当前BAT基本公开了其大数据平台架构,从网上也能查询到一些资料,关于大数据平台的各类技术介绍也不少,但在那个机制、那个环境、那个人才、那个薪酬体系下,对于传统企业,可借鉴的东西也是有限的。
技术最终为业务服务,没必要一定要追求先进性,各个企业应根据自己的实际情况去选择自己的技术路径。
与传统的更多从技术的角度来看待大数据平台架构的方式不同,笔者这次,更多的从业务的视角来谈谈关于大数据架构的理解,即更多的会问为什么要采用这个架构,到底能给业务带来多大价值,实践的最终结果是什么。
它不一定具有通用性,但从一定程度讲,这个架构可能比BAT的架构更适应大多数企业的情况,毕竟,大多数企业,数据没到那个份上,也不可能完全自研,商业和开源的结合可能更好一点,权当抛砖引玉。
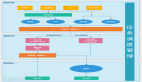
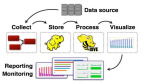
大数据平台架构的层次划分没啥标准,以前笔者曾经做过大数据应用规划,也是非常纠结,因为应用的分类也是横纵交错,后来还是觉得体现一个“能用”原则,清晰且容易理解,能指导建设,这里将大数据平台划分为“五横一纵”。
具体见下图示例,这张图是比较经典的,也是妥协的结果,跟当前网上很多的大数据架构图都可以作一定的映射。
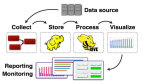
何谓五横,基本还是根据数据的流向自底向上划分五层,跟传统的数据仓库其实很类似,数据类的系统,概念上还是相通的,分别为数据采集层、数据处理层、数据分析层、数据访问层及应用层。
同时,大数据平台架构跟传统数据仓库有一个不同,就是同一层次,为了满足不同的场景,会采用更多的技术组件,体现百花齐放的特点,这是一个难点。
数据采集层:既包括传统的ETL离线采集、也有实时采集、互联网爬虫解析等等。
数据处理层:根据数据处理场景要求不同,可以划分为HADOOP、MPP、流处理等等。
数据分析层:主要包含了分析引擎,比如数据挖掘、机器学习、 深度学习等。
数据访问层:主要是实现读写分离,将偏向应用的查询等能力与计算能力剥离,包括实时查询、多维查询、常规查询等应用场景。
数据应用层:根据企业的特点不同划分不同类别的应用,比如针对运营商,对内有精准营销、客服投诉、基站分析等,对外有基于位置的客流、基于标签的广告应用等等。
数据管理层:这是一纵,主要是实现数据的管理和运维,它横跨多层,实现统一管理。
1、数据采集层,这是基础。
离线批量采集,采用的是HADOOP,这个已经成为当前流线采集的主流引擎了,基于这个平台,需要部署数据采集应用或工具。
诸如BAT都是自己研发的产品,一般企业,可以采用商用版本,现在这类选择很多,比如华为BDI等等,很多企业技术实力有,但起步的时候往往对于应用场景的理解比较弱,细节做工很差,导致做出来的产品难以达到要求,比如缺乏统计功能等,跟BAT差距很大,传统企业去采购这类产品,要谨慎小心。
一个建议是,当采购产品的时候,除了技术先进性和指标外,更多的应该问问是版本啥时候上线的,是否在哪里成功部署,是否有足够多的客户,如果能做个测试就更好,否则,你就是小白鼠哦,这个坑踩了不少。
能做和做成产品是两个境界的事情,小的互联网企业当然也能做出对于自己好用的采集工具,但它很难抽象并打造出一个真正的产品,BAT自研其实形成了巨大的优势。
实时采集现在也成了大数据平台的标配,估计主流就是FLUME+KAFKA,然后结合流处理+内存数据库吧,这个技术肯定靠谱,但这类开源的东西好是好,但一旦出现问题往往解决周期往往比较长。
除了用FLUME,针对ORACLE数据库的表为了实现实时采集,也可以采用OGG/DSG等技术实现实时的日志采集,可以解决传统数据仓库抽全量表的负荷问题。
爬虫当前也逐渐成为很多企业的采集标配,因为互联网新增数据主要靠它,可以通过网页的解析获取大量的上网信息,什么舆情分析、网站排名啥的,建议每个企业都应该建立企业级的爬虫中心,如果它未在你的大数据平台规划内,可以考虑一下,能拿的数据都不拿,就没什么好说了。
企业级的爬虫中心的建设难度蛮大,因为不仅仅是需要爬虫,还需要建立网址和应用知识库,需要基于网页文本进行中文分词,倒排序及文本挖掘等,这一套下来,挑战很大,当前已经有不少开源组件了,比如solr、lucent、Nutch、ES等等,但要用好它,路漫漫其修远兮。
