协助维护业务部门数据仓库。
面临哪些挑战?
当前,头条每日处理数据量为 7.8 PB、训练样本量 200 亿条、服务器总量 40000 台、Hadoop 节点 3000 台。
数据生命周期分为生成、传输、入库和统计/分析/挖掘,每个环节的难度都会随着数据规模的变大而上升。平台建设面临的挑战是由庞大的数据量和业务复杂度给数据生成、采集、传输、存储和计算等带来的一系列问题。
(1)数据生成与采集——SDK、用户埋点
一般情况下,数据生成与采集是很简单的事,但对于头条这个功能众多的 APP 来讲,难点就在于每个功能背后都是一个团队独立运营。如果每个团队都用自研的数据采集方法,那会给后续的进程带来巨大的困扰。
怎么办呢?因为头条属于 C 端业务公司,主要以日志形式为主,数据的主要来源是用户行为,那么就采用事件模型来描述日志,以 SDK 形式接入,支持客户端、服务端埋点。
这里需要注意的是:数据质量很重要,埋点规范趁早确立,脏数据是不可避免的,可以引入必要的约束、清洗等。
- 埋点。埋点是用户在使用某一个功能时,产生的一段数据。头条初期,埋点由各业务场景自定义日志格式,之后埋点统一到事件模型,保证了信息的结构化和自描述,降低了后续使用成本,并复用统一的解析和清洗流程、数据仓库的入库和行为分析平台的导入。
埋点的管理,也由通过文档、Wiki 等方式演进成埋点管理系统,覆盖整个埋点生命周期。这样一来,也得到了埋点元信息的描述,后续可应用在数据清洗、分析平台等场景,同时埋点的上线流程实现标准化,客户端也可进行自动化测试。
SDK。数据平台实现了通用的客户端埋点 SDK 和服务端埋点 SDK,放弃之前按约定生成数据的方式,可以保证生成的日志符合埋点规范,并统一 App 启动、设备标识等的基本口径,也减少了新 App 适配成本。
对数据的描述由使用 JSON 改为 Protobuf,这样就可通过 IDL 实现强制约束,包括数据类型、字段命名等。
除了日志数据,关系数据库中的数据也是数据分析的重要来源。头条在数据的采集方式上,用 Spark 实现类 Sqoop 的分布式抓取替代了早期定期用单机全量抓取 MySQL 数据表的方式,有效的提升了抓取速度,突破了单机瓶颈。
再之后为了减少 MySQL 压力,选用 Canal 来接收 MySQL binlog,离线 merge 出全量表,这样就不再直接读 MySQL 了,而且对千万/亿级大表的处理速度也会更快。
(2)数据传输——Kafka 做消息总线连接在线和离线系统
数据在客户端向服务端回传或者直接在服务端产生时,可以认为是在线状态。当数据落地到统计分析相关的基础设施时,就变成离线的状态了。在线系统和离线系统采用消息队列来连接。
头条的数据传输以 Kafka 作为数据总线,所有实时和离线数据的接入都要通过 Kafka,包括日志、binlog 等。这里值得注意的是:尽早引入消息队列,与业务系统解耦。
头条的数据基础设施以社区开源版本作为基础,并做了大量的改进,也回馈给了社区,同时还有很多自研的组件。
因为以目前的数据和集群规模,直接使用社区版本乃至企业版的产品,都会遇到大量困难。像数据接入,就使用自研 Databus,作为单机 Agent,封装 Kafka 写入,提供异步写入、buffer、统一配置等 feature。
Kafka 数据通过 Dump 落地到 HDFS,供后续离线处理使用。随着数据规模的增加,Dump 的实现也经历了几个阶段。最初实现用的是类似 Flume 模式的单机上传,很快遇到了瓶颈,实现改成了通过 Storm 来实现多机分布式的上传,支持的数据吞吐量大幅增加。
现在开发了一个叫 DumpService 的服务,作为托管服务方便整合到平台工具上,底层实现切换到了 SparkStreaming,并实现了 exactly-once 语义,保证 Dump 数据不丢不重。
(3)数据入库——数据仓库、ETL(抽取转换加载)
头条的数据源很复杂,直接拿来做分析并不方便。但是到数据仓库这一层级,会通过数据处理的过程,也就是 ETL,把它建设成一个层次完备的适合分析的一个个有价值的数仓。在数仓之上,就可以让数据分析师和数据 RD 通过 SQL 和多维分析等更高效的手段使用数据。