还有一个就是,如果有可能,笔者建议将数据采集平台升级为数据交换平台,因为其实企业内有大量的数据流动,不仅仅是单向的数据采集,而且有很多数据交换,比如需要从ORACLE倒数据到GBASE,从HBASE倒数据到ASTER等等,对于应用来讲,这个价值很大。
既然数据采集和数据交换有很多功能非常类似,为什么不做整合呢?也便于统一管理,感觉企业的数据交换大量都是应用驱动,接口管理乱七八糟,这也是我的一个建议。
总得来讲,建设大数据采集平台非常不易,从客户的角度讲,至少要达到以下三个要求:
多样化数据采集能力:支持对表、文件、消息等多种数据的实时增量数据采集(使用flume、消息队列、OGG等技术)和批量数据分布式采集等能力(SQOOP、FTP VOER HDFS),比基于传统ETL性能有量级上的提升,这是根本。
可视化快速配置能力:提供图形化的开发和维护界面,支持图形化拖拽式开发,免代码编写,降低采集难度,每配置一个数据接口耗时很短,以降低人工成本。
统一调度管控能力:实现采集任务的统一调度,可支持Hadoop的多种技术组件(如 MapReduce、Spark 、HIVE)、关系型数据库存储过程、 shell脚本等,支持多种调度策略(时间/接口通知/手工)。
2、数据处理层,现在有个词叫混搭,的确是这样。
Hadoop的HIVE是传统数据仓库的一种分布式替代。应用在传统ETL中的数据的清洗、过滤、转化及直接汇总等场景很适合,数据量越大,它的性价比越高。但目前为止看,其支撑的数据分析场景也是有限的, 简单的离线的海量分析计算是它所擅长的,相对应的,复杂的关联交叉运算其速度很慢。
一定程度讲,比如企业客户统一视图宽表用HIVE做比较低效,因为涉及到多方数据的整合,但不是不可以做,最多慢点嘛,还是要讲究个平衡。
hadoop到了X000台集群的规模也撑不住了,当前很多企业的数据量应该会超过这个数量,除了像阿里等自身有研发能力的企业(比如ODPS),是否也要走向按照业务拆分Hadoop集群的道路?诸如浙江移动已经拆分了固网、移网、创新等多个hadoop集群。
Hadoop的SPARK的很适合机器学习的迭代,但能否大规模的应用于数据关联分析,能否一定程度替代MPP,还需要实践来验证。
MPP应该来说,是采用分布式架构对于传统数据仓库最好的替代,毕竟其实际上是变了种的关系型数据库,对于SQL提供完整支持,在HIVE做了转化分析后,数据仓库的融合建模用它来做性能绰绰有余,其性价比较传统DB2更好一点,比如经过实用,Gbase30-40台集群就能超过2台顶配的IBM 780。
MPP现在产品很多,很难做优劣判断,但一些实践结果可以说下,GBASE不错,公司很多系统已经在上面跑了,主要还是国产的,技术服务保障相对靠谱,ASTER还有待观望,自带一些算法库是有其一些优势,GreenPlum、Vertica没用过,不好说。
现在有个说法是MPP最终也要被Hadoop那套框架替代,毕竟诸如SPARK啥的都在逐步稳定和成熟,但在短期内,我觉得还是很靠谱的,如果数据仓库要采用渐进的演化方式,MPP的确是很好的选择。
现在诸如中国移动,eBAY等大量公司都在采用这类混搭结构,以适应不同的应用场景,显然是一种自然的选择。
大数据平台的三驾马车,少不了流处理。
对于很多企业来讲,其显然是核武器般的存在,大量的应用场景需要它,因此务必要进行建设,比如在IOE时代不可想象的实时、准实时数据仓库场景,在流处理那里就变得很简单了,以前统计个实时指标,也是很痛苦的事情,当前比如反欺诈实时系统,一天系统就申请部署好了。
只尝试过STORM和IBM STREAM,推荐IBM STREAM,虽然是商业版本,但其处理能力超过STORM不是一点半点,据说STORM也基本不更新了,但其实数据量不大,用啥都可以,从应用的角度讲,诸如IBM这种商业版本,是不错的选择,支撑各类实时应用场景绰绰有余。
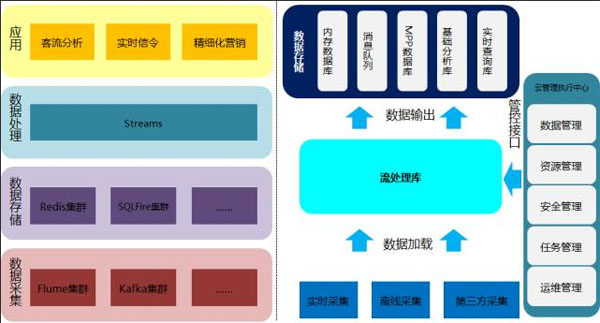
流处理集群以流处理技术结合内存数据库,用以实时及准实时数据处理,基于IBM Streams流处理集群承载公司的实时业务:
3、数据分析层,与时俱进吧。
先谈谈语言,R和Python是当前数据挖掘开源领域的一对基友,如果要说取舍,笔者真说不出来,感觉Python更偏向工程一点,比如有对分词啥的直接支撑,R的绘图能力异常强大。但他们原来都以样本统计为主,因此大规模数据的支撑有限。