数据仓库中数据表的元信息都放在 Hivemetastore 里,数据表在 HDFS 上的存储格式以 Parquet 为主,这是一种列式存储格式,对于嵌套数据结构的支持也很好。
头条有多种 ETL 的实现模式在并存,对于底层数据构建,一种选择是使用 Python 通过 HadoopStreaming 来实现 Map Reduce 的任务,但现在更倾向于使用 Spark 直接生成 Parquet 数据,Spark 相比 MapReduce 有更丰富的处理原语,代码实现可以更简洁,也减少了中间数据的落地量。对于高层次的数据表,会直接使用 HiveSQL 来描述 ETL 过程。
(4)数据计算——计算引擎的演进
数据仓库中的数据表如何能被高效的查询很关键,因为这会直接关系到数据分析的效率。常见的查询引擎可以归到三个模式中,Batch 类、MPP 类、Cube 类,头条在 3 种模式上都有所应用。
头条最早使用的查询引擎是 InfoBright,Infopight 可以认为是支持了列式存储的 MySQL,对分析类查询更友好,但 Infopight 只支持单机。随着数据量的增加,很快换成了 Hive,Hive 是一个很稳定的选择,但速度一般。
为了更好的支持 Adhoc 交互式查询,头条开始调研 MPP 类查询引擎,先后使用过 Impala 和 Presto,但在头条的数据量级下都遇到了稳定性的问题。
头条现在的方案是混合使用 Spark SQL 和 Hive,并自研 QAP 查询分析系统,自动分析并分发查询 SQL 到适合的查询引擎。在 Cube 类查询引擎上,头条采用了 Kylin,现在也是 Kylin 在国内***的用户之一。
(5)数据门户——为业务的数据分析提供整体解决方案
对于大部分需求相对简单的公司来说,数据最终可以产出报表就够用了,如做一个面向管理层的报表,可以让老板直观的了解一些关键性指标,这是最基础的数据应用模式。
再深入一点,就需要汇总各种来源的业务数据,提供多种维度和指标来进行更深入的探索型分析,得到的结论用来指导产品的迭代和运营。头条绝大部分业务都是数据驱动的,都需要产出和分析大量的数据,这就或多或少需要用到平台提供的系列工具。
头条开发了一套叫数据门户的平台系统,提供给业务部门使用,对数据生命周期各个环节都提供了相应支持。数据门户提供的工具都是声明式的,也就是让使用者只需要说明要实现什么目的,具体实现的复杂细节都隐藏起来,对使用者更友好。
通过这些工具,可以让业务部门的 RD 、分析师、PM 等将精力放在业务分析本身,而不是去学习大量数据基础设施的使用方法。
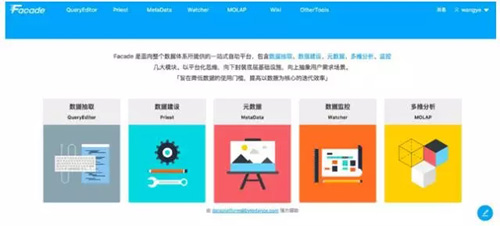
数据抽取平台 QueryEditor
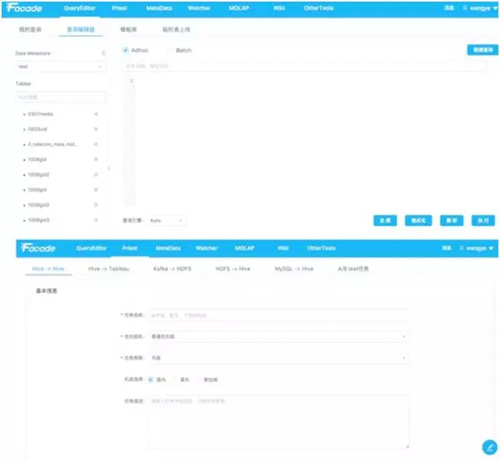
数据抽取平台 QueryEdito 使用界面
数据抽取平台 QueryEditor,用于数据生命周期管理,对 Kafka 数据 Dump、数据仓库入库、SQL 查询托管等做了统一支持。
结语
基础数据平台的建设理念是通过提供整体解决方案,降低数据使用门槛,方便各种业务接入。互联网产品的数据分析模式也是相对固定的,比如事件多维分析、留存分析、漏斗分析等,把这些分析模式抽象出工具,也能覆盖住大部分常用需求。
同时,期望参与业务的人比如 PM 等能更直接的掌握数据,通过相关工具的支持自行实现数据需求,尽量解放业务部门工程师的生产力,不至于被各种临时跑数需求困扰。而对于更专业的数据分析师的工作,也会提供更专业的工具支持。
王烨
今日头条数据平台架构师
2014 年加入今日头条,目前负责头条基础数据平台的技术架构,解决海量数据规模下推荐系统和用户产品的统计分析问题,并见证了头条数据平台从无到有、从小到大的历程。加入头条前,曾就职于豆瓣负责 Antispam 系统的研发。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】