笔者还是更关注分布式挖掘环境,SPARK是一种选择,建议可以采用SPARK+scala,毕竟SPARK是用scala写的,对很多原生的特性能够快速支持。
TD的MPP数据库ASTER也内嵌了很多算法,应该基于并行架构做了很多优化,似乎也是一种选择,以前做过几度交往圈,速度的确很快,但使用资料屈指可数,还需要老外的支持。
传统的数据挖掘工具也不甘人后,SPSS现在有IBM SPSS Analytic Server,加强了对于大数据hadoop的支撑,业务人员使用反馈还是不错的。
也许未来机器学习也会形成高低搭配,高端用户用spark,低端用户用SPSS,也是要适应不同的应用场景。
深度学习现在渐成潮流,TensorFlow是个选择,公司当前也部署了一套,希望有机会使用,往人工智能方向演进是大势所趋。
无论如何,工具仅仅是工具,最终靠的还是建模工程师驾驭能力。
4、数据开放层,也处在一个战国时代。
有些工程师直接将HIVE作为查询输出,虽然不合理,也体现出计算和查询对于技术能力要求完全不同,即使是查询领域,也需要根据不同的场景,选择不同的技术。
HBASE很好用,基于列存储,查询速度毫秒级,对于一般的百亿级的记录查询那也是能力杠杠的,具有一定的高可用性,我们生产上的详单查询、指标库查询都是很好的应用场景。但读取数据方面只支持通过key或者key范围读取,因此要设计好rowkey。
Redis是K-V数据库,读写速度比HBASE更快,大多时候,HBASE能做的,Redis也能做,但Redis是基于内存的,主要用在key-value 的内存缓存,有丢失数据的可能,当前标签实时查询会用到它,合作过的互联网或广告公司大多采用该技术,但如果数据越来越大,那么,HBASE估计就是唯一的选择了?
另外已经基于IMPALA提供互联网日志的实时在线查询应用,也在尝试在营销平台采用SQLFire和GemFire实现分布式的基于内存的SQL关联分析,虽然速度可以,但也是BUG多多,引入和改造的代价较大。
Kylin当前算是基于hadoop/SPARK的多维分析的杀手级工具,应用的场景非常多,希望有机会使用。
5、数据应用层,百花齐放吧。
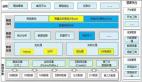
每个企业应根据自己的实际规划自己的应用,其实搞应用蓝图很难,大数据架构越上层越不稳定,因为变化太快,以下是运营商对外变现当前阶段还算通用的一张应用规划图,供参考:

6、数据管理层,路漫漫其修远兮
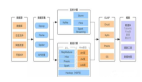
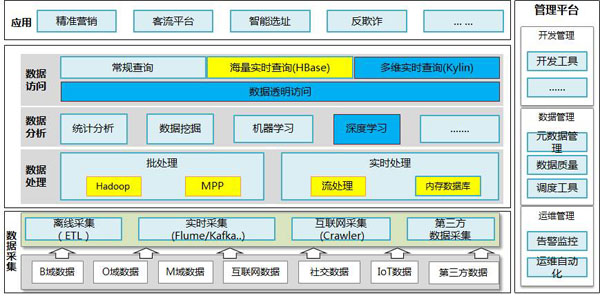
大数据平台的管理有应用管理和系统管理之分,从应用的角度讲,比如我们建立了DACP的可视化管理平台,其能适配11大搭数据技术组件,可以实现对各类技术组件的透明访问能力,同时通过该平台实现从数据设计、开发到数据销毁的全生命周期管理,并把标准、质量规则和安全策略固化在平台上,实现从事前管理、事中控制和事后稽核、审计的全方位质量管理和安全管理。
其它诸如调度管理、元数据管理、质量管理当然不在话下,因为管住了开发的源头,数据管理的复杂度会大幅降低。
从系统管理的角度看,公司将大数据平台纳入统一的云管理平台管理(私有云),云管理平台包括支持一键部署、增量部署的可视化运维工具、面向多租户的计算资源管控体系(多租户管理、安全管理、资源管理、负载管理、配额管理以及计量管理)和完善的用户权限管理体系,提供企业级的大数据平台运维管理能力支撑,当然这么宏大的目标要实现也非一日之功。
总结下大数据平台的一些革命性价值。
大数据时代,大多数企业的架构必然向着分布式、可扩展及多元化发展,所谓合久必分,不再有一种技术能包打天下了, 这冲击着传统企业集中化的技术外包模式,挑战是巨大的。

大数据及云计算时代,面多这么多技术组件,要采用一项新的技术,机遇和风险共存:
对于大数据平台的商业版本,企业面对的是合作伙伴的服务跟不上,因为发展太快,对于开源版本,企业面临的是自身运维能力和技术能力的挑战,对于自主能力实际要求更高。
当前BAT、华为、新型互联网等企业在风卷残云般的席卷人才, 对于诸如运营商等大型企业的人才挑战是巨大的,但同时也蕴含着机会, 事实上,对于致力于搞大数据的人来讲,来运营商等企业搞也是不错的选择,因为一方面企业在转型,另一方面数据量够大,技术主导的机会更多